Материал: 582
Этот список не носит исчерпывающего характера и может дополняться. Рассмотренная ниже методика позволяет работать с неограниченно большим набором показателей.
Отбор показателей для вероятностно-графовой модели
Далее необходимо выяснить, какую совокупность факторов учитывать в качестве фоновых для оценки каждого из 7 показателей, характеризующих состояние преступности Y1 – Y7.
Метод построения корреляционной матрицы для определения пар показателей, обладающих наибольшей статистической взаимозависимостью, не дал никаких значимых результатов. Таблица корреляционных коэффициентов приведена в приложении 1.
Полученные коэффициенты варьируются от –0,53 до 0,43, в основной своей массе, не превышая 0,3 по модулю. Это не позволяет отобрать в достаточном количестве социально-экономические показатели, оказывающие существенное влияние на состояние преступности (табл. 3). Заметим, что речь здесь идет о линейной статистической взаимозависимости. Однако проведенное выше огрубление данных путем введения категорий значений, основанных на стандартных отклонениях по каждому показателю, позволяет применить методы установления непараметрических взаимозависимостей между парами этих показателей, т. е. ответить на вопрос, например, имеется ли у наблюдений, относящихся к определенным категориям по показателю X1, неслучайная склонность относиться также и к определенным категориям по показателю Y1, достаточно ли выражена данная склонность или она находится в пределах допустимой ошибки.
Одним из инструментов, позволяющих выявлять непараметрические взаимозависимости, является хи-квадрат Пирсона.
Хи-квадрат Пирсона служит для определения взаимозависимостей между показателями, заданными качественными или порядковыми переменными.
Поэтому для дальнейшего исследования показателей все данные были нормализованы и переведены из интервальных шкал в порядковые, заданные в значениях стандартного отклонения. Всего 6 порядков:
1 категория: ниже –2δ;
2 категория: от –2δ до –1δ;
3 категория: от –1δ до 0δ;
76
|
экономике» |
Итого: |
0 81 |
7 286 |
12 188 |
3 61 |
0 32 |
22 648 |
|
6 |
|||||||
|
«Долязанятых в |
4 5 |
18 2 |
129 4 |
106 17 |
27 7 |
13 3 |
293 33 |
|
поX |
3 |
28 |
130 |
53 |
19 |
13 |
243 |
|
1 |
|
|
|
|
|
|
|
Xи |
Категория |
2 |
17 |
15 |
0 |
5 |
3 |
40 |
1 |
|
|
|
|
|
|
|
|
Y |
|
1 |
16 |
1 |
0 |
0 |
0 |
17 |
1 |
|
|
|
|
|
|
|
|
наблюдений по показателям |
Эмпирическиеданные |
«Количествовыявленных несовершеннопреступленияна 10 тыс. населения» |
2 |
3 |
4 |
5 |
6 |
Итого: |
3.ТаблицаТаблицараспределения |
Категорияпо Y летних,совершивших |
|||||||
|
|
1 |
|
|
|
|
|
|
4 категория: от 0δ до 1δ;
5 категория: от 1δ до 2δ;
6 категория: свыше 2δ. Далее рассмотрим методику
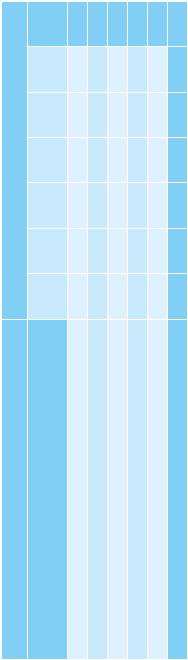
расчета в MS Excel критерия хиквадрат на примере все той же пары показателей X1 «Доля занятых в экономике» и Y1 «Количество выявленных несовершеннолетних, совершивших преступления на 10 тыс. населения».
В каждой ячейке содержится значение mij, отражающее количество наблюдений, относящихся одновременно к категории i по показателю X1 и к категории j по показателю Y1. Например, наблюдений из категории i = 1 по X1 и из категории j = 2 по Y1 оказалось 16, а из категории i = 3 по X1 и категории j = 3 по Y1 больше всего – 130.
Для построения подобной таблицы распределений в MS Excel служит инструмент «Сводная таблица».
Теперь предположим, что показатели X1 и Y1 не обладают никакой взаимозависимостью. В этом случае распределение наблюдений по каждой из категорий вычисляется как
|
| X(i) | × |
| Y ( j) | |
|
1 |
1 |
|
|
mij = |
|
|
, |
N |
|
||
|
|
|
где | X1(i) | – количество наблюдений, относящихся к категории i по показателю X1;
|Y1( j ) | – количество наблюдений, относящихся к категории j по показателю Y1;
77
N – общее количество наблюдений.
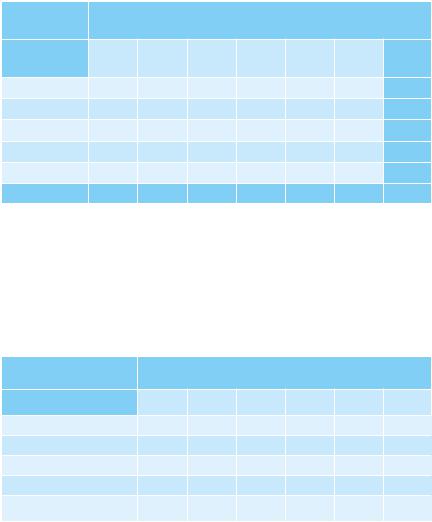
Так, например, для наблюдений, относящихся к категории X1(2) и Y1(1) , их теоретическое количество составит 81 × 17 / 648 = 2,125.
Построим таблицу теоретических данных, которые показывают, какое количество наблюдений было бы в каждой из категорий при полной независимости показателей.
