Материал: 4554
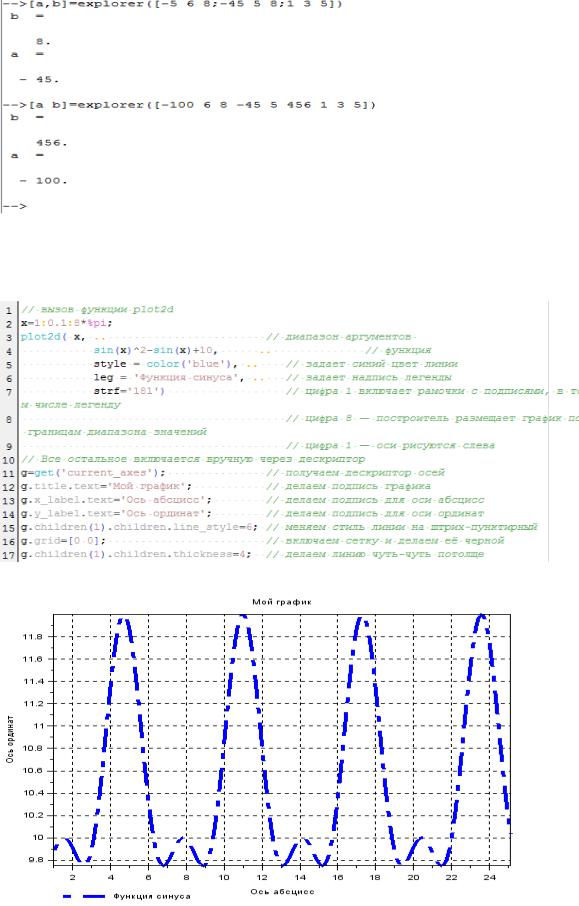
16
Результаты вызовов функции с различными данными
Пакет Scilab также позволяет строить графики функций. В качестве примера приведѐм скрипт для построения двумерного графика функции
sin2 (x) sin(x) 10
Результат выполнения:
17
Окно графика является интерактивным, можно приближать и отдалять график, меняя его масштаб, при помощи колеса мыши.
Порядок выполнения работы
1.В командной строке произвести присвоение целой переменной. Над этой переменной выполнить действия: сложение, умножение, возведение в степень.
2.В командной строке задать две матрицы размером 3х3. Над этими матрицами произвести следующие действия: транспонирование, сложение, поэлементное сложение, умножение, возведение в степень.
3.В редакторе Scinotes набрать функцию, выполняющую поиск корней квадратного уравнения. Коэффициенты определяются вариантом задания.
4.В редакторе Scinotes набрать функцию поиска минимального и максимального значения в массиве данных. Продемонстрировать работу функции на векторе и квадратной матрице произвольного размера с любыми вещественными числами.
5.Построить график функции, соответствующей квадратному уравнению согласно своему варианту задания.
6.Оформить отчѐт по лабораторной работе. Раздел «Выполнение работы» содержит:
текст варианта задания на лабораторную работу;
запись результатов действий согласно заданию (текст скриптов не включать).
Варианты заданий
Вариант |
|
Коэффициенты |
|
||
|
|
|
|
|
|
a |
|
b |
|
c |
|
|
|
|
|||
|
|
|
|
|
|
1 |
10 |
|
9 |
|
2,4 |
|
|
|
|
|
|
2 |
12,4 |
|
4,2 |
|
5,7 |
|
|
|
|
|
|
3 |
10,4 |
|
6,4 |
|
4 |
|
|
|
|
|
|
4 |
2,4 |
|
8 |
|
9 |
|
|
|
|
|
|
5 |
5,7 |
|
12 |
|
4,2 |
|
|
|
|
|
|
6 |
4 |
|
19,2 |
|
6,4 |
|
|
|
|
|
|
7 |
9 |
|
12 |
|
8 |
|
|
|
|
|
|
8 |
4,2 |
|
15,2 |
|
12 |
|
|
|
|
|
|
|
|
|
18 |
|
|
|
|
|
|
9 |
6,4 |
16 |
|
19,2 |
|
|
|
|
|
10 |
8 |
10 |
|
12 |
|
|
|
|
|
11 |
12 |
12,4 |
|
15,2 |
|
|
|
|
|
12 |
19,2 |
10,4 |
|
16 |
|
|
|
|
|
13 |
12 |
2,4 |
|
10 |
|
|
|
|
|
14 |
15,2 |
5,7 |
|
12,4 |
|
|
|
|
|
15 |
16 |
4 |
|
10,4 |
|
|
|
|
|
Контрольные вопросы
1.Что такое Scilab?
