Материал: Автоматизація ведення бази даних індивідуальних програм реабілітації інвалідів
Іншим плюсом є резервне копіювання на льоту. Для резервного копіювання немає потреби зупиняти сервер. Процес резервного копіювання зберігає стан бази даних на момент свого старту, не заважаючи при цьому роботі з базою. Крім того, існує можливість створювати інкрементні резервні копії БД.
Також важливим моментом є тригери. Для кожної таблиці можливе призначення кількох тригерів, що спрацьовують до або після вставки, оновлення та видалення записів. Для тригерів використовується мова PSQL, дозволяючи вносити початкові значення, перевіряти цілісність даних, викликати виключення, і так далі. В Firebird 1.5 з'явилися універсальні тригери, які дозволяють в одному тригері обробляти вставки, оновлення та видалення записів таблиці.
Зовнішні функції бібліотеки з UDF (User Defined Function) можуть бути написані будь-якою мовою і легко підключені до сервера у вигляді DLL/SO, дозволяючи розширювати можливості сервера "зсередини".
Декларативний опис посилальної цілісності забезпечує несуперечність і цілісність багаторівневих відносин "master-detail" між таблицями.підтримує безліч міжнародних наборів символів (включаючи Unicode) з безліччю варіантів сортування.
Також у цьому розділі треба згадати і про такий інструмент як SQL. SQL (Structured query language) - декларативна мова програмування для взаємодії користувача з базами даних, що застосовується для формування запитів, оновлення і керування реляційними БД, створення схеми бази даних і її модифікації, системи контролю за доступом до бази даних. Сам по собі SQL не є ні системою керування базами даних, ні окремим програмним продуктом. Не бувши мовою програмування в тому розумінні, як C або Pascal, SQL може формувати інтерактивні запити або, бувши вбудованою в прикладні програми, виступати в якості інструкцій для керування даними. Стандарт SQL, крім того, вміщує функції для визначення зміни, перевірки і захисту даних.- це діалогова мова програмування для здійснення запиту і внесення змін до бази даних, а також управління базами даних. Багато баз даних підтримує SQL з розширеннями до стандартної мови. Ядро SQL формує командна мова, яка дозволяє здійснювати пошук, вставку, оновлення, і вилучення даних, використовуючи систему управління і адміністративні функції. SQL також включає CLI (Call Level Interface) для доступу і управління базами даних дистанційно.
Перша версія SQL була розроблена на початку 1970-х років у IBM. Ця версія мала назву SEQUEL і була призначена для обробки й пошуку даних, що містилися в реляційній базі даних IBM, System R . Мова SQL пізніше була стандартизована Американськими Держстандартами (ANSI) в 1986. Спочатку SQL розроблялась як мова запитів і управління даними, пізніші модифікації SQL створено продавцями систем управління базами даних, які додали процедурні конструкції, control-of-flowкоманд і розширення мов.призначений для виконання запитів. Крім того, в SQL входить синтаксис для оновлення, вставки і знищення даних. Цей синтаксис разом з командами поновлення формує мова управління даними (DML):
- SELECT - отримує дані з таблиці БД;
- UPDATE - оновлює дані в таблиці БД;
- DELETE - знищує дані в таблиці БД;
- INSERT INTO - вставляє нові дані в таблицю БД.є частиною SQL, яка управляє створенням і видаленням таблиць в БД, крім того, за допомогою DDL ми можемо призначати індекси (ключові слова), налагоджувати взаємозв'язки між таблицями і накладати обмеження на таблиці БД [5].
Найважливішими командами DDL є наступні команди:
- CREATE TABLE - створення нової таблиці;
- ALTER TABLE - зміна існуючої таблиці;
- DROP TABLE - видалення таблиці;
- CREATE INDEX - створення індексу (ключового слова для полегшення пошуку);
- DROP INDEX - видалення індексу.
2.3
Розробка баз даних за допомогою Firebird 2.5
інтерфейс редагування інформація база
Процес розробки бази даних складається з таких кроків:
- визначення мети створення бази даних;
- пошук і впорядкування потрібних відомостей;
- розділення даних на таблиці;
- перетворення елементів даних на стовпці;
- визначення первинних ключів;
- створення зв'язків між таблицями;
- удосконалення структури;
- застосування правил нормалізації .
Угрупування одних і тих же даних в таблиці може проводитися різними способами. Атрибути і відносини повинні групуватися за реляційними принципами, тобто має повністю мінімізуватися дублювання даних, а також спрощуватися процедура їх обробки з подальшим оновленням. Одним з першорядних завдань при проектуванні баз даних виступає усунення надмірності, а воно досягається за допомогою нормалізації.
Нормалізація баз даних являє собою формальний апарат обмежень на створення таблиць, що дозволяє усунути дублювання, з обов’язковим забезпеченням несуперечності інформації, що зберігається, зменшуючи трудовитрати, пов’язані з веденням та обслуговуванням бази даних. Операція нормалізації полягає в розкладанні вихідних таблиць бази даних на більш прості.