Таблица 4
Теоретиче- |
|
|
Категория по X1 |
|
|
|||
ские данные |
|
|
|
|
||||
Категория |
1 |
2 |
3 |
4 |
5 |
6 |
Итого: |
|
по Y1 |
||||||||
|
|
|
|
|
|
|
||
2 |
2,13 |
5,00 |
30,38 |
36,63 |
4,13 |
2,75 |
81 |
|
3 |
7,50 |
17,65 |
107,25 |
129,32 |
14,56 |
9,71 |
286 |
|
4 |
4,93 |
11,60 |
70,50 |
85,01 |
9,57 |
6,38 |
188 |
|
5 |
1,60 |
3,77 |
22,88 |
27,58 |
3,11 |
2,07 |
61 |
|
6 |
0,84 |
1,98 |
12,00 |
14,47 |
1,63 |
1,09 |
32 |
|
Итого: |
17 |
40 |
243 |
293 |
33 |
22 |
648 |
|
Далее необходимо рассчитать значения хи-квадрат для каждой категории:
|
|
|
|
2 |
|
|
|
|
(mij −mij ) |
|
|
|
|
||
|
χij = |
|
|
. |
|
|
|
|
|
mij |
|
|
|
|
|
Таблица 5 |
|
|
|
|
|
|
|
|
|
Категория по X1 |
|
|
|||
χij |
|
|
|
||||
Категория по Y1 |
1 |
2 |
|
3 |
4 |
5 |
6 |
2 |
90,60 |
28,80 |
0,19 |
9,47 |
1,09 |
2,75 |
|
3 |
5,64 |
0,40 |
4,83 |
0,00 |
7,66 |
0,76 |
|
4 |
4,93 |
11,60 |
4,34 |
5,18 |
5,76 |
4,94 |
|
5 |
1,60 |
0,40 |
0,66 |
0,01 |
4,88 |
0,42 |
|
6 |
0,84 |
0,53 |
0,08 |
0,15 |
1,15 |
1,09 |
|
78
Расчетное значение критерия хи-квадрат χ равняется сумме
всех полученных частных χij :
∑∑
χ = χij .
ij
В данном случае 200,76.
χ =
Полученное значение необходимо сравнить с табличным значением χ, которое не зависит от конкретных данных, а зависит от количества категорий по первому показателю, по второму и от уровня допустимой ошибки, который здесь примем за 0,05 (или 5 %). В MS Excel табличное значение χможно получить при помощи функции =ХИ2ОБР(). Аргументов этой функции два: 1) уровень допустимой ошибки; 2) число степеней свободы, вычисляемое как количество категорий по X1 минус единица, умноженное на количество категорий по Y1 минус единица, т. е. (|X1|–1) × (|Y1|–1). В рассматриваемом примере число степеней свободы равняется (5–1) × (6–1) = 20.
Для данного примера χ = 31,41.
В случае, если расчетное значение хи-квадрат больше чем табличное, можно сделать вывод о наличии непараметрической взаимозависимости между парой показателей. В случае же, если рас-
четное значение хи-квадрат меньше чем табличное, такого вывода |
|
сделать нельзя. |
|
|
|
В рассматриваемом примере χ > χ(200,76 >31,41), т. е., между |
|
показателями X1 «Доля занятых в экономике» и Y1 «Количество |
|
выявленных несовершеннолетних, совершивших преступления на 10 тыс. населения», взаимозависимость имеется.
Таблицы χ и χ приведены в приложении 2.
Как видно из таблиц 4 и 5, практически для каждой пары показателей расчетное значение превышает табличное, что свидетельствует о наличии взаимозависимости. Суммарно, в наибольшей степени на показатели преступности оказывают влияние социаль- но-экономические показатели X1, Х13, Х14, Х19. В наибольшей степени подвержены влиянию со стороны социально-экономических показателей показатели преступности: Y2, Y4, Y5.
Продолжая рассматривать пример с показателем Y1 «Количество выявленных несовершеннолетних, совершивших преступления на 10 тыс. населения», предложим достаточно строгий критерий отбора социально-экономических показателей, оказывающих на него влияние. Отберем те из X, для которых расчетное χ превышает табличное значение не менее чем в 5 раз χ / χ ≥5 .
79
В результате получим 7 показателей, которые обладают наиболее выраженной взаимозависимостью с Y1:
X1: доля занятых в экономике;
X8: объем отгруженных товаров собственного производства, выполненных работ и услуг собственными силами по видам экономической деятельности, млн руб.: обрабатывающие производства на 1 тыс. населения;
X9: продукция сельского хозяйства – всего, млн руб. на 1 тыс. населения;
X13: доля мужчин в трудоспособном возрасте;
X14: доля мужчин старше трудоспособного возраста; X15: доля мужчин в возрасте от 15 до 19 лет;
X19: доля городского населения.
Вероятностно-графовая модель преступности
иусловные распределения вероятностей
Воснове рассматриваемого далее метода лежат частотные распределения наблюдений того или иного уровня показателя. Например, на диаграмме (рис.1) приведено частотное распределение значений для показателя X1 «Доля занятых в экономике».
50% |
|
|
|
|
45,2% |
|
|
|
|
|
|
|
|
||
45% |
|
|
|
|
|
|
|
|
|
|
37,5% |
|
|
|
|
|
|
|
|
|
|
||
40% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
35% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
25% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10% |
|
2,6% |
6,2% |
|
|
5,1% |
3,4% |
|
|
|
|||||
5% |
|
|
|
|
|||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
0% |
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
Рис.1. Диаграмма распределения вероятностей для показателя Х1 «Доля занятых в экономике»
Для каждого показателя стандартное отклонение рассчитывается отдельно, затем проводится нормировка значений показателя
80