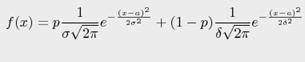Материал: Разработка программы для генерации сетевого трафика с заданными параметрами
Как показано на второй диаграмме, существует пять подходов для создания содержимого пакетов. Но они не отвечают выбранному направлению работы - размытие профиля пользователя, чтобы злоумышленники не могли определить список сайтов, посещаемых пользователем и разделить синтетический трафик от реально генерируемого пользователем.
Первые два подхода не применимы в данной ситуации по причине того, что они подвержены узости хостов, к которым происходят запросы, а для увеличения этого списка, необходимо производить обращения к новым узлам, сохранять их и подгружать в систему. Так же проблемным местом является циклическая повторимость профиля генерируемого трафика (в случае второго подхода этот момент пытаются решить, но в литературе не было найдено убедительных доказательств, что подобные модификации вносят значительный вклад в изменение статистического профиля трассы).
Третий подход изначально подразумевает сильную узость параметров, которые моделируются. В существующих работах они не выходили выше транспортного уровня. А так же, встаёт проблема что модели - они, обычно, жёстко математически заданы, что, соответственно, не сложно отличить от реального мира, в котором не существует жёстких закономерностей. Последний же подход, не подходит по тем же причинам, что описаны выше.
В связи с этим, был разработан новый подход, описанный в следующей главе.
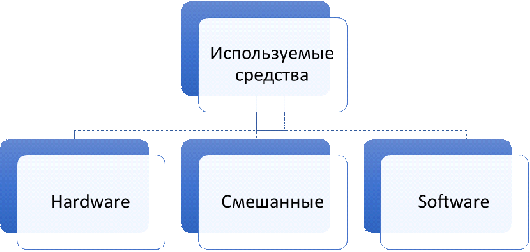
Диаграмма. 1 Классификация по типу используемых средств
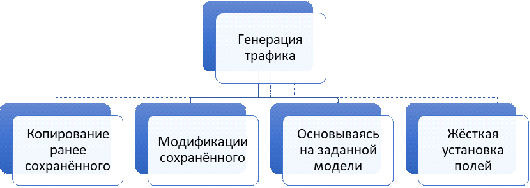
Диаграмма. 2 Классификация по источнику данных для создания пакетов
Глава 2. Описание выбранных методов, моделей, алгоритмов решения задач
Как было сказано выше, для генерации пакетов был выбран программный
уровень в связи с необходимостью в точности повторения протоколов верхнего
уровня. После чего необходимо было решить каким образом создавать пакеты.
Существующие подходы не удовлетворяли поставленным задачам и выбранному
направлению. Поэтому был разработан новый метод.
2.1 Метод генерации запросов
В ситуации необходимости полной симуляции поведения пользователя, приходится оперировать уровнем выше - повторять не трафик, исходящий от пользователя во время его работы, а повторение действий самого пользователя. Что обычный пользователь делает Электронный ресурс: можно выразить как «переходить от сайта к сайту по ссылкам» - а это протокол HTTP, являющийся базой для WWW. В дополнение к этому необходимо отметить, что, помимо переходов по ссылкам, пользователь так же просматривает контент на конкретной странице (читает текст, смотрит картинки/видео), или заполняет некоторую информацию (формы, сообщения, посты). Соответственно, обобщённо, получается следующий список действий пользователя:
. Переход по ссылке - в этом случае браузер генерирует запрос к веб-серверу, получает HTML код страницы, затем выполняет js-скрипты и подгружает дополнительную информацию, необходимую для корректного отображения страницы такие как: картинки, видео, баннеры сторонних сайтов.
. Просмотр страницы - в это время с точки зрения сетевого обмена не происходит никаких действий = задержка
. Взаимодействие со страницей - здесь может быть, как переход на другую страницу, отправка формы так и запуск на выполнение определённого скрипта. В первых двух случаях это ничто иное как обращение к серверу по определённому url, с параметрами. В третьем - исполнение jsскрипта происходит локально, в ином случае его можно классифицировать как отправка формы (= стандартный REST запрос)
В результате получается, что с точки зрения сетевого обмена все действия пользователя можно подразделить на два типа: отправка REST запроса по url адресу и ожидание (простой). Как симулировать второе действие - очевидно. С первым чуть сложнее, но тоже достаточно просто если представить, что составление запроса, его отправку на веб-сервер и последующую обработку ответа предоставить браузеру - такому же, каким пользуется среднестатистический пользователь.
