Материал: Разработка базы данных учета товарно-материальных ценностей
Металлочерепица поставляется на строительные объекты с размером листов, предварительно согласованным с продавцом. Габариты листа устанавливают по результатам тщательного обмера каждого ската крыши.
Основным размером является расстояние от карниза до конька, причем обязательно в учет идет размер свеса нижнего ряда черепицы, который должен составлять около 40 мм.
Если геометрия крыши слишком сложна, то практикуется вызов специалистов компании-продавца, которые при помощи специальных компьютерных программ производят все необходимые расчеты быстро и четко.
Раскрой металлочерепичных листов, как правило, производят с помощью специальных рубящих электроножниц. Применение отрезных устройств типа болгарок, использующих в качестве режущего элемента абразивный круг, запрещается, поскольку в процессе раскроя абразивный круг перегревает поверхность листа в области реза, а это ведет к выгоранию с последующим отслаиванием защитного слоя.
Помимо этого, искры способны повредить остальное покрытие листа.
Непосредственно перед укладкой кровли должно быть выполнено заземление крыши из металлочерепицы, поскольку данный материал способен проводить электрический ток.
Для расчета потребности в материале и его раскрое используется
специальное программное обеспечение.
Рисунок 5 - Таблица для расчета площади кровли
Компьютерная программа "Кровля Профи" предназначена для расчета потребности кровельного (фасадного) материала, доборных элементов и саморезов на кровлю (фасады) различной конфигурации с представлением схемы укладки листов на каждом скате (фасаде).
С помощью программы можно рассчитывать металлочерепицу "на заказ", металлочерепицу "со склада", одномодульную металлочерепицу (типа "Метробонд"), натуральную черепицу, профнастил и листовой материал (шифер и т.п.), фасадные материалы типа сайдинг. При расчете металлочерепицы программа позволяет учитывать так называемые "технологически невыполнимые" размеры листов при поставке "на заказ", а также складские остатки и складской типоряд длин листов. При расчете материала, который отпускается заказчику целыми листами (металлочерепица "со склада", листовой материал, сайдинг "со склада"), программа предлагает схему раскроя листов для использования обрезков.
Корректность работы данного алгоритма подтверждена многолетней
эксплуатацией этих программ ведущими кровельными фирмами России, Беларуси,
Казахстана, Латвии и Молдовы.
2.2 Вычислительное оборудование, применяемое в работе
организации
В рабочем процессе ИП Литвинов А.Ю. заняты 10 сотрудников. Количество
используемого вычислительного оборудования - 7 единиц, включая сервер. Основной
используемой платформой персональных компьютеров является платформа Intel.
Конфигурации типичного системного блока представлена в таблице.
Таблица 1 - Типичная конфигурация ПК
Название компонента
Тип компонента
Материнская плата
Asus p5k
Процессор
Intel Core i 3 255
ОЗУ
2 Gb DDR III 1333 MGz
Жёсткий диск
640 Gb SATA II 7200 rpm
Видеокарта
NVIDIA GF 620
Корпус
FSP Mini Tower
Блок питания
FSP 350 Wt
Как видим, это конфигурация средней производительности на конец 2011,
начало 2012 года, без модернизации такой конфигурации хватит для нормальной
работы до 2014-2015 г.г.
Основной операционной системой является Microsoft Windows 7, так же по
программе информатизации села на части ПК установлена операционная система
Ubuntu, а на сервере ОС Ubuntu Server.
В качестве офисного редактора используется свободный редактор Open
Office, так же в целях совместимости с федеральным документооборотом, на одном
из компьютеров установлен офисный пакет от Microsoft - Office 2010.
Для передачи сообщений по электронным каналам связи используется система
СТЭК-Траст с системой криптографической защиты Крипто-ПРО.
Хранение характеризуется двумя основными параметрами: емкость хранилища
данных и скорость предоставления данных (отклик на запрос), а также степенью
резервирования и дублирования, масштабируемостью систем хранения.
Существует несколько способов увеличения емкости хранения данных:
Установка дополнительных жестких дисков.
Установка дополнительного файлового сервера или системы хранения данных
(СХД).
Использование ленточных и магнитооптических устройств для архивации
информации.
Дополнительные жесткие диски. Установка в файловый сервер новых
накопителей на жестких дисках, не требующих остановки работы сервера и
проведение специальных настроек сервера и дисковой системы.
Дополнительный файловый сервер. С технологической точки зрения установка
дополнительного файлового сервера достаточно эффективна, т.к. при этом
достигается максимальное повышение скорости передачи данных и рост количества
одновременно обрабатываемых запросов.
При резервном копировании данных (для восстановления функционирования
сети в случае сбоя) объемы сохраняемых файлов (архивных электронных документов)
постоянно растут и хранить на дисках файлового сервера такие объемы данных
достаточно дорого.
