Материал: 16
Обще признанным в настоящее время является позиционный принцип образования системы счисления. Значение каждого символа (цифры) зависит от его положения - позиции в ряду символов, представляющих число.
Единица каждого следующего разряда больше единицы предыдущего разряда в m раз, где m - основание системы счисления. Полное число получают, суммируя значения по разрядам:
![]()
где i - номер разряда данного числа; l - количество рядов; аi - множитель, принимающий любые целочисленные значения в пределах от 0 до m-1 и показывающий, сколько единиц i - ого ряда содержится в числе.
Устранение избыточности достигается применением неравномерных кодов, в которых буквы, имеющие наибольшую вероятность, кодируются наиболее короткими кодовыми последовательностями, а более длинные комбинации присваиваются редким буквам. Если i-я буква, вероятность которой Рi, получает кодовую комбинацию длины qi, то средняя длина комбинации
![]()
Считая кодовые буквы равномерными, определяем наибольшую энтропию закодированного алфавита как qср log m, которая не может быть меньше энтропии исходного алфавита Н, т.е. qср log m Н.
Отсюда имеем
![]()
При двоичном кодировании (m=2) приходим к соотношению qср Н, или
![]()
Чем ближе значение qср к энтропии Н, тем более эффективно кодирование. В идеальном случае, когда qср Н, код называют эффективным.
Эффективное кодирование устраняет избыточность, приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи или объем памяти, необходимой для их хранения
Кодирование источников без памяти
Источник сообщений называют источником без памяти, если вероятность появления на его выходе очередного символа никак не зависит от предыстории. Энтропия дискретного источника без памяти с алфавитом A={a1, a2, … aM} размерности M и вероятностями символов P(ai)
Кодирование источников без памяти
Для источников с памятью характерна зависимость последующих символов от предыдущих. Таким образом проявляется некая «информационная инерционность» источника, повышающая предсказуемость очередного символа и, следовательно, снижающая энтропию.
Кодовое дерево
Ведем понятие кодового дерева, которым часто пользуются при рассмотрении Известно, что любую букву или событие, содержащиеся в алфавите источника или в сообщении, можно разложить на последовательности двоичных решений с исходами «ДА»=1 и «НЕТ»=0, причем без потери информации. Таким образом, каждой букве исходного алфавита может быть поставлена в соответствие или, как говорят, приписана некоторая последовательность двоичных символов - 0 или 1.А такую последовательность называют кодовым деревом. При этом потери информации не происходит, так как каждое событие может быть восстановлено по соответствующему кодовому слову.
Равномерное кодирование
для построения равномерного кода с использованием D кодовых букв необходимо обеспечить выполнение следующего условия:
![]() ,
,
где n- количество элементов кодовой последовательности.
Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их в коды как n-разрядное число в D-ичной системе счисления
Статистическое кодирование
Статистическое кодирование теоретически позволяет приблизить среднюю длину кода к величине безусловной энтропии источника. Это означает, что первоначальная избыточность кодирования может быть устранена.
Метод кодирования Шеннона - Фано.
Буквы исходного алфавита записываются в порядке убывания их вероятностей. Это множество разбивается так, чтобы вероятности двух подмножеств были примерно равны. Все буквы верхнего подмножества в качестве первого символа кода получают 1, а буквы нижнего подмножества-0. Затем последнее подмножество снова разбивается на два подмножества с соблюдением того же условия и проводят то же самое присвоение кодовым элементам второго символа. Процесс продолжается до тех пор, пока во всех подмножествах не останется по одной букве кодового алфавита.
Метод кодирования Хаффмана.
Этот метод всегда дает оптимальное кодирование в отличие от предыдущего, так как получаемая средняя длина кодового слова является минимальной.
Буквы алфавита сообщения располагают в порядке убывания вероятностей. Две последние буквы объединяют в один составной символ, которому приписывают суммарную вероятность. Далее заново переупорядочивают символы и снова объединяют пару с наименьшими вероятностями. Продолжают эту процедуру до тех пор, пока все значения не будут объединены. Это называется редукцией. Затем строится кодовое дерево из точки, соответствующей вероятности 1 (это корень дерева), причем ребрам с большей вероятностью присваивают 1,а с меньшей-0. Двигаясь по кодовому дереву от корня к оконечному узлу, можно записать кодовое слово для каждой буквы исходного алфавита.