В результате приведённого анализа появилась реализованная концепция полной загрузки веб-страниц браузером. Но существовали ограничения:
. Необходима гибкость в передаче адреса, с которого производить загрузку - должно быть предоставляться открытое API
. Данное средство (браузер) должно использоваться большим количеством пользователей
. Легковесность, чтобы была возможность запускать множество потоков (= загрузок) параллельно.
Распределение браузеров по популярности использования на ПК за период с
Января по Март 2017 года представлена на рис. 4.
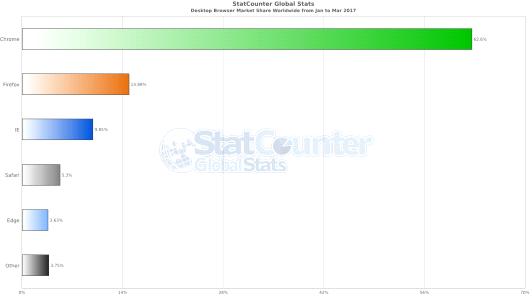
Рисунок 4. Распределение популярности браузеров за 01.17-03.17 [14]
Далее в таблице 2 приведены движки, на которых в данный момент базируются
представленные (и некоторые другие, известные в России) браузеры. Отсортирован
лист по убыванию процента аудитории, использующего браузеры на данном движке
Таблица. 2. Движки браузеров с процентом аудитории [14]
|
Движок |
Браузеры |
Процент аудитории |
|||||||||||||||||||||||||||||||||||||||||||||||
|
WebKit (позднее - Blink) |
Chrome, Safari, Opera, Яндекс браузер |
>68% |
|||||||||||||||||||||||||||||||||||||||||||||||
|
Gecko |
Mozilla Firefox |
14.88% |
|||||||||||||||||||||||||||||||||||||||||||||||
|
Trident |
IE, Edge |
13.48% 2.2 Создание модели поведения пользователя
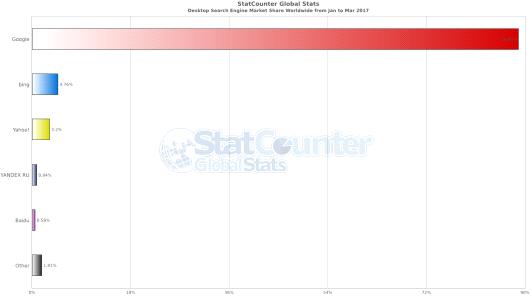
2.2.1 Выбор ссылок Рассмотрим логику поведения пользователей. То, как они попадают на ту или иную страницу: . Переход по ссылке, с одной страницы на другую . Использование поисковых систем . Прямой переход (например, из закладок в браузере) Необходимо учитывать, что в целях стоит размытие профиля пользователя - соответственно необходимо генерировать запросы к очень большому количеству различных сайтов. В связи с этим делается допущение, что для второго и третьего пункта можно рассматривать сайты отдельно. Далее рассмотрены разработанные алгоритмы для симуляции выбора ссылок для каждого из приведённых пунктов: . Переход по ссылке с одной страницы на другую. Если существует такой переход, значит в HTMLкоде страницы существует соответствующий тэг. Таким образом, алгоритм действий таков: загрузка первой страницы, парсинг HTMLразметки, выбор всех тэгов-ссылок (<a>). Далее случайным образом выбор из получившегося списка ссылки, переход по ней и повторение действий с начала. Другой вариацией этого подхода, является переход по нескольким ссылкам на одной странице (симуляция возврата пользователя назад, и переход в другое место) . Использование поисковых систем. Подразумевается отправка пользователем запроса и переход по нескольким наиболее популярным ссылкам. С которыми, далее, возможен повторения сценария из пункта 1. В качестве основной поисковой системы был выбран Google - см. описание пакета google 1.9. в Python package Index [21], в связи с тем, что его использует практически 90% пользователей сети (Рис. 5) А так же у него есть функция отображения наиболее популярных, среди поисковых выдачей страниц. Два способа работы с поисковой системой:
