Материал: Інформатика_1 (методи побудови алгоритмівта та їх аналіз)
При виконанні дій, робота яких пов'язана із записом значения змінної у відповідну область пам'яті, тобто стандартних процедур read, readln та оператора присвоювання змінній деякого значения, відбувається визначення адреси, що відповідає розміщенню значения даної змінної в пам'яті комп'ютера і запис указаного двійкового значения за цією адресою.
Виконання операції читання значения простої змінної відбувається при використанні стандартних процедур write, writeln та обчислення значень виразів, у яких використовуються ідентифікатори цих змінних. При цьому система «знає» адресу розміщення в пам'яті значения ціеї змінної і «читає» його за цією адресою. Далі відбувається процес декодування двійкового зображення інформації, що відповідає правилу її кодування згідно з указаним для цієї змінної типом.
Можна зробити висновок, що прості змінні є структурою прямого доступу.
Запитання для самоконтролю
-
Що називають структурами даних?
-
Чому виникає необхідність організації різних структур даних?
3. Які два основні моменти пов'язані з визначенням структури даних?
4. Які основні дії виконуються над елементами структури даних?
5. Який доступ до елементів заданоі структури називають прямим?
6. Який доступ до елемєнтів задано! структури називають послі-довним?
7. Яким чином проста змінна відображається на пам'ять комп'ютера?
8. Як відбувається читання значения змінної простого типу?
9. Як відбувається запис значения змінної простого типу?
10. Який принцип доступу здійснюється до значень простих змінних при їх обробці? Обґрунтуйте свою відповідь.
МАСИВ
3 масивами ми вже ознайомилися раніше і набули певного досвіду роботи з ними. Тому нашим завданням є перевалено уточнения питания розташування масивів у пам'яті комп'ютера та алгоритму доступу до їх елементів при виконанні опера-цій читання і запису.
Розглянемо спочатку одновимірні масиви.
Спершу нагадаемо, що пам'ять комп'ютера є дискретною і мае лінійну структуру. Тобто, всі комірки пам'яті мають абсолютні адреси, що починаються з 0. Для зручності адреси комірок пам'яті комп'ютера представляють шістнадцятковими числами: 0, 1, 2…9, А, В, С, D, Е, F, 10, .... FF, ... .
Саме тому відображення елементів одновимірного масиву на пам'ять комп'ютера уявити собі зовсім нескладно: вони записані в пам'ять підряд, починаючи з деякого визначеного місця.
При розташуванні масиву ava2, .... ап у пам'яті комп'ютера визначається адреса його початку, тобто першого елемента масиву av і далі розміщуються всі елементи, займаючи кож-ний стільки байтів, скільки визначено вказаним типом. Тобто, система «знає» адресу першого елемента масиву, скільки байтів займає кожний елемент і загальну кількість елементів масиву.
Адреса розміщення будь-якого іншого елемента а, визначається за таким алгоритмом: до адреси першого елемента додається кількість байтів, що займає кожний елемент, помножена на порядковий номер потрібного елемента. Таким чином, існує алгоритм обчислення адреси будь-якого елемента одновимірного масиву. Перевага такого принципу безперечна: системі не треба знати адресу кожного елемента масиву, оскільки її можна обчислити за допомогою елементарних арифметичних дій.
Тепер зрозуміло, як відбувається читання і запис інформації, коли використовується структура даних «масив». Спершу визначається адреса потрібного елемента масиву, а потім дії читання і запису виконуються так само, як і для простих змінних.
60
Можемо також зробити висновок, що структура даних «масив» є, як i проста змінна, структурою прямого доступу.
Розташування елементів двовимірного масиву aij, де i = 1, 2, ..., п; j = 1, 2, ..., т у пам'яті комп'ютера відбувається так: спочатку розміщуються елементи першого рядка, потім другого і т. д.
Так само як і для одновимірного масиву, при визначенні місця розташування елементів двовимірного стає відомою адреса першого елемента. Адреса будь-якого іншого елемента аij цього масиву визначається за алгоритмом:
<адреса аij> = <адреса а11> + ((і - 1) • m + j - 1) • <кількість байтів указаного типу>.
Тобто для визначення адреси поточного елемента двови-мірного масиву потрібно до адреси першого елемента додати кількість байтів, яку займає один елемент указаного типу, по-множену на кількість елементів двовимірного масиву (і - 1) • т + j - 1, що розміщені в пам'яті комп'ютера від першого елемента до даного аij.