Ленточные или магнитооптические (МО) накопители. Эти устройства применяют
для удешевления системы хранения резервной или редко используемой информации.
Для хранилищ большого объема данных (архивного хранения электронных документов)
целесообразно применять системы хранения, оснащенные автозагрузчиками.
Автозагрузчики являются устройствами со сменными носителями информации,
благодаря чему могут хранить достаточно большой (от сотен гигабайт) объем
данных. Автозагрузчик состоит из отсеков (до десяти), в которых хранятся
картриджи, и роботизированного механизма смены картриджей в дисководах (их, как
правило, не больше двух). Применение таких накопителей значительно уменьшает
объем рутинной работы по замене носителей, например, 8-секционный автозагрузчик
позволяет копировать резервные данные понедельника на первый картридж, вторника
- на второй и т. д. При этом картриджи не нужно менять каждый день (максимум
раз в неделю). Автозагрузчики отличаются большими объемами хранимой информации
и высокой скоростью предоставления информации, а также возможностью
одновременно обслуживать большее количество запросов.
Перспективным является применение иерархических систем хранения,
сочетающие в себе дисковые и ленточные подсистемы и имеющие автоматические
механизмы перемещения данных между ними на основе частоты доступа.
2.3 Спецификация оборудования,
необходимого для нормального функционирования базы данных учета ТМЦ для ИП
ЛИТВИНОВА А.Ю. фирма «Жесть»
В качестве основной платформы для автоматизации предприятия используется
платформа IBM PC или Wintel.
Для внедрения системы учета товарно-материальных ценностей в организации
необходимо произвести модернизацию оборудования, которая будет заключаться к
закупке одного рабочего места оператора баз данных и покупки нового сервера баз
данных.
Необходимая аппаратная конфигурация персонального компьютера:
Таблица 2 - Основная конфигурация персонального компьютера
Название компонента
Характеристика
Процессор
Intel Pentium 2020
Материнская плата
GA-V67
Оперативная память
DDR III PC10600 2 Gb
Видеокарта
интегрированнная
Жёсткий диск
500 Gb
Блок питания
350 Wt
Конфигурация сервера:
Таблица 3 - Конфигурация сервера
Название компонента
Характеристика
Процессор
Intel Xeon E4300
Материнская плата
Intel LGA 2011
Оперативная память
DDR III PC18000 12 Gb
Системный жёсткий диск
128 Gb SSD Intel 730
Набор накопителей
RAID 5+2 2048 Gb
Блок питания
350 Wt
Большой объем необходимых данных о материалах, хранящихся на складе
привело к проблемам обработки информации: большого количества данных о
материалах, хранящихся в бумажном виде, упорядоченности этих данных,
распределение только необходимой информации между разными отделами.
Приведенные выше проблемы повлекли за собой необходимость автоматизации.
Было рассмотрено несколько программных продуктов (1С:Торговля и склад, Баланс+
и др.), предназначенных для автоматизации складского учета товарно-материальных
ценностей. Все они по разным причинам не удовлетворяли потребностям
(дороговизна, слишком сложный интерфейс и т.д.).
Создание модели приложения для автоматизации учета ТМЦ склада решило все
эти проблемы:
внесение информации в базу данных вносится одним человеком, который имеет
полный доступ к конфиденциальной информации;
реализация быстрого поиска информации об остатках материалов на складе на
начало месяца, изменения данных за период, а так же на конец месяца, внутреннее
перемещение;
при возможности установки компьютерной техники в других отделах АХЧ, эти
отделы также могут использовать информацию данной БД.
Цель работы.
Разработать программный продукт «База данных учета ТМЦ для ИП Литвинова
А.Ю. фирма «ЖЕСТЬ»».
Задачи.
Для достижения поставленной цели в работе нужно решить следующие задачи:
Провести анализ предметной области;
Построить инфологическую и логическую модели;
Спроектировать и реализовать реляционную базу данных;
Разработать программный комплекс, выполняющий следующие функции:
осуществление основных операций управления данными (ввод, хранение,
обработка);
составление отчетов и вывода их на печать.
Объект исследования.
Деятельность административно-хозяйственной части ИП Литвинов А.Ю.
Предмет исследования.
Автоматизация процесса учета товарно-материальных ценностей.
Первым этапом и самым главным этапом в процессе проектирования и создания
базы данных, является разработка инфологической модели.