На кожному ступені даного процесу таблиці обов’язково приводяться до нормальних форм. Кожна ступінь нормалізації характеризується певним набором обмежень, яким і повинні відповідати всі таблиці. Таким чином, здійснюється видалення з таблиць неключової інформації, яка є надлишковою.
Нормалізація баз даних ґрунтується на понятті функціональної залежності між атрибутами. Прийнято вважати, що один атрибут залежить від іншого, якщо в кожен момент часу певному значенню другого атрибута відповідає трохи більше, ніж одне значення першого.
Нормалізація баз даних - це загальне поняття, однак, його прийнято поділяти на кілька нормальних форм, про які й буде сказано далі.
Будь-який інформаційний об’єкт вважається відповідним першій нормальній формі, коли значення кожного його атрибута є єдиним. Якщо у якогось атрибуту є повторюване значення, то не можна вважати, що об’єкт належить першій нормальній формі. Виходить, що можна створити ще одну сутність, тобто інформаційний об’єкт.
Прийнято вважати, що інформаційний об’єкт належить до другої нормальної формі, коли він вже перебуває в першій нормальній формі і кожен з його атрибутів, який не перебуває в потенційному ключі, повністю залежить, у функціональному плані, від кожного з потенційних ключів.
Прийнято вважати, що інформаційний об’єкт належить до третьої нормальної форми, якщо він вже перебуває в другій нормальній формі і в ньому не присутня жодна з транзитивних залежностей неключових об’єктів від ключів. Під транзитивною залежністю прийнято розуміти очевидну залежність між полями.
Нормалізація бази даних ставить перед розробником основну мету, яка полягає в приведенні всіх відносин до третьої нормальної форми. Тільки так у подальшому можна буде створити ефективну інформаційну систему.
Варто сформулювати набір правил, яких
слід притримуватися в роботі з нормалізації. У першу чергу варто виключати
повторювані групи. Необхідно формувати окрему таблицю, що зберігає кожен набір
пов’язаних атрибутів, в якій і створити окремий ключ. Далі обов’язково
виключити надлишкові дані. У випадках, коли залежність атрибуту спостерігається
тільки від частини ключа, то його необхідно виставити в окрему таблицю. Третє
правило полягає в обов’язковому виключенні стовпців, що не залежать від ключа.
Атрибути слід помістити в ізольовану таблицю, якщо вони не роблять належного
впливу на ключ. Обов’язково слід ізолювати незалежні множинні відносини. У
даному випадку мова йде про те, що між кількома відносинами не проглядається
конкретний зв’язок. І нарешті, варто ізолювати множинні відносини, пов’язані
семантично. На цьому нормалізація БД завершується, після чого настає процес
розробки.
2.4 Компоненти роботи з базами
даних
Для роботи з базою даних доцільно обрати такі компоненти призначені для роботи з базами даних, як TIBdatabase, TIBTransaction, TDataSource, TIBTable та TIBQuery. При проектуванні програми для підключення бази даних доцільно встановити такі параметри для компонентів.
Для TIBdatabase1 властивість DatabaseName у вказати шлях до бази даних, властивість Connected встановити у True. Для TIBTransaction1 властивість Active у True. Для TDataSource3 властивість Dataset у IBQuery3. Для TIBQuery3 властивість Database у TIBdatabase1, Властивість SQL [6] залежно від потреб заповнити запитом мовою SQL, а властивість Active встановити у True.
Таким чином може бути спроектована та підключена база даних для початку проектування програми.
3
СПЕЦІАЛЬНА ЧАСТИНА
3.1 Програмна частина
3.1.1 Проектування бази даних та інтерфейсу програми
Для реалізації бази даних була обрана СУБД Firebird 2.5, в якій створено 24 таблиці.
Доцільно було поділити інформацію на різні таблиці, з яких 4 основні і 20 довідників. Схема взаємозв’язку таблиць представлена в додатку В.
Дані, що використовуються у таблиці багато разів, було доречно занести у так звані довідкові таблиці, що мають характерний префікс SPR_ у своїй назві, вони приведені на рисунках 3.1 - 3.20. Довідники, що поставляються заповненими:
- «Стать»;
- «Освіта»;
- «Групи інвалідності»;
- «Тип програми реабілітації»;
- «Види обмежень»;
- «Ступені обмежень»;
- «Заходи реабілітації»;
- «Реабілітаційний потенціал»;
- «Мета реабілітації».
Довідники, що можуть поповнюватися в ході виконання програми:
- «Діагнози»;
- «Супутні захворювання»;
- «Професії»;
- «Терміни проведення реабілітаційних заходів»;
- «Обсяг проведення реабілітаційних заходів»;
- «Місце проведення реабілітаційних заходів»;
- «Працівники закладу»;
- «Райони»;
- «Області»;
- «Населені пункти»;
- «Райони населеного пункту».
На рисунках позначка «ПК» позначає, що поле є первинним
ключем, позначка «ВК», що поле є зовнішнім ключем.