Елементи масивів більшої вимірності розміщуються в па-м'яті комп'ютера аналогічно.
Наприклад, тривимірний масив зручно уявити собі як па-ралелепіпед, кожен шар якого представляв собою таблицю, тобто двовимірний масив. Отже, тривимірний масив є масивом двовимірних масивів. У пам'яті комп'ютера він виглядатиме так: елементи першого «шару» тривимірного масиву будуть розташовані в пам'яті за правилом двовимірного масиву, потім так само елементи другого «шару» і т. д.
Запитання для самоконтролю
-
Що представляє собою структура даних «масив»?
-
Як відображається на пам'ять комп'ютера одновимірний масив?
-
Які два основні моменти пов'язані з визначенням структури даних?
-
За яким алгоритмом визначається адреса будь-якого елемента одновимірного масиву?
-
Як відбуваються в пам'яті комп'ютера операції запису і читання елементів одновимірного масиву?
-
Яким є доступ до елементів масиву? Обгрунтуйте свою відповідь.
-
Як розташовуються в пам'яті комп'ютера елементи двовимірно-го масиву?
-
Як обчислюється адреса будь-якого елемента двовимірного масиву?
-
Яким чином розташовуються в пам'яті комп'ютера елементи масивів більшої розмірності?
t
61
СТЕК
Стеком називається структура даних, що організована за принципом «останнім прийшов — першим пішов».
3 поняттям стека ми вже зустрічалися при ознайомленні з алгоритмом роботи рекурсії.
Ми домовилися розглядати структури даних у відображенні на пам'ять комп'ютера. Тому в першу чергу треба визначитися, яким чином елементи даної структури зберігаються в пам'яті.
Оскільки організація одновимірного масиву аналогічна лі-нійній структурі пам'яті комп'ютера, то логічним буде представления стека саме у вигляді одновимірного масиву (мал. 5).
|
а1 |
а2 |
аз |
... |
а4 |
Мал. 5
А от організація обробки елементів цього масиву буде такою, що відповідає означению цієї структури даних. Для простішого розуміння поняття «стек» проведемо аналогію зі стосом книг.
Додаючи нову книжку в стос, ми кладемо її зверху, тобто операщя запису нового елемента в стек відбувається в кіпець масиву додаванням нового елемента. А для того щоб узяти книжку із середини стосу, нам треба всі верхні книжки по од-ній зняти у зворотному порядку щодо їх складання. Таким чином, операщя читання зі стека відбувається також із кінця масиву, але в зворотному порядку.
О
 бробляючи
елементи масиву, ми вводимо поняття
поточного порядкового номера елемента
масиву L
В
даному випадку нас цікавитиме
лише
останній
елемент:
ми його або зчитуємо
(
),
або після
нього
записусмо новий елемент (
).
бробляючи
елементи масиву, ми вводимо поняття
поточного порядкового номера елемента
масиву L
В
даному випадку нас цікавитиме
лише
останній
елемент:
ми його або зчитуємо
(
),
або після
нього
записусмо новий елемент (
).
Індекс останнього елемента стека називається вершиною. Це означає, що для обробки елементів стека нам достатньо знати значения лише однієї величини і вершини стека. Схематично стек можна зобразити так (мал. 6):
і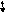
|
а1 |
а2 |
… |
ai |
… |
an |

Мал. 6
П одвійною
стрілкою (
)
ми позначили
елемент вершини стека,
який
доступний як
для читання,
так
і
для
запису,
a
сірим
кольором -
ті
елементи масиву, які належать
стеку. Нижня
стрілка показує зміну розміру стека
в межах визначеного масиву.
одвійною
стрілкою (
)
ми позначили
елемент вершини стека,
який
доступний як
для читання,
так
і
для
запису,
a
сірим
кольором -
ті
елементи масиву, які належать
стеку. Нижня
стрілка показує зміну розміру стека
в межах визначеного масиву.
Алгоритм запису нового елемента х у стек виглядатиме так:
I := 1 + 1; аі:=х.
Тобто ми спочатку збільшуємо значения вершини стека на 1, а потім елементу масиву з індексом і присвоюємо значения х. Алгоритм читання чергового елемента стека буде таким:
хі := а,;
і := 1-1.
