Материал: 16
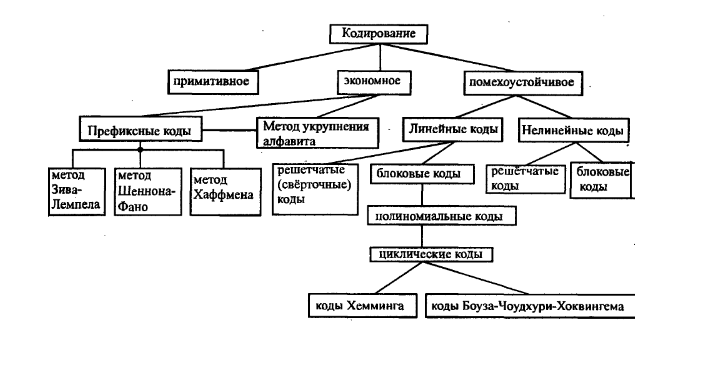
Способы кодирования источника:
Примитивное кодирование:
При примитивном кодировании символы алфавита источника представляются набором чисел от 0 до (K −1) (K — объём алфавита источника), т.е. нумеруются. При этом номер представляется в виде n-разрядного
m-позиционного кода, где
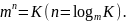
Примитивные коды являются равномерными, т.е. каждый символ
исходного алфавита содержит фиксированное количество кодовых позиций (кодовая комбинация имеет фиксированную длину).
Примитивный код широко используется в компьютерной технике для
представления символов и знаков текста («набор символов», «кодировка»). Примеры:
1. ASCII (American Standard Code for Information Interchange) — американская стандартная кодировочная таблица: 7-битная таблица для представления печатных символов и некоторых специальных кодов.
2. Национальные 8-битные варианты ASCII — для кириллицы это Windows-1251 (CP1251), КОИ-8, IBM code page 866 (CP866)
Неравномерное кодирование:
Код, комбинации которого имеют различную длину, называют неравномерным. Для неравномерного кода встаёт вопрос однозначности декодирования. Однозначность может быть обеспечена при помощи специального символа-разделителя (как в коде Морзе), однако, это не оптимально. Без разделителя можно обойтись, если ни одно кодовое слово не
является началом другого. Коды, обладающие таким свойством, называют префиксными.
Минимально возможное среднее количество кодовых символов на
один
символ источника определяется пределом
Шеннона:
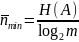
m — позиционность кода.
Одним из первых экономных кодов, использующих принцип энтропийного кодирования, является код Шеннона-Фано.
Префиксные коды, неравенство Крафта.
Код, обладающий тем свойством, что никакое кодовое слово не является началом (префиксом) другого кодового слова, называется префиксным. Для построения префиксных кодов используется двоичное дерево.