Рисунок 5. Распределение использования поисковых систем пользователями ПК за последние три месяца [14] . Запрос вида site:<адрес_сайта> - в данном случае выбираются наиболее релевантные страницы на заданном сайте. Задаётся список любых возможных запросов к поисковой системе, и с выдачей по каждому запросу идёт отдельная генерация (проход по первым N ссылкам из выдачи с возможностью углубления по каждой ссылке) . Прямой переход. Для реализации данного метода (а также желание не повторяться с предыдущими) было выбрано использование sitemaps (описание протокола [22]). Это, в основном, xml файл, предоставляемый большинством сайтов, в котором находится информация обо всех страницах сайтах и, зачастую, с проставленным приоритетом страниц (= популярностью среди пользователей). Соответственно из данного списка, определённым образом выбираются страницы для дальнейшего открытия. Механизм выбора - настраиваемый: случайным образом или последовательно. 2.2.2 Распределение времени ожиданияСтиль поведения в сети различных пользователей - разный. Некоторым необходимо большое количество времени, чтобы понять подходит ли им тот или иной сайт, и стоит ли вчитываться внимательнее. Другим для этого хватает пары секунд. В связи с этим распределение времени просмотра страницы было решено делать конфигурируемым, с возможностью выбора распределения для отдельных сайтов, больших наборов сайтов или унифицированный алгоритм для всех сайтов. В качестве самых базовых распределений были выбраны: . Константа . Равномерное . Нормальное (с обрезкой отрицательного конца) Далее делается предположение, что существует два типа просмотра страницы пользователем: . Беглый, при котором пользователей определяет, стоит ли ему углубляться в изучение материала, или необходимо искать другой источник - происходит в течении нескольких секунд (редко превышает временной промежуток в 10-20 секунд) - при большом количестве сайтов и усреднении пользователей можно предположить нормальное распределение с математическим ожиданием в районе 10, и дисперсией около 3,5 (= график распределения выглядит как вытянутая колба) . Глубокий просмотр - происходит после беглого осмотра, время, затраченное на него, сильно зависит от пользователя и содержания конкретной страницы. Снова, при большом количестве сайтов и усреднении пользователя логичным является использование нормального распределения, но в этот раз с большой дисперсией - из-за сильного разброса в содержимом сайтов. Колба распределения становится гораздо более пологая. Объединяя два упомянутых распределения - получается сумма нормальных распределений - новое распределение с 5ю параметрами. В программе реализована его упрощённый вид, с предположением что p = ½. Сумму двух нормальных распределений с весами p и 1-p соответственно можно
вычислить по формуле:
Далее было проведено исследование на реальных значениях, по данным
ресурса WebStat [23] (которые создатели сайта выложил в открытом доступе). В их
базе данных представлены значения - сколько времени пользователь находился на
сайте, и сколько страниц он за этот временной промежуток просмотрел. Формат
данных представлен в Таблице 3.
Таблица. 3. Часть статистики пользователей сайта web-stat.com [23]
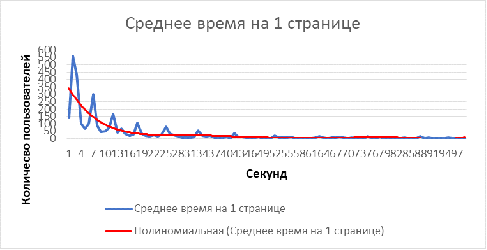
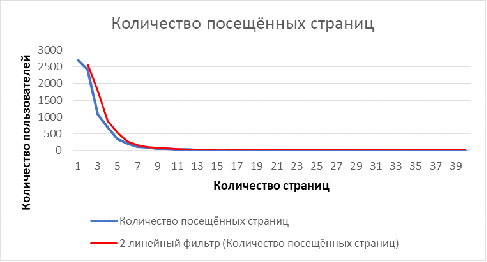
На Рисунках 6 и 7 представлено распределение времени на каждой странице и
количество посещённых страниц пользователями. Статистика основана на данных по
8000 пользователям. Синие линии показывают реальные значения количества
пользователей. Красные линии - усреднённые значения (в первом случае -
полиноминально среднее, во втором - среднее). Данные усреднённые линии
напоминаю экспоненциальное распределение. Подтверждение данной гипотезы на
Рисунке 8. Синяя линия - распределения вероятностей для каждой секунды в
промежутке от 1 до 50 - полученное путём деления количества пользователей,
которые были на странице данное количество времени и делёное на общее
количество пользователей.