Рисунок 3.1 - Структура таблиці статі SPR_SEX

Рисунок 3.2 - Структура таблиці ступенів освіти SPR_OSVITA

Рисунок 3.3 - Структура таблиці груп інвалідності SPR_GR_INV

Рисунок 3.4 - Структура таблиці типів ІПР SPR_PROG_SKL

Рисунок 3.5 - Структура таблиці видів обмежень SPR_VID_OBMEJ

Рисунок 3.6 - Структура таблиці супутніх захворювань SPR_STUP

Рисунок 3.7 - Структура таблиці реабілітаційних заходів
SPR_ZAH

Рисунок 3.8 - Структура таблиці реабілітаційних потенціалів
SPR_R_POTENCIAL

Рисунок 3.9 - Структура таблиці цілей реабілітації SPR_META

Рисунок 3.10 - Структура таблиці діагнозів SPR_DIAGNOZ

Рисунок 3.11 - Структура таблиці супутніх захворювань SPR_MKH

Рисунок 3.12 - Структура таблиці професій SPR_PROF

Рисунок 3.13 - Структура таблиці термінів реабілітації
SPR_TERMIN

Рисунок 3.14 - Структура таблиці обсягів реабілітацій
SPR_OBSYAG

Рисунок 3.15 - Структура таблиці місць реабілітації SPR_MISC

Рисунок 3.16 - Структура таблиці працівників МСЕК
SPR_SOTRUDNIKI

Рисунок 3.17 - Структура таблиці районів області
SPR_RAJON_OBL
![]()
Рисунок 3.18 - Структура таблиці областей SPR_OBL

Рисунок 3.19 - Структура таблиці населених пунктів
SPR_NAS_PUNKT

Рисунок 3.20 - Структура таблиці районів населеного пункту
SPR_RAJON
Таблиця «Особиста картка пацієнта» містить такі поля
- ID_CHEL -- унікальний ідентифікатор;
- FIO - ПІБ;
- DR - дата народження;
- SEX - стать;
- OBL - область;
- R_OBL - район області;
- PUNKT - населений пункт;
- R_PUNKT - район населеного пункту;
- INDEX1 - поштовий індекс;
- STREET - вулиця;
- TEL - номер телефону;
- OSVITA - освіта;
- GR_INV - група інвалідності;
- ID_PROF - професія;
- WORK - ким працює.
Таблиця «Обмеження» містить такі поля
- ID_IPR - ідентифікатор ІПР, до якої відноситься обмеження;
- ID_VID_OBMEJ - ідентифікатор виду обмеження, до якого відноситься запис;
- ID_STUP - ідентифікатор ступеню, до якого відноситься дане обмеження.
Таблиця «ІПР» містить такі поля:
- ID_IPR - унікальний ідентифікатор ІПР;
- ID_CHEL - ідентифікатор пацієнта, для якого складена дана програма;
- N_PROG - номер програми реабілітації;
- DAT_ZAP - дата заповнення ІПР;
- MSEK_N - назва та номер МСЕК;
- ID_PROG_SKL - програма складена;
- TRIV_INV - тривалість перебування на інвалідності;
- ID_DIAGNOZ - діагноз;
- SUPUT_ZAHV - супутні захворювання;
- ID_R_POTENCIAL - реабілітаційний потенціал;
- META - мета реабілітації;
- DAT_SPIVB - Дата проведення співбесіди;
- DAT_KONTR - Дата контролю за виконанням ІПР;
- SOTRUDNIK - Працівник, що уклав ІПР.
Таблиця «Реабілітація» містить такі поля
- ID_IPR - ідентифікатор ІПР, до якої відносяться реабілітаційні заходи;
- ID_ZAH - реабілітаційний захід;
- ID_TERMIN - термін виконання реабілітації;
- ID_OBSYAG - обсяг виконання реабілітації;
- ID_MISCE - місце виконання реабілітації.
Схема зв`язку таблиць приведена у додатку В.
Таким чином ми маємо таблицю, що містить перелік персональних
даних про осіб-інвалідів OS_KARTA, що зображено на рисунку 3.21, дані про
обмеження життєдіяльності містяться у таблиці OBMEJ, що зображено на рисунку
3.22, дані про індивідуальну програму реабілітації зображено у таблиці IPR, що
відображено на рисунку 3.23 та дані про реабілітаційні заходи містяться у
таблиці REABIL, що відображено на рисунку 3.24.
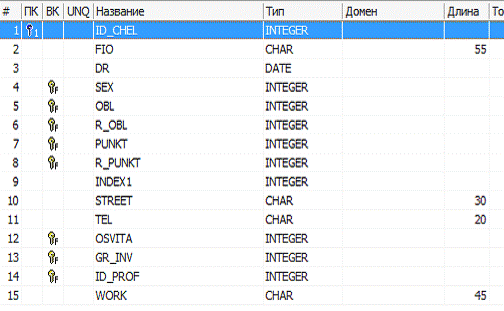
Рисунок 3.21- Структура таблиці OS_KARTA