2.Для чего предназначен пакет Scilab?
3.Какие режимы выполнения расчѐтов существуют в Scilab, чем они отличаются?
4.Как задать переменную и матрицу в командной строке, какие действия с ними можно произвести?
5.Как создать скрипт в редакторе?
6.Как написать функцию в скрипте, как вызвать еѐ в командной строке?
7.Какие конструкции в Scilab организуют ветвление, каков их синтаксис?
8.Какие конструкции в Scilab организуют циклы, каков их синтаксис?
9.Как построить двумерный график, какие существуют параметры у этой функции?
19
Лабораторная работа № 2. Описательная статистика
Цель работы: получение навыков расчета в среде Scilab параметров центральной тенденции и вариации.
Теоретическая часть
Основным материалом при проведении исследований являются распределения переменных. Существуют способы численного описания этих переменных, наиболее часто используемыми являются измерение параметров центральной тенденции и вариации.
Параметры центральной тенденции: мода, медиана, среднее и взвешенное среднее.
Параметры вариации: размах, квартили, дисперсия, стандартное отклонение и коэффициент вариации.
Измерение центральной тенденции состоит в выборе одного числа, которое наилучшим образом описывает все значения признака из набора данных. Такое число называют центром набора данных, мерой центральной тенденции. Получив такое число, мы получаем информацию о распределении признака «в сжатой форме». При этом мы можем сравнивать при помощи этого числа два и более различных распределений.
Мода – наиболее часто встречающееся значение в выборке, наборе данных. В случае если данные сгруппированы и построено распределение частот, модой является значение, имеющее наибольшую частоту.
Моду будем обозначать Mo . Мода вполне пригодна для измерения центральной тенденции хотя бы потому, что это единственный способ описывать номинальное распределение не хуже порядкового или интервального. Ограничения в применении связаны с тем, что мода рассматривает лишь одну особенность распределения, а именно, расположение наиболее частого значения. Другие важные особенности, такие как число наблюдений выше или ниже моды, расстояние между модальными значениями и другие характеристики, остаются вне поля зрения.
Мода – значение во множестве наблюдений, которое встречается наиболее часто. (Мода = типичность.) Иногда в совокупности встречается более чем одна мода (например: 6, 2, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9). В этом случае можно сказать, что совокупность мультимодальна. Из структурных средних

20
величин только мода обладает таким уникальным свойством. Как правило, мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Среди перечисленных цветов автомобилей (белый, черный, синий металлик, белый, синий металлик, белый) мода будет равна белому цвету.
Медиана определяется как серединное значение выборки, или значение, выше и ниже которого располагается одинаковое число наблюдений. Для нахождения медианы обязательно упорядочить данные. Медиана является точной серединой выборки. Обозначается Me и определяется по-разному для выборок с четным и нечетным числом элементов. Для нечетного количества наблюдений медиана есть наблюдение с номером n 1 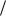 2 . Для четного количества наблюдений медиана вычисляется как среднее значение наблюдений с номерами n
2 . Для четного количества наблюдений медиана вычисляется как среднее значение наблюдений с номерами n 2 и n 2
2 и n 2  2 . В случае нечетного количества наблюдений медиана есть просто середина выборки, выше и ниже которой располагается одинаковое количество наблюдений.
2 . В случае нечетного количества наблюдений медиана есть просто середина выборки, выше и ниже которой располагается одинаковое количество наблюдений.
Среднее определяется как среднее арифметическое выборки, то есть как сумма всех значений выборки, деленная на ее объем. Следуя определению, будем находить среднее значение по формуле
x x n
где x – сумма всех значений выборки, n – объем выборки.
Взвешенное среднее – это среднее значение, получаемое при объединении нескольких групп наблюдений.
Если группы имеют одинаковый объем, то групповое среднее можно вычислить как среднее арифметическое имеющихся средних значений по каждой группе. Если же группы имеют различный объем, то групповое среднее можно найти по следующей формуле
X x n ,
N
где x n – сумма произведений средних в группе на количество элементов в этой группе, а N – общее число наблюдений.