Рисунок 6 Среднее время просмотра 1 страницы пользователём на сайте www.web-stat.com [23]
Рисунок 7 Количество посещённых страниц пользователями сайте www.web-stat.com [23]
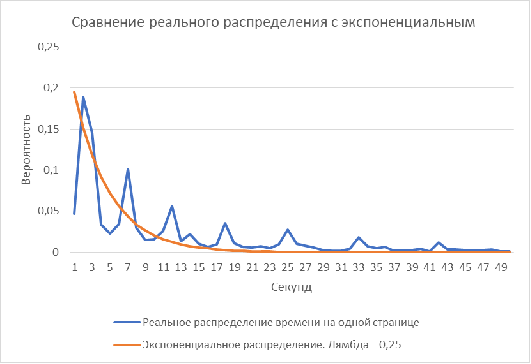
Рисунок 8. Сравнение реального распределения времени на одной странице (с
сайта www.web-stat.com [23]) с экспоненциальным
распределением
Основываясь на гипотезе о схожести данных в программу была добавлена возможность задавать время просмотра страниц с помощью экспоненциального распределения с варируемой лямбдой. Но статистические критерии схожести, например, критерий
Рисунок 9 Описание способа вычисления критерия хи-квадрат (#"896971.files/image012.gif"> (количество степеней свободы - 20) = 1211,81087 - статистически нельзя говорить о схожести этих распределений. Но эти две характеристик раздельные - т.е. возможно для одного сайта
использовать различные распределения для времени ожидания и для количества
страниц.
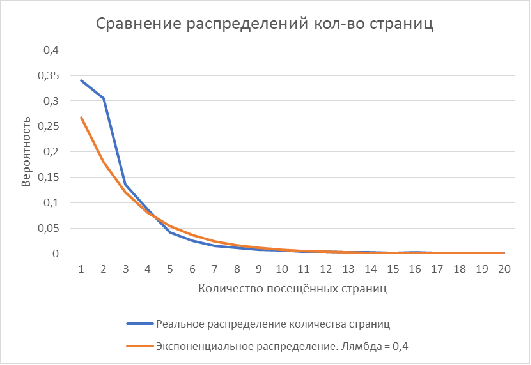
Рисунок 10. Сравнение реального и экспоненциального распределения (лямбда
= 0.4) на количество просмотренных пользователем страниц сайта www.web-stat.com
Ещё вводится дополнительная особенность: режим обхода страниц в сети «бесконечный сёрфинг» - когда нет ограничений на количество открываемых страниц. Данный режим работает по следующему алгоритму: . Задаётся начальная ссылка, открывается и добавляется время ожидания; . Сбор с данной страницы всех активных ссылок; . Выбор из списка ссылок одну (случайным образом); . Переход по выбранной ссылке, ожидание; . Повторение п.2. Выводы по второй главеВ второй главе был представлен способ моделирования поведения
пользователя, какие статистические распределения к этому применяются. Какие
способы выбора набора сайтов и страниц на сайтах, как они коррелируют с
реальным поведением пользователя в сети. Так же был представлен способ
генерации обращений к выбранным сайтам.
Глава 3. Выбор средств реализации программного продукта, проект/прототип программного продуктаВыбор средств реализации во многом зависел исключительно от Технического Задания, поскольку разрабатываемая система в дальнейшем должна будет стать уже подсистемой другой системы, разрабатываемой в Институте Системного Программирования РАН, которая включает в себя в целом работу с трафиком, с возможностью его захвата на различном оборудовании (в том числе и на специализированных высокоскоростных сетевых картах), его сохранение, обработка (снятие определённых заголовком с пакетов, классификация различными способами и т.д.). И, соответственно, следующим этапом является добавление функциональности по генерации нового, реалистичного сетевого трафика (возможность простого копирования ранее сохранённой трассы уже реализована). Поэтому базовым технологическим стеком является: 1. Python 3.4 . PyGTK 3 . WebKitGtk В дополнении к нему, для обеспечения работы логгирования и сбора и отображения статистик: 1. Rsyslog 2. Logstash 3. Elasticsearch 1.4 4. Kibana 3.0 Вся функциональная часть системы разработана в модульном архитектурном
подходе.
