Материал: Разработка программного обеспечения системы синтеза парадигм слов английского языка
При этом соблюдаются следующие правила.
Правило 1 (основное). Односложные (т.е. состоящие из одного слога) прилагательные и двусложные прилагательные, оканчивающиеся на -y, -er, -ow, -le, образуют сравнительную степень при помощи суффикса -er, превосходную степень - при помощи суффикса -est.
Правило 2. В односложных прилагательных, оканчивающихся на одну согласную с предшествующим кратким гласным звуком, конечная согласная буква удваивается (чтобы сохранить закрытость слога). Например, big - bigger - biggest; thin - thinner - thinnest.
Правило 3. Если прилагательное оканчивается на -y с предшествующей согласной, то -y меняется на -i. Например, busy - busier - busiest; happy - happier - happiest
Примечание. Если перед -y стоит гласная, то -y остается без изменения. Например, grey - greyer - greyest.
Правило 4. Конечная гласная -e (немое e) перед суффиксами -er, -est опускается. Например, white - whiter - whitest.
Некоторые прилагательные в
английском языке <#"809154.files/image002.gif">
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- ссылка на класс, который используется в данном классе
Рисунок 4.1 - Схема организации классов ПО системы синтеза парадигм слов английского языка
Класс CTableDlg содержит в себе реализацию
главного окна программы, пользовательский интерфейс и обработчики событий от
элементов управления. В таблице 4.4 приведен список основных методов класса.
Таблица 4.4 - Список основных методов класса CTableDlg
|
Метод |
Описание |
|
void CTableDlg::OnCreate_Tree() |
Добавляет к дереву по строке элементы парадигмы начиная с 0 |
|
void CTableDlg::OnAddTree() |
Добавляет к существующей таблице данные из текстового файла |
|
void CTableDlg::OnSave_Tree() |
Сохраняет дерево |
|
void CTableDlg::OnLoad_Tree() |
Загружает дерево |
|
void CTableDlg::OnLemma_Find() |
Поиск леммы слова в дереве |
|
void CTableDlg::OnFind_Paradigm() |
Поиск парадигмы слова в дереве |
|
void CTableDlg::OnDel() |
Удаление из существующей таблицы данных, из текстового файла |
|
void CTableDlg::OnCancel() |
Выход |
Класс english_paradigm предназначен для
формирования файла парадигм английского языка. Входными данными является файл
со словарем начальных форм английских слов с метками для их словоизменения. В
результате работы методов этого класса (см. табл. 4.5) на выходе консольного
приложения создается файл в формате, требуемом библиотекой РДМА_ИПИИ, для
добавления полученных словоформ в дерево.
Таблица 4.5 - Список основных методов класса english_paradigm
|
Метод |
Описание |
|
bool Noun_paradigm(char *str) |
Формирование парадигм существительных |
|
bool Verb_paradigm(char *str) |
Формирование парадигм глаголов |
|
bool Adj_paradigm(char *str) |
Формирование парадигм прилагательных |
Класс CTable2 принадлежит библиотеке РДМА_ИПИИ,
разработанной отделом распознавания речи ИПИИ. В таблице 4.6 приведены функции
очистки, загрузки, модификации и сохранения словарной базы, реализованные в
этом классе.