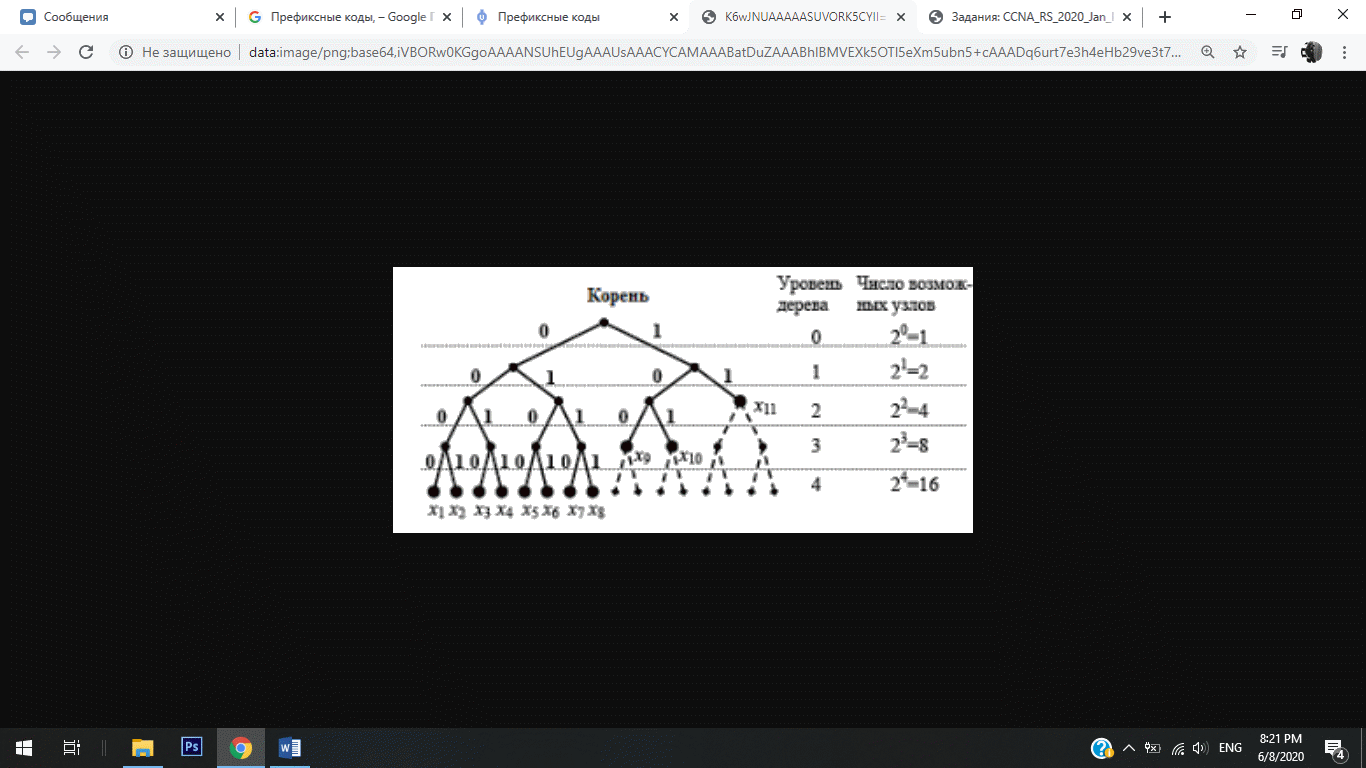
Для построения кода каждому ребру, выходящему из узла, называемого порождающим, необходимо приписать бит кода (ноль для левого ребра и единицу для правого). Каждый узел i-ого уровня (i=0,…,n) потенциально может породить ровно 2n-i узлов последнего уровня n. Листья дерева (оконечные узлы) соответствуют символам кодируемого источника причем уровень соответствующего узла в дереве равен длине битового кода Rk .
Неравенство
Крафта:
Пусть у нас есть n символов, кодовые
слова которых имеют длины
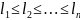 .
Тогда необходимое и достаточное условие
существования префиксного кода в r-ичном
алфавите для данных символов, состоит
в выполнении неравенства:
.
Тогда необходимое и достаточное условие
существования префиксного кода в r-ичном
алфавите для данных символов, состоит
в выполнении неравенства:
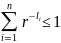 (r
– число символов).
(r
– число символов).
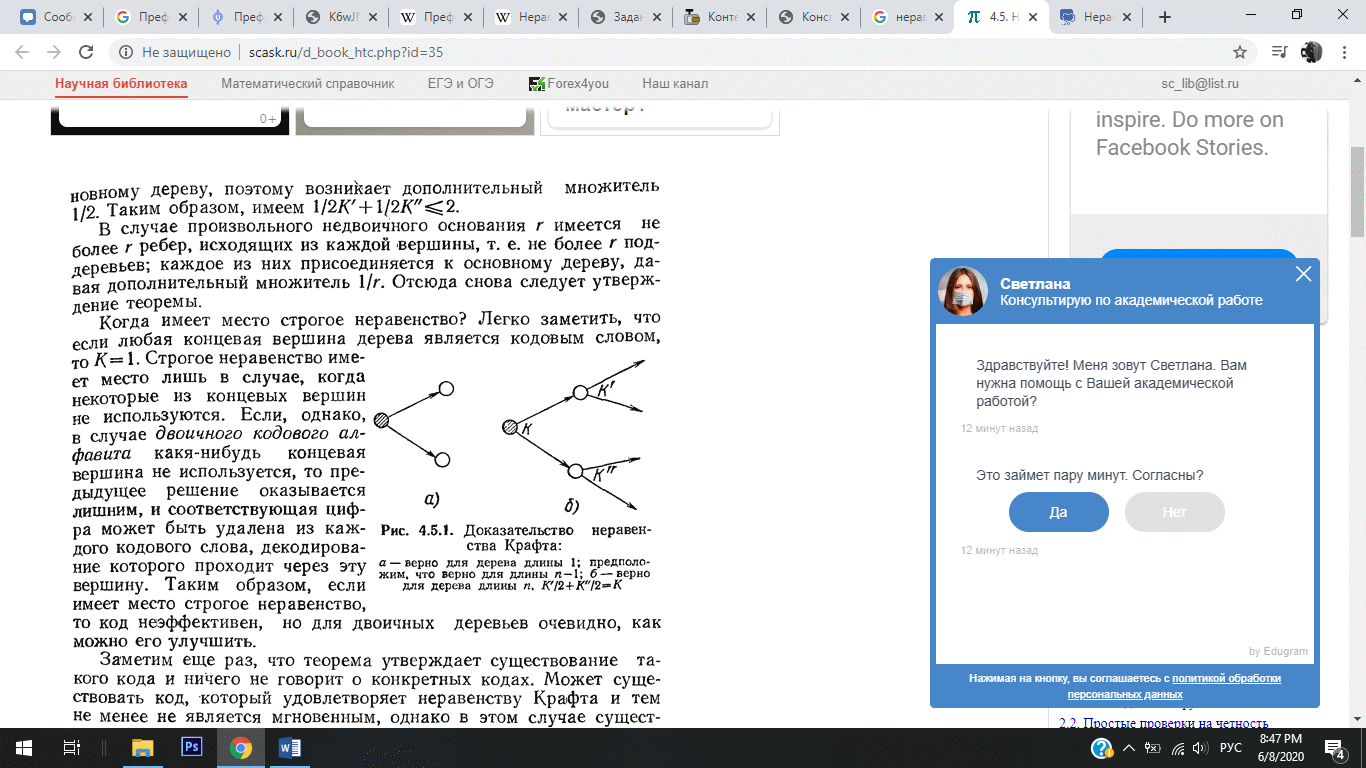 Неравенство
Крафта легко доказать с помощью дерева
декодирования. Рассмотрим случай
двоичного алфавита.
Неравенство
Крафта легко доказать с помощью дерева
декодирования. Рассмотрим случай
двоичного алфавита.
Если максимальная длина пути на дереве равна 1, то на нем есть одно или два ребра длины 1. Таким образом, либо 1/2⩽1 — для одного символа источника, либо 1/2+1/2⩽1 — для двух символов источника.
Предположим далее, что неравенство Крафта справедливо для всех деревьев высоты меньше n−1. Докажем, что оно справедливо и для всех деревьев высоты меньше n. Для данного дерева максимальной высоты n ребра из первой вершины ведут к двум поддеревьям, высоты которых не превышают n−1; для этих поддеревьев имеем неравенства K1⩽1 и K2⩽1, где K1, K2 — значения соответствующих им сумм. Каждая длина li в поддереве увеличивается на 1, когда поддерево присоединяется к основному дереву, поэтому возникает дополнительный множитель ½. Таким образом, имеем (½)*K1+(½)*K2⩽1.
В случае произвольного недвоичного основания r имеется не более r ребер, исходящих из каждой вершины, то есть не более r поддеревьев; каждое из них присоединяется к основному дереву, давая дополнительный множитель 1/r.
Предельные возможности эффективного кодирования дискретных сообщений.
Пусть
А
– источник последовательности знаков
с объемом алфавита K
и производительность H’(A).
Для
передачи по дискретному каналу нужно
преобразовать сообщения в последовательность
кодовых символов В
так, чтобы эту кодовую последовательность
можно было затем однозначно декодировать.
Для этого необходимо, чтобы скорость
передачи информации от источника к коду
I’(A,
B)
равнялась производительности источника
H’(A).
Необходимое условие для кодирование
H’(B)≥H’(A),
обозначив
через TK
длительность
кодового символа, а через TС
длительность элементарного сообщения
получим:
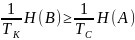 или
или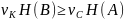 .
.

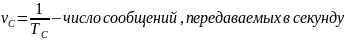
Теорема
кодирования для источника заключается
в том, что, передавая двоичные символы
со скоростью
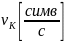 , можно закодировать сообщение так,
чтобы передавать их со скоростью
, можно закодировать сообщение так,
чтобы передавать их со скоростью
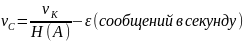 ,
где
,
где
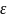 – сколь угодно малая величина.
– сколь угодно малая величина.
Если источник передает сообщения независимо и равновероятно, то H(A) = log K, если при этом К – целая степень двух (К = 2n), то H(A) = n. С другой стороны, используя для передачи каждого сигнала последовательность из n двоичных символов, мы получим 2n = К различных последовательностей и можем каждому сигналу сопоставить одну из кодовых последовательностей.