3.1 Описание модулей
Launcher Модуль для запуска всей системы в целом. На вход принимает путь к конфигурационному файлу системы, в котором указано количество запускаемых генераторов, их имена и пути к конфигурационным файлам. По полученным данным этот модуль запускает генераторы, как отдельные процессы. Пример конфигурационного файла: { "time_to_live": 10000, "processes": [ { "name":"Yandex_catalog", "config":"config/yandex_catalog.json" }, { "name":"Surfing", "config":"config/surfing.json" } ] } Generator На вход передаётся конфигурационный файл для генерации сетевого трафика, в котором указываются используемые распределения для времени и числа страниц на сайтах, методы выбора ссылок, списки сайтов и методы их генерации. Пример конфигурационного файла: { “user_agen”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1 Safari/603.1.30” “max_time_loading”: 50 "schemes": { "fast_going": { "page_generator": "site-scraping", "time_between_page": { "type": "uniform", "low_boundary": 1, "up_boundary": 5 }, "page_number":{ "type": "uniform", "low_boundary": 1, "up_boundary": 10 } } "sites":[ { "type": "loaded_list", "file_type": "xlsx", "file_name": "support_files/sitelist.xlsx", "worksheet":"List", "column":"A", "count_for_visit": 0, "scheme": "fast_going" } ] } Здесь необходимо ввести понятие «схема сайта» - будем подразумевать как JSON-объект, описывающий схему обхода некоторого количества сайтов (от одного и более), или описывающий метод бесконечного сёрфинга. Под каждую схему сайта создаётся отдельный поток. Одним общим окном для всех потоков, для симуляции графического отображения создаётся GTK окно. Worker Можно рассматривать как интерфейс. В общем случае подразумевает получение схемы сайта, и отвечает за его обработку, и генерацию последовательности ссылок и пауз. Затем отправляет полученные ссылки на Opener, и отвечает за корректную расстановку пауз. Имеет четыре наследника (во вложенном списке перечислены параметры для данной схемы сайта): . Infinity_surfing - задаётся начальная ссылка и распределение времени пауз между открытиями страниц. Далее до остановки переходит от страницы к другой странице, ссылка на которую находилось на предыдущей. 1.1. file_type - расширения файла .2. file_name - относительный путь к файле .3. worksheet - имя листа, на котором находится список .4. column - имя колонки в которой находится список .5. count_for_visit - количество сайтов из списка для посещения. Если 0 - то бесконечно открывать сайты по-кругу .6. scheme - схема обхода (из листа schemes) 2. Loaded_list - задаётся список сайтов (в текущем виде ожидает exel таблицу), и совершает последовательный обход сайтов из этого списка. Так же подразумевается открытие нескольких ссылок на каждом сайте 2.1. url - начальный сайт, точка входа в сёрфинг 2.2. scheme - схема обхода 3. Usual_site - открытие одного сайта, для которого совершается обход в соответствии с заданной схемы 3.1. url - сайт для обхода 3.2. scheme - схема обхода 4. Google Engine - задаётся список запросов (человеко-читаемых) к поисковой системе, количество сайтов для каждой выдачи и способ обхода каждого сайта из выдачи. 4.1. queries - лист запросов к поисковой системе 4.2. site_count - объект задающий распределение, определяющее количество сайтов из выдачи для посещения 4.3. scheme - схема обхода сайта Utils Различные методы, которые используется в других модулях. Например: сбор ссылок со страницы сайта, отправка запроса к google и т.п. Distribution Интерфейс для реализации различных распределений. В общем случае - на вход приходит описание распределения. Затем, при каждом обращении к объекту класса соответствующего распределения возвращается следующее число. Параметры распределения задаются с помощью конфигурационного файла, являясь составной частью параметра «scheme». Пример конфигурации для распределения времени между загрузкой отдельных страниц: "time_between_page": { "type": "uniform", "low_boundary": 1, "up_boundary": 5 }, - На данный момент реализованы все, указанные в п. 2.2 распределения: (в скобках указаны параметры для каждого распределения): 1. Fix (value) . Uniform (low_boundary, up_boundary) . Positive-normal (M,D) . Dual-normal (M1,D1,M2,D2) . Exponential (L) . Custom (array) Logger Вывод в rsyslog статистик о том, какие страницы открывались, время между страницами, и количество страниц на сайте (найденных и открытых). Вывод информации о неисправностях и ошибках в работе. Кофигурационный файл rsyslog: :msg,startswith,"PRCSS" /var/log/prcss.log :msg,startswith,"PRCSS" @@localhost:5544 :msg,startswith," PRCSS" /var/log/prcss.log :msg,startswith," PRCSS" @@localhost:5544
Конфигурационный файл Logstash: input { tcp { port => 5544 type => syslog } udp { port => 5544 type => syslog } }{ if [type] == "syslog" { grok { overwrite => "message" "message" => "^(?:<%{POSINT:syslog_pri}> ?)?%{SYSLOGTIMESTAMP:timestamp} %{IPORHOST:host} (?:%{PROG:program}(?:\[%{POSINT:pid}\])?:) ?PRCSS %{PROG:mess_type}%{GREEDYDATA:message}" } } syslog_pri { } date { # season to taste for your own syslog format(s) match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601" ] } } }{ stdout {codec => rubydebug} elasticsearch { host => localhost protocol => http } } Конфигурационный файл Elasticsearch: node.local: true.cors.allow-origin: "/.*/".cors.enabled:
true
3.2 Описание работы журналирования и сбора статистик
|