Таблица 4.6 - Список основных методов класса CTable2
|
Метод |
Описание |
|
Функции очистки, загрузки и сохранения словарной базы (в случае успешного завершения возвращают нулевое значение) |
|
|
void Release() |
очищает словарную базу |
|
UINT LoadMem(char * Path). |
загружает в память дерево строк, сокращенную таблицу парадигм, таблицу связи дерева и сокращенной таблицы парадигм, а также индексы к ним |
|
UINT LoadDisk(char * Path) |
загружает таблицу связи дерева и сокращенной таблицы парадигм, а также индексы в память и устанавливает флажок, указывающий на то, что остальные данные читаются с диска. При этом переменная Path указывает путь к папке, хранящей файлы словарной базы: tab.dat, tree.dat, connect.dat. |
|
UINT SaveMem(char * Path) - функция |
сохраняет в папку по указанному пути Path данные словарной базы, хранимые в памяти. |
|
UINT SaveDisk(char * Path) |
сохраняет в папку по указанному пути Path данные словарной базы, частично хранимые в памяти, а частично на диске |
|
Функции модификации словарной базы |
|
|
UINT InsertRows (MyChar* wrdBud,MyChar* wrdUd,UINT LemmaNum,UINT MI,BOOL InsertRows); |
функция добавления словоформы в словарную базу. Параметры: wrdBud - строка написания словоформы без ударения, wrdUd - строка написания словоформы с учётом ударения, LemmaNum - номер в словарной базе леммы данной словоформы, MI - число, в котором с помощью набора битовых полей закодирована морфологическая информация о словоформе. При добавлении словоформы, которая является собственной леммой, в поле LemmaNum должен фигурировать номер записи в таблице словоформ, в которую будет помещена эта добавляемая словоформа. Для получения этого значения вызывают вспомогательную функцию UINT GetNextLemNum(). |
|
Метод |
Описание |
|
UINT DeleteRow (UINT Index,BOOL f) |
функция удаляет словоформы из словарной базы. Параметры: Index - номер словоформы в базе. |
|
Функции получения информации о словоформах |
|
|
UINT FindLemma(MyChar *word, CStringArray& Lemma,CUIntArray &ResLemm,CUIntArray &MI) |
Находит леммы для строки word. Результаты выполнения функции: Lemma - массив написаний леммы для словоформ, чьё написание совпадает со строкой word, ResLemm - массив номеров лемм в словарной базе (необходим для установления принадлежности словоформы конкретной парадигме), MI - массив значений морфологической информации словоформ с указанным написанием. |
|
void TranslateMI(UINT Mi, char*str) |
записывает в строку str текстовую расшифровку числового значения морфологической информации. |
|
UINT FindParadigm(MyChar *word, CStringArray& ParadigmBud,CStringArray& ParadigmUd,CUIntArray &MI,CUIntArray &TabNums,CUIntArray &LemmNums) |
находит парадигмы, содержащие словоформы с написанием word. Результаты выполнения функции: ParadigmBud (ParadigmUd) - массив написаний словоформ найденных парадигм без учёта ударения (с учётом ударения), MI - массив значений морфологической информации этих словоформ, LemmNums - массив номеров лемм в словарной базе (необходим для установления принадлежности словоформы конкретной парадигме). |
|
UINT GetWordNum (char* word) |
возвращает уникальный номер написания словоформы в базе. Возвращаемое значение - 0, если база не содержит словоформы с написанием word, или положительное число - идентификатор строки word в базе. |
|
UINT GetWord (UINT treeNum, char* str, int &buff_Size) |
возвращает написание словоформы, которое имеет в базе идентификатор treeNum. Передаваемые параметры: treeNum - идентификатор искомой строки; str - буффер для искомой строки; buff_Size - размер буфера для искомой строки. Возвращаемое значение: 0 - при успешном завершении функции, при этом str - содержит искомую строку; положительное число - в случае ошибки, когда параметр treeNum превышает значение наибольшего идентификатора строки в базе; -1 - в случае ошибки, когда размер буфера buff_Size меньше или равен длине искомой строки, при этом в параметр buff_Size функция записывает нужный размер буфера; -2 - в случае ошибки, когда база не содержит ни одной строки. |
|
Метод |
Описание |
|
Функции получения информации о словарной базе |
|
|
UINT GetTreeSize() |
позволяет определить количество строковых величин, хранимых в дереве строк. |
|
UINT GetRowsCount() |
|
|
void Evaluate(char *FilePath) |
функция сохраняет в файл по указанному пути информацию о затратах памяти на хранение различных структур данных словарной базы. |
|
Служебные функции |
|
|
ReleasestringArr( vector<string>* &ParadigmUd) |
используются для очистки заполняемых функциями библиотеки переменных-указателей на vector<string> и vector<unsigned int>, соответственно. |
|
ReleaseCUIntArr( vector <unsigned int>*& TabNums) |
|
Вызов функций класса CTable2 происходит в
методах класса CTableDlg, фрагменты листинга, содержащего обращения к функцям
библиотеки РДМА_ИПИИ, приведены в приложении Б.