Пояснимо цей алгоритм: спочатку значения елемента стека, що знаходиться на його вершит і, читаемо в х, а потім змен-шуємо значения вершини стека на 1.
Тепер, коли ми визначили операції для роботи з елементами стека, обов'язково треба зауважити таке.
Для швидкодії роботи зі стеком не витрачаеться час на *знищення» елементів стека, які еже «вичитано». Доступ до цих елементів утрачається лише за рахунок зміни значения вершини стека (і - 1). Таким чином, у масиві лишається «сміт-тя». При наступному «попаданні» на ці елементи в масиві під час виконання операції запису туди будуть записані нові значения.
Розглянемо тепер реалізацію цих алгоритмів мовою Pascal. Перш за все треба обговорити критичні ситуації, які можуть виникнути при читанні та записі інформації. А саме: при чи-танні може виникнути ситуація, коли вже читати немае чого, тобто стек порожній, а при записі - стек переповнений, тобто досягнуто останнього елемента масиву, оскільки, описуючи масив у програмі, ми повинні вказати межі зміни його індексу.
Процедура читання зі стека:
procedure read_from_stack; begin
if i = 0 then writeln('Stack is empty') else begin writeln(a[ij); dec(i) end end;
Логічним є твердження, що на початку роботи програми з обробки елементів стека вершина стека повинна мати значен-
г
63
ня 0, оскільки в початковому стані дозволена лише операція за-пису в стек.
Процедура запису в стек може виглядати так:
procedure write_to_stack; begin
if i > = n then writeln('Stack is full') else begin inc(i)
readln(a[i]); end end;
При виконанні програми, що реалізує роботу зі стеком, нам цікаво спостерігати за вмістом стека під час виконання операцій читання та запису. Для цього можна скористатися процедурою виведення поточного вмісту стека:
procedure printstack; vark: word; begin
for k := 1 to i do write(a[k],' '); writeln end;
Корисною також є інформація про вміст усього масиву, від-веденого для організації стека, під час обробки елементів стека. Саме при виконанні цієї процедури можна спостерігати за появою «сміття» в масиві та заміною його на нові значения при виконанні оперяції запису в стек.
procedure printmas; var i: word; begin for i := 1 to n do
write(a[i], ' '); writeln end;
Нам залишилося ще визначитися з принципом доступу до елементів даної структури. Робота зі стеком зводиться до обробки вершинного елемента, який доступнии завжди, а решта елементів - ні. Щоб зробити доступним деякий елемент ак (ft < i), треба спочатку вичитати зі стека всі елементи, що зна-ходяться вище від нього, зробивши таким чином даний елемент вершиною стека. Тому можна зробити висновок: структура даних «стек» є структурою послідовного доступу.
64
• Запитання для самоконтролю
-
Дайте означения структури даних «стек».
-
Як структура даних «стек» відображається на пам'ять комп'ютера?
-
Що називається вершиною стека?
-
Зобразіть схематично роботу з елементами стека.
-
Як відбувається операція запису елемента в стек?
-
Запишіть алгоритм запису елемента в стек.
-
Як відбувається операція читання елемента зі стека?
-
Запишіть алгоритм читання елемента зі стека.
-
Яким чином досягається швидкодія роботи зі стеком?
-
Запишіть процедуру запису в стек.
-
Запишіть процедуру читання зі стека.
-
Запишіть процедуру перегляду елементів стека.
-
Запишіть процедуру перегляду елементів масиву, на який відоб-ражається вміст стека.
-
Який принцип доступу здійснюється до значень елементів стека при їх обробці? Обґрунтуйте свою відповідь.
Завдання
1. Розробити діалогову меню-орієнтовану програму роботи з елементами стека за такими пунктами:
-
записати елемент у стек;
-
прочитати елемент зі стека;
-
показати вміст стека;
-
показати вміст масиву;
-
завершити роботу зі стеком.
2. Протестувати програму завдання 1 для масиву розмірністю п - 5, спостерігаючи за вмістом стека та масиву, за такою схемою:
-
заповнити повністю стек;
-
спорожнитк стек;
-
заповнити стек до половини;
-
вичитати один елемент;
-
записати два елементи.
3. Зробити письмовий аналіз виконання завдань 1,2.