Прямая теорема (теорема Шеннона для канала без помех – первая теорема Шеннона)
Теорема Шеннона устанавливает возможность передачи информации по каналу связи.
Смысл теоремы состоит в том, если пропускная способность канала связи достаточно большая, то хотя временные задержки возможны, но они когда-нибудь «рассосутся».
Пусть Vu - (информационная) производительность источника, т.е. количество информации, производимое источником в единицу времени; Ck - (информационная) пропускная способность канала, т.е. максимальное количество информации, которое способен передать канал без искажений за единицу времени. Первая теорема Шеннона утверждает, что безошибочная передача сообщений определяется соотношением Vu и Ck.
Первая теорема Шеннона: если пропускная способность канала без помех превышает производительность источника сообщений, т.е. удовлетворяется условие Ck>Vu, то существует способ кодирования и декодирования сообщений источника, обеспечивающий сколь угодно высокую надежность передачи сообщений. В противном случае, т.е. если Ck<Vu такого способа нет.
Строго первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак кодируемого алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Используя понятие избыточности кода, можно дать более короткую формулировку теоремы:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Эта теорема открывает принципиальную возможность оптимального кодирования. Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически – для этого должны привлекаться какие-то дополнительные соображения.
В применении к побуквенному кодированию прямая теорема может быть сформулирована следующим образом:
Существует префиксный, то есть разделимый код, для которого средняя длина сообщений отличается от нормированной энтропии не более, чем на единицу:
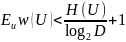
где: U - некоторый источник сообщений, а также множество всех его сообщений u1,u2,...,uK ; w1,w2,...,wK - длины сообщений источника после кодирования; EUw(U) - средняя длина сообщений; H(U) - энтропия источника; D - количество букв в алфавите кодирования (например, 2 для двоичного алфавита, 33 - для кодирования заглавными русскими буквами и т. д.)
Классификация кодов
Канальные коды можно классифицировать на основе ряда признаков. Первый из них – объем алфавита, согласно которому коды разделяются на двоичные, троичные и т. п. Рассматриваем двоичные коды.
Другой классификационный признак отражает способ преобразования потока данных (сообщений) источника в поток кодовых символов. В этом плане коды можно разделить на блоковые и решетчатые (древовидные). В блоковых кодах k битов данных преобразуются в кодовое слово длины n, проверочные символы которого защищают только «свои» k битов данных. В решетчатых (в частности сверточных) кодах текущая группа проверочных символов защищает несколько смежных блоков данных.
В зависимости от явного присутствия битов данных в кодовых словах различают систематические и несистематические коды. Блоковый код из рассмотренного выше примера – систематический, так как первые два символа в любом его слове – «чистые» биты сообщения.
Наконец, название кода часто содержит определение алгоритма построения или имя первооткрывателя: (линейный, циклический, турбокоды, с низкой плотностью проверок на четность, Хэмминга, Голея, Рида-Соломона, БЧХ, и пр.).
Помехоустойчивые (корректирующие) коды классифицируются:
По основанию кода m— объему кодового алфавита
Блочные и непрерывные
Если длина всех комбинаций блочного кода одинакова - код называют равномерным, в противном случае код является неравномерным
равномерный телеграфный код МТК-2
неравномерные коды Морзе,Хаффмена, Шеннона-Фано
Длина кодового слова равномерного кода равна n
число различных блоков M mn
Если «равно», то код называют простым или примитивным
Если «меньше» код называют избыточным или помехоустойчивым
Помехоустойчивые коды могут обнаруживать и (или) корректировать ошибки.
Блочные корректирующие коды принято обозначать как (n, k)
Количество проверочных символов r = n–k
Количество разрешенных комбинаций M = mk m = 2 M = 2k
Скорость кода
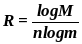 m = 2,
то
m = 2,
то
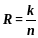
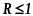 Код
избыточный
Код
избыточный
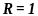 Код
примитивный
Код
примитивный
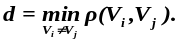
Эффективное кодирование
Сущность эффективного (Кодирования заключается в том, что неравномерное распределение вероятностей появления коррелированных символов сообщений с помощью определенным образом выбранного кода переводят в равномерное распределение вероятностей появления независимых кодовых символов.
Если исходный алфавит содержит m букв, то для построения равномерного кода с использованием k кодовых букв необходимо удовлетворить соотношение m kq , где q - количество элементов в кодовой последовательности.
Поэтому
![]()
Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их коды как q - разрядные числа в k-ичной системе счисления.