5. Анализ результатов функционирования системы
Комплексное тестирование необходимо для поисков несоответствия системы ее исходным целям. На стадии тестирования были проверены все «исключительные» ситуации, которые могут возникнуть при дальнейшем использовании данного программного продукта, будь то попытка открыть файл неверного формата, попытки синтеза парадигмы для леммы без указания или некорректного указания грамматической информации для словобразования и т.д. В основе обработки «исключительных» ситуаций, было предприняты следующие меры: неверные шаги пользователей будут сопровождаться появлением модальных диалоговых окон с информацией об ошибках пользователя или отключением соответствующих элементов управления. Ниже приведено более детальное описание тестирования.
Для запуска консольного приложения необходимо запустить исполняемый файл english_paradigm.exe. Для его корректной работы необходим размеченный словарь начальных форм слов английского языка, хранящийся в файле Engl_lem.txt в той же директории, что и english_paradigm.exe, формат разметки приведен в описании формата входных данных (пункт 3.2). Возможны следующие исключительные ситуации:
) файл Engl_lem.txt не найден;
) в файле словаря есть некорректно введенные записи (например, неверно введен буквенный символ, стоящий после слова, указывающий на его принадлежность к определенной части речи).
В первом случае система выдаст сообщение об ошибке (рис. 5.1), во втором -некорректные записи не обрабатываются, но предусмотрен их вывод файл Erorr.txt.
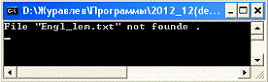
Рисунок 5.1 - Сообщение системы в случае
отсутствия словаря начальных форм
Если файл Engl_lem.txt не содержит ошибок, то консольное приложение строит парадигмы слов словаря начальных форм, формирует файл Engl_par.dat в текущей директории и автоматически закрывается.
Для формирования базы данных словоформ в виде цифрового дерева, хранящего строковые величины, необходимо запустить исполняемый файл table.exe. Откроется диалоговое окно приложения TABLE (рис. В.1), содержащее поле ввода и кнопки «Создать/Добавить», «Загрузить», «Сохранить», «Найти парадигму» и «Выход».
В режиме наполнения на основе парадигм, считываемых из файла Engl_par.dat, создается дерево строк, сокращенная таблица парадигм, таблица связи дерева и сокращенной таблицы парадигм, которые хранятся в подкаталоге «Tree» в файлах tab.dat, tree.dat, connect.dat соответственно. Исключительная ситуация возможна при отсутствии Engl_par.dat, т.е. если консольное приложение не отработало. В этом случае по нажатии на кнопку
«Создать/Добавить» появляется сообщение об ошибке (рис. 5.2);
«Загрузить» загружается последняя сохраненная в файлах tab.dat, tree.dat, connect.dat база словоформ;
«Сохранить» сохраняется пустое дерево строк;
«Найти парадигму» появляется сообщение об ошибке
(рис. 5.3).
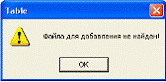
Рисунок 5.2 - Сообщение системы об отсутствии
файла Engl_par.dat, содержащего парадигмы слов английского языка
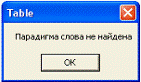
Рисунок 5.3 - Сообщение системы в случае
отсутствия леммы в словаре начальных форм
Если файл Engl_par.dat сформирован, то на его основе можно создать базу словоформ в виде дерева с помощью кнопки «Создать/Добавить», чтобы ее сохранить, необходимо нажать кнопку «Сохранить». Созданную базу словоформ можно также добавить в предварительно загруженное дерево с помощью той же кнопки «Добавить». Для чего необходимо выполнить последовательность команд «Загрузить»-« Создать/Добавить»-«Сохранить».
В режиме поиска парадигмы, в который система переходит по нажатии на кнопку «Найти парадигму», возможны следующие исключительные ситуации:
) нет базы словоформ;
) нет введенной леммы в базе словоформ;
В обоих случаях система выдаст сообщение об ошибке (рис. 5.3).
Если парадигма успешно найдена, то в поле вывода
появится список всех словоформ, образующих эту парадигму, с соответствующей МИ
(рис. В.2).
Выводы
В результате выполнения курсовой работы был сделан достаточно полный обзор методов машинной морфологии и способов представления МИ, сформулирована постановка задачи, спроектирована и программно реализована система синтеза парадигм слов английского языка, проведено комплексное тестирование результатов ее работы, что необходимо для выявления ошибок в структуре алгоритмов программы, структуре входных и внутренних данных, а также для ликвидации конфликтных ситуаций с другим программным обеспечением. Это позволило сделать следующие выводы.