I
ЧЕРГА
Чергою називасться структура даних, организована за принципом «першим прийшов — першим ПІІІІ0В».
Черга, так само як і стек, відображається на пам'ять комп'ютера у вигляді одновимірного масиву (мал. 7).
|
а> |
а2 |
аз |
... |
ап |
Мал. 7
.4 Іпформятпка. в Iі > к. і
65
Принцип обробки елементів черги схожий на звичайне фор-мування черги в магазині. В кожний момент часу обслуговуеть-ся перший покупець. Шсля обслуговування він іде з черги і на його місце стае наступнии — тепер він перший. Новий покупець стае в кінець черги.
Якщо цю схему перенести на обробку елементів черги, то, на перший погляд, треба знати лише індекс останнього елемента черги, щоб після нього можна було записати новий елемент. Початок черги при цьому завжди буде збігатися з першим еле-ментом масиву (мал. 8).
п
|
ах |
аг |
... |
аі |
... |
ап |
Мал. 8
Але при такій логіці існує один суттєвий недолік: після ви-бування з черги першого елемента всі решта повинні зсуватися на одну позицію вліво. Тобто потрібно кожний раз при вико-нанні операції читання виконувати таку послідовність дій:
а, := а1 + 1 для і = 1, 2, ..., <індекс кінця черги >.
Зрозуміло, що така схема обробки операції читання забирає багато часу. Для його економії застосуємо ідею читання елемента стека. Тобто після читання елемента не будемо намагатися знищити його значения, а просто перемістимо індекс початку черги на наступнии елемент. Таким чином ми приходимо до ідеї існування двох індексів: і - початок черги, який ще носить назву «голова» черги, та у - кінець черги, що називаеться «хвостом» черги. Тепер схематично чергу можна зобразити так (мал. 9):
|
- |
... |
а, |
aj |
... |
ап |
Мал. 9
На схемі сірим кольором позначена та частина масиву, в якій розміщені елементи черги.
Подамо алгоритм запису в чергу елемента х:
j:=j+1; а,:=х.
Тобто ми спочатку збільшуємо значения індексу «хвоста» черги на 1, а потім елементу масиву з індексом j присвоюємо значения х.
66
Алгоритм читання елемента черги виглядатиме так:
х := а,; i := i + 1.
Тобто значения «голови» черги читаемо вх, в потім збіль-пгуємо індекс «голови» черги на 1.
Тепер можна уявити собі, що наша черга ніби повзає по ма-сиву, переміщуючись від першого елемента до останнього. Причому елементи черги не розриваються і знаходяться в тій послідовності, в якій записувалися. Можна говорити, що запис у чергу буде неможливий, тобто черга переповнена, коли «хвіст» досягне останнього елемента масиву, а читання стане неможливим, тобто черга порожня, коли «голова» пережене «хвіст».
Запишемо в термінах такого тлумачення процедуру читання елемента черги:
procedure read_from_queue; begin
if i > j then writelnf 'Queue is empty') else begin
writeln(a[i]); inc(i) end end;
Процедура запису елемента в чергу:
procedure write_to_queue; begin
if j = n then writeln('Queue is full') else begin inc(j); readln(a[j]) end end;
Але це досить спрощений погляд на ефективне використан-ня елементів масиву для розміщення черги, адже в масиві мо-жуть залишатися елементи, які не є на даний момент елемента-ми черги. Розглянемо кілька конкретних ситуацій.
Нехай виконуємо лише операції запису в чергу. При цьому «голова» черги весь час знаходиться на першому елементі масиву, а «хвіст» зміщується в сторону останнього. Коли буде до-сягнуто кінця масиву, це означатиме, що черга переповнена і наступні операції запису стануть неможливими. Це видно з на-ведених вище процедур запису та читання.
67
Однак ситуація зміниться, якщо поряд із операціями запису виконуватимемо і операції читання з черги. На перший погляд здається, що запис стане неможливим, коли «хвіст» черги до-сягне останнього елемента масиву. Але на початку масиву є вільні місця, що залишилися після виконання читання з черги (і > 1). Чому б їх не використати під елементи черги? Для цьо-го треба лише виконати операцію j := 1. Наша черга ніби завер-неться своїм хвостом на початок масиву. Тепер ознакою того, що черга переповнена, буде ситуація, коли «хвіст» дожене «голову». Схематично це виглядатиме так (мал. 10):