Материал: 343
Рис. 1.3. Кумулята распределения по уровню преступности
Таблица 1.4
Количество несовершеннолетних, стоящих на профилактическом учете в территориальном органе внутренних дел
Название района |
Количество несовершеннолетних |
|
|
Качинский |
71 |
|
|
Рыбинский |
86 |
|
|
Уславский |
96 |
|
|
Николаевский |
101 |
|
|
Вощажниковский |
431 |
|
|
На примере данных таблицы 1.4 видно принципиальное различие между медианой и средней арифметической величиной. Медиана не зависит от значений признака на краях ранжированного ряда. Если бы даже количество несовершеннолетних в районе с наибольшим их числом стало бы вдруг вдвое больше имеющегося, величина медианы нисколько не изменилась бы. Поэтому часто медиану используют как более надежный показатель типичного значения признака, нежели средняя арифметическая, если ряд значений неоднороден, включает резкие отклонения от средней.
11
В данном ряду средняя величина количества несовершеннолетних, равная 157, сложилась под значительным влиянием наибольшего значения. Для 80 % рассмотренных в примере территориальных органов внутренних дел количество несовершеннолетних, стоящих на профилактическом учете в данном органе, меньше среднего, и лишь 20 % – больше. Вряд ли такую среднюю можно считать типичной величиной.
При четном числе единиц совокупности за медиану принимают арифметическую среднюю величину из двух центральных значений признака, например, при десяти значениях признака – среднюю из пятого и шестого значений в ранжированном ряду.
В интервальном вариационном ряду для нахождения медианы применяется формула:
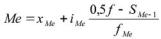 ,
,
где: Ме – медиана; хМе – начальное значение интервала, содержащего медиану;
iMe – величина медианного интервала; f – сумма частот ряда;
SMe – 1 – сумма накопленных частот, предшествующих медианному интервалу;
fMe – частота медианного интервала.
В таблице 1.3 медианным является среднее из 143 значений, т. е. семьдесят второе от начала ряда значение уровня преступности. Как видно из ряда накопленных частот, оно находится в четвертом интервале. Тогда, применяя приведенную выше формулу, получим Ме = 295 преступлений на 100 тыс. чел.
В дискретном вариационном ряду медианой следует считать значение признака в той группе, в которой накопленная частота превышает половину численности совокупности. Например, для данных таблицы 1.2 медианой числа задержанных разыскиваемых лиц за одну операцию по розыску будет 2.
Аналогично медиане вычисляются значения признака, делящие совокупность на четыре равные по числу единиц части. Эти величины называются квартилями и обозначаются заглавной латинской буквой Q с индексом – номером квартиля (Q1, Q2, Q3). Ясно, что Q2 совпадает с Me.
Значения признака, делящие ряд на пять равных частей, называют квинтилями, на десять частей – децилями, на сто частей – перцентилями.
12
Бесспорно, важное значение имеет такая величина признака, которая встречается в изучаемом ряду в совокупности чаще всего. Такую величину, как уже отмечалось выше, именуют модой и обозначают Мо. В дискретном ряду мода определяется без вычисления как значение признака с наибольшей частотой. Например, по данным таблицы 1.2 чаще всего (а именно 71 раз) в операции по задержанию лиц, объявленных в розыск, задерживалось по 2 лица, т. е. модой является число 2. Обычно встречаются ряды с одним модальным значением признака. Если два равных значения признака имеются в вариационном ряду, он считается, соответственно, бимодальным (если несколько – мультимодальным). Наличие в распределении более одной моды указывает на неоднородность совокупности, возможно, представляющей собой смесь нескольких разнородных совокупностей, соответственно с разными модами.
Следующим этапом изучения вариации признака в совокупности является измерение характеристик силы, величины вариации. Простейшей из таких характеристик служит размах (или амплитуда вариации, изменения) – абсолютная разность между максимальным и минимальным значениями признака изучаемого ряда (совокупности) значений. По сути, это величина диапазона имеющихся значений. Таким образом, размах вычисляется по формуле:
R = Хmax – Хmin.
Поскольку размах по своему определению измеряет максимальное различие значений признака, он не способен характеризовать, отражать закономерную силу его вариации во всей совокупности. Предназначенный для данной цели показатель должен учитывать и обобщать все различия значений признака в совокупности без исключения. Число таких различий велико. Так, для примера, описанного в таблице 1.3, оно составит 10 153 (это число рассчитывается как число сочетаний по два из всех единиц сово-
купности (C2143)).
Однако в этом примере нет необходимости рассматривать, вычислять и усреднять все отклонения. Проще использовать среднюю величину из величин отклонений отдельных значений признака от среднего арифметического значения признака (каковых 143). Но среднее отклонение значений признака от средней арифметической величины, согласно известному свойству последней, равно нулю. Поэтому показателем силы вариации выступает не алгебраическая средняя отклонений, а средний модуль (среднее абсолютное значение) отклонений:
13
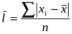 .
.
По данным таблицы 1.3 средний модуль, или среднее линейное отклонение, по абсолютной величине вычисляется как взвешенное по частоте отклонение по модулю середин интервалов от средней арифметической величины, т. е. по формуле:
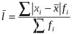 = 68,5 прест. на 100 тыс. чел.
= 68,5 прест. на 100 тыс. чел.
Это означает, что в среднем уровень преступности в изучаемой совокупности населенных пунктов отклонялся от уровня преступности по области на 68,5 преступлений на 100 тыс. чел. Простота самого расчета и осмысления такого расчета (простота интерпретации) представляют положительные стороны данного показателя. Однако модуль нельзя поставить в соответствие с каким-либо вероятностным законом (статистическим распределением), в том числе и с нормальным распределением, параметром которого является не средний модуль отклонений, а среднее квадратическое отклонение (в компьютерных программах это по-английски называется «the standard deviation», сокращенно «s. d.» или же просто «s», а порусски – СКО). В статистической литературе среднее квадратическое отклонение от средней величины принято обозначать малой (строчной) греческой буквой σ (читается «сигма»), если речь идет о теоретической величине, или же s (когда речь идет о приближенной оценке для σ).
Для ранжированного ряда:
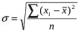 ,
,
для интервального ряда:
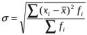 .
.
По данным таблицы 1.3 среднее квадратическое отклонение уровня преступности составило 84,4 преступления на 100 тыс. чел.
Среднее квадратическое отклонение по величине в реальных совокупностях всегда больше среднего модуля отклонений.
14
Квадрат среднего квадратического отклонения σ2 дает величину, именуемую дисперсией. Формула дисперсии:
простая (для не сгруппированных внутри интервалов используемых данных):
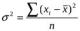 ,
,
или взвешенная (для сгруппированных данных):
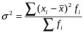 .
.