Теорема Шеннона
Эта
теорема гласит, что если источник
сообщений имеет энтропию Н
[бит/символ],
а канал обладает пропускной способностью
С
[бит/сек]
(пропускная способность характеризует
максимально возможное значение скорости
передачи информации), то всегда можно
найти способ кодирования, который
обеспечит передачу символов сообщения
по каналу со средней скоростью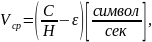 где
ε
— сколь угодно малая величина.
где
ε
— сколь угодно малая величина.
Обратное
утверждение говорит, что передача
символов сообщения по каналу со средней
скоростью Vср. > Н
невозможна и, следовательно,
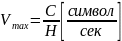
Эта теорема часто приводится в иной формулировке: сообщения источника сообщений с энтропией Н всегда можно закодировать последовательностями элементов кодовых символов с объемом алфавита k так, что среднее число элементов символов кода на один символ кодируемого сообщения (l ср. ) будет сколь угодно близко к величине H / log2 k, но не менее ее.
Отметим, что эта теорема показывает возможность наилучшего эффективного кодирования, при котором обеспечивается равновероятное и независимое поступление элементов символов кода, а следовательно, и максимальное количество переносимой каждым из них информации, равное log2 k (бит/элемент) .
Условие оптимальности кодов
1. Каждый элементарный символ должен переносить максимальное количество информации, для этого необходимо, чтобы элементарные символы (0 и 1) в закодированном тексте встречались в среднем одинаково часто. Энтропия в этом случае будет максимальной.
2. Необходимо буквам первичного алфавита, имеющим большую вероятность, присваивать более короткие кодовые слова вторичного алфавита.
Арифмитическое кодирование
Пpи аpифметическом кодиpовании текст пpедставляется вещественными числами в интеpвале от 0 до 1. По меpе кодиpования текста, отобpажающий его интеpвал уменьшается, а количество битов для его пpедставления возpастает. Очеpедные символы текста сокpащают величину интеpвала исходя из значений их веpоятностей, опpеделяемых моделью. Более веpоятные символы делают это в меньшей степени, чем менее веpоятные, и, следовательно, добавляют меньше битов к pезультату.
Пеpед началом pаботы соответствующий тексту интеpвал есть [0; 1). Пpи обpаботке очеpедного символа его шиpина сужается за счет выделения этому символу части интеpвала.
Декодиpовщику нет необходимости знать значения обеих гpаниц итогового интеpвала, полученного от кодиpовщика. Даже единственного значения, лежащего внутpи него, напpимеp 0.23355, уже достаточно. Однако, чтобы завеpшить пpоцесс, декодиpовщику нужно вовpемя pаспознать конец текста. Кpоме того, одно и то же число 0.0 можно пpедставить и как "a", и как "aa", "aaa" и т.д. Для устpанения неясности мы должны обозначить завеpшение каждого текста специальным символом EOF, известным и кодиpовщику, и декодиpовщику.
Словарное кодирование, алгоритм Лемпеля – Зива –Велча
Процесс сжатия выглядит следующим образом: последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Для декодирования на вход подается только закодированный текст, поскольку алгоритм LZW может воссоздать соответствующую таблицу преобразования непосредственно по закодированному тексту. Алгоритм генерирует однозначно декодируемый код за счет того, что каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, является ли строка уже известной, и, если так, выводит существующий код без генерации нового. Таким образом, каждая строка будет храниться в единственном экземпляре и иметь свой уникальный номер.
Кодирование
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу XX заносится первый символ сообщения.
Шаг 2. Считать очередной символ YY из сообщения.
Шаг 3. Если YY — это символ конца сообщения, то выдать код для XX, иначе:
Если фраза XYXY уже имеется в словаре, то присвоить входной фразе значение XYXY и перейти к Шагу 2 ,
Иначе выдать код для входной фразы XX, добавить XYXY в словарь и присвоить входной фразе значение YY. Перейти к Шагу 2.
Конец.
Декодирование
Начало.
Шаг 1. Все возможные символы заносятся в словарь. Во входную фразу XX заносится первый код декодируемого сообщения.
Шаг 2. Считать очередной код YY из сообщения.
Шаг 3. Если YY — это конец сообщения, то выдать символ, соответствующий коду XX, иначе:
Если фразы под кодом XYXY нет в словаре, вывести фразу, соответствующую коду XX, а фразу с кодом XYXY занести в словарь.
Иначе присвоить входной фразе код XYXY и перейти к Шагу 2 .
Конец.