Инфологическая модель применяется на втором этапе проектирования БД, то
есть после словесного описания предметной области. Зачем нужна инфологическая
модель и какую пользу она дает проектировщикам? Еще раз хотим напомнить, что
процесс проектирования длительный, он требует обсуждений с заказчиком, со
специалистами в предметной области. Наконец, при разработке серьезных
корпоративных информационных систем проект базы данных является тем
фундаментом, на котором строится вся система в целом, и вопрос о возможном
кредитовании часто решается экспертами банка на основании именно грамотно
сделанного инфологического проекта БД. Следовательно, инфологическая модель
должна включать такое формализованное описание предметной области, которое
легко будет "читаться" не только специалистами по базам данных. И это
описание должно быть настолько емким, чтобы можно было оценить глубину и
корректность проработки проекта БД, и конечно, как говорилось раньше, оно не
должно быть привязано к конкретной СУБД. Выбор СУБД - это отдельная задача, для
корректного ее решения необходимо иметь проект, который не привязан ни к какой
конкретной СУБД.
Инфологическое проектирование прежде всего связано с попыткой
представления семантики предметной области в модели БД. Реляционная модель
данных в силу своей простоты и лаконичности не позволяет отобразить семантику,
то есть смысл предметной области. Ранние теоретико-графовые модели в большей
степени отображали семантику предметной области. Они в явном виде определяли
иерархические связи между объектами предметной области.
Проблема представления семантики давно интересовала разработчиков, и в
семидесятых годах было предложено несколько моделей данных, названных
семантическими моделями. К ним можно отнести семантическую модель данных,
предложенную Хаммером ( Hammer ) и Мак-Леоном ( McLeon ) в 1981 году,
функциональную модель данных Шипмана ( Shipman ), также созданную в 1981 году,
модель "сущность-связь", предложенную Ченом ( Chen ) в 1976 году, и
ряд других моделей. У всех моделей были свои положительные и отрицательные
стороны, но испытание временем выдержала только последняя. И в настоящий момент
именно модель Чена "сущность-связь", или "Entity
Relationship", стала фактическим стандартом при инфологическом
моделировании баз данных. Общепринятым стало сокращенное название ER-модель,
большинство современных CASE-средств содержат инструментальные средства для
описания данных в формализме этой модели. Кроме того, разработаны методы
автоматического преобразования проекта БД из ER-модели в реляционную, при этом
преобразование выполняется в даталогическую модель, соответствующую конкретной
СУБД. Все CASE-системы имеют развитые средства документирования процесса
разработки БД, автоматические генераторы отчетов позволяют подготовить отчет о
текущем состоянии проекта БД с подробным описанием объектов БД и их отношений
как в графическом виде, так и в виде готовых стандартных печатных отчетов, что
существенно облегчает ведение проекта.
В настоящий момент не существует единой общепринятой системы обозначений
для ER-модели и разные CASE-системы используют разные графические нотации, но
разобравшись в одной, можно легко понять и другие нотации.
Рисунок 6 - Инфологическая модель базы данных
Для того чтобы база данных полно и правильно отражала предметную область,
проектировщик базы данных должен хорошо представлять все стороны предметной
области и уметь отобразить их в базе данных. Поэтому прежде чем начинать
проектирование необходимо разобраться, как функционирует предметная область,
для отображения которой создается база данных. Предметная область должна быть
предварительно описана в виде схем. Описание предметной области с
использованием искусственно формализованных средств называют инфологическим
моделированием. Данное описание не зависит от используемых программных средств.
Инфологическая модель строится вне зависимости от того, будет ли в дальнейшем
использована какая-либо СУБД или иным программным средством..
Сущность - некоторый обособленный объект или событие моделируемой
системы, имеющий определенный набор свойств - атрибутов. Отдельный элемент
этого множества называется "экземпляром сущности". Каждый экземпляр
сущности обладает набором характеристик, которые однозначно идентифицируют
каждый образец сущности и может обладать любым количеством связей с другими
сущностями.
Определение сущностей и атрибутов:
Для проектируемой базы данных понадобятся следующие сущности:
Таблица 4 - Атрибуты сущности «Поставщик»
Имя атрибута
Описание
КодПост
Внутренний служебный код для однозначной идентификации
поставщика
Название
Название организации
Адрес
Точный почтовый адрес
Контактная информация
Отчество сотрудника
Обращаться к
Фамилия, имя, отчество, должность и контактные данные
ответственного сотрудника
банковские реквизиты
банковские реквизиты для оплаты
Таблица 5 - Атрибуты сущности «ТМЦ» (Товароматериальные ценности)
Имя атрибута
Описание
Код
Внутренний служебный код для однозначной идентификации
товара
Название
Наименование продукции
Единица измерения
Единица измерения
Цена
Цена за единицу измерения
Количество
Количество товара
стоимость
Стоимость товара
Дата
Дата поступления
кодСчета
Счет согласно «Плана счетов бухгалтерского учