Материал: 2329

параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения. В зависимости от него будут получаться различные величины ошибок I и II рода.
Влогистической регрессии порог отсечения изменяется от 0 до 1
–это и есть расчетное значение уравнения регрессии. Будем называть его рейтингом.
Введём ещё несколько определений:
TP (True Positives) – верно классифицированные положительные примеры (так называемые истинно положительные случаи);
TN (True Negatives) – верно классифицированные отрицательные примеры (истинно отрицательные случаи);
FN (False Negatives) – положительные примеры, классифицированные как отрицательные (ошибка I рода). Это так называемый «ложный пропуск» – когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные примеры);
FP (False Positives) – отрицательные примеры, классифицированные как положительные (ошибка II рода). Это ложное обнаружение, т.к. при отсутствии события ошибочно выносится решение о его присутствии (ложно положительные случаи).
Что является положительным событием, а что – отрицательным, зависит от конкретной задачи. Например, если мы прогнозируем вероятность наличия заболевания, то положительным исходом будет класс «Больной пациент», отрицательным – «Здоровый пациент». И наоборот, если мы хотим определить вероятность того, что человек здоров, то положительным исходом будет класс «Здоровый пациент», и так далее.
При анализе чаще оперируют не абсолютными показателями, а относительными – долями, выраженными в процентах:
Доля истинно положительных примеров (True Positives Rate):
TPR TP 100%
TP FN
Доля ложно положительных примеров (False Positives Rate):
FPR FP 100 %
TN FP
Введем еще два определения: чувствительность и специфичность модели. Ими определяется объективная ценность любого бинарного классификатора.
28
Чувствительность (Sensitivity) – доля истинно положительных случаев:
Se TPR |
TP |
100 % |
|
||
|
TP FN |
|
Специфичность (Specificity) – доля истинно отрицательных случаев, которые были правильно идентифицированы моделью:
Sp |
TN |
100 % |
|
||
|
TN FP |
|
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры).
ROC-кривая получается следующим образом:
1.Для каждого значения порога отсечения, которое меняется от 0 до 1 с шагом dx (например, 0,01), рассчитываются значения чувствительности Se и специфичности Sp. В качестве альтернативы порогом может являться каждое последующее значение примера в выборке.
2.Строится график зависимости: по оси y откладывается чувствительность Se, по оси x – (100 %–Sp) (сто процентов минус специфичность), или, что то же самое, FPR – доля ложно положительных случаев.
Численный показатель площади под кривой называется AUC (Area Under Curve). С большими допущениями можно считать, что чем больше показатель AUC, тем лучшей прогностической силой обладает модель. Однако следует знать, что:
показатель AUC предназначен скорее для сравнительного анализа нескольких моделей;
AUC не содержит никакой информации о чувствительности и специфичности модели.
В литературе иногда приводится следующая экспертная шкала для значений AUC, по которой можно судить о качестве модели:
отличное качество модели – интервал AUC 0,9-1,0;
очень хорошее качество модели – интервал AUC 0,8-0,9;
хорошее качество модели – интервал AUC 0,7-0,8;
среднее качество модели – интервал AUC 0,6-0,7;
неудовлетворительное качество модели – интервал AUC 0,5-0,6.
29
Идеальная модель обладает 100 % чувствительностью и специфичностью. Однако на практике добиться этого невозможно, более того, невозможно одновременно повысить и чувствительность, и специфичность модели. Компромисс находится с помощью порога отсечения, т.к. пороговое значение влияет на соотношение Se и Sp. Можно говорить о задаче нахождения оптимального порога отсечения.
3.3. Практическая часть
Используя мастер импорта и файл с данными, например, C:\ProgramFiles\BaseGroup\Deductor\Samples\CreditSample.txt,
создайте новый сценарий и импортируйте данные.
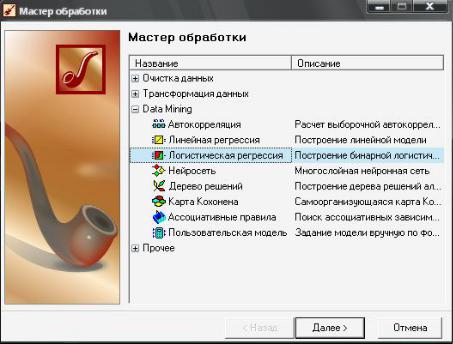
В мастере обработки выберите способ обработки «Логистическая регрессия».
Выбор метода «Логистическая регрессия»
Прежде чем начнется обработка данных, необходимо провести нормализацию полей и настроить обучающую выборку.
Нормализация полей проводится с цель преобразования данных к виду, подходящему для обработки средствами АП «Deductor». Например, при построении нейронной сети, линейной модели прогнозирования или самоорганизующихся карт «Входящие» данные
30
должны иметь числовой тип (т.е. непрерывный характер), а их значения должны быть распределены в определенном диапазоне. В этом случае при нормализации дискретные данные преобразуются в набор непрерывных значений.
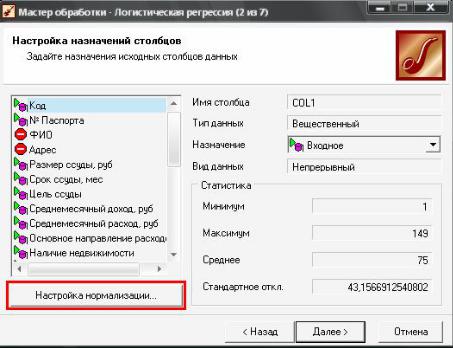
Настройка нормализации полей вызывается с помощью кнопки «Настройка нормализации» в нижней левой части окна «Настройка назначения столбцов».
Вызов окна настройки нормализации
Вокне «Настройка нормализации данных» слева приведен полный список входных и выходных полей. При этом каждое поле помечено значком, обозначающим вид нормализации:
линейная - линейная нормализация исходных значений;
уникальные значения - преобразование уникальных значений
вих индексы;
битовая маска - преобразование дискретных значений в битовую маску.
Вправой части окна для выделенного поля отображаются параметры нормализации.
31
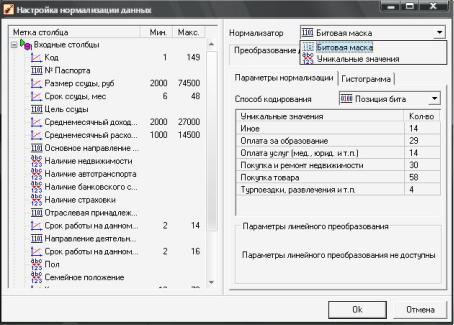
Окно настройки нормализации данных
Для числовых (непрерывных) полей с линейной нормализацией дополнительные параметры недоступны. В полях «Минимум» и «Максимум» секции «Диапазон значений» можно посмотреть минимальное и максимальное значения этого поля.
Для дискретных полей могут быть использованы два вида нормализации - уникальные значения и битовая маска.
Если дискретные значения преобразуются в битовую маску (т.е. каждому уникальному значению ставится в соответствие уникальная битовая комбинация), то возможны два способа такого преобразования, выбираемые из списка «Способ кодирования»:
1.Позиция бита - поле в этом случае представляется в виде n битов, где n - число уникальных значений в поле. Каждый бит соответствует одному значению. В 1 устанавливается только бит, соответствующий текущему значению, принимаемому полем, все остальные биты равны 0. Этот способ кодирования используется при малом числе уникальных значений.
2.Комбинация битов - каждому уникальному значению соответствует своя комбинация битов в двоичном виде.
Настройка обучающей выборки - разбиение обучающей выборки на два множества - обучающее и тестовое - для построения линейной модели.
32