Морфологический компонент - неотъемлемая частью интеллектуальных АОТ-систем. Морфологический анализ/синтез неосуществим без машинного грамматического словаря, его использование позволяет проводить полный анализ словоформы, оперируя большим числом грамматических признаков, и повысить его точность. В связи с этим актуальность выбранной темы не вызывает сомнений.
Наиболее оптимальный способ представления МИ, сочетающий в себе удобства обработки и экономное хранение, - в виде битовых полей. Этот способ задания МИ реализован в модуле декларативного морфологического анализа слов русского языка РДМА_ИПИИ. Модуль снабжен средствами быстрого поиска строковых величин в большом массиве строк. В связи с этим для создания и хранения базы словоформ английского языка, а также быстрого поиска парадигм в созданной базе использовались функции библиотеки РДМА_ИПИИ.
Разработанное в результате выполнения курсовой работы ПО состоит из трех модулей. Помимо библиотеки РДМА_ИПИИ в систему входят: консольное приложение, позволяющее загрузить словарь начальных форм английских слов, содержащий грамматическую информацию, необходимую для словоизменения, и выполняющее синтез парадигм лемм этого словаря; приложение TABLE, предназначенное для адаптации под английский язык функций хранения базы словоформ и быстрого поиска парадигм в ней, реализованных в библиотеке РДМА_ИПИИ. ПО, имеющее такую архитектуру, обеспечивает следующие возможности: чтение и загрузка файла начальных форм английских слов; очистка, загрузка, модификация и сохранение базы английских словоформ; получение парадигмы с указанием МИ каждой словоформы по введенной пользователем лемме.
Тестирование ПО система синтеза парадигм английского языка не выявило несоответствие системы ее исходным целям, ошибок в структуре алгоритма программы, структуре входных и внутренних данных, а также конфликтных ситуаций с другим ПО.
Разработанный программный продукт может
использоваться при создании средств морфологической обработки интеллектуальных
систем понимания и автоматического анализа текстов на английском языке. Кроме
того, созданную базу данных английских словоформ можно использовать для точной
оценки морфологической информации словоформы в задачах поверхностного
семантико-синтаксического анализа.
Список ссылок
1. Чесебиев И.А. Понимание и синтез текста компьютером. [Электронный ресурс]. URL : http//yabs. yandex.ru/ /resourse/bb/dif
. Ножов И.М. Процессор автоматизированного морфологического анализа без словаря. Деревья и корреляция. //Диалог’2000. Труды конференции - Протвино, 2000. Т.2. С. 284-290.
3. А. А. Зализняк. Грамматический словарь русского языка. Словоизменение. <#"809154.files/image008.gif">
Рисунок В.1 - Главное окно приложения Table.exe
Для создания дерева словоформ на основе парадигм, сохраненных в файле Engl_par.dat, необходимо нажать кнопку «Создать/Добавить». Созданное дерево хранится в кэше до закрытия программы. При желании его можно сохранить на диск нажатием на кнопку «Сохранить». При этом дерево автоматически сохраняется в файлах tab.dat, tree.dat, connect.dat, которые находятся в подкаталоге «Tree» и изначально являются пустыми.
Для модификации словаря словоформ (в случае изменения словаря начальных форм Engl_lem.txt путем добавления/удаления записей и перезапуска консольного приложения), необходимо загрузить существующее дерево с помощью кнопки «Загрузить», после чего нажатием на кнопку «Создать/Добавить» в загруженное дерево добавляются парадигмы из обновленного файла Engl_par.dat. Полученный результат сохраняется на диск нажатием на кнопку «Сохранить».
Поиск парадигмы осуществляется в загруженном
дереве, в случае его отсутствия - в кэше. Для чего пользователю в поле ввода
необходимо ввести лемму и нажать на кнопку «Найти парадигму». В случае
успешного поиска парадигма выводится в поле вывода в виде списка словоформ с
соответствующей МИ (рис. В.2). Если лемма отсутствует в базе начальных форм, то
появляется сообщение об ошибке.
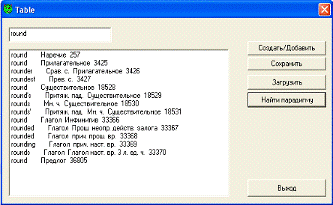
Рисунок В.2 - Успешное завершение поиска парадигмы для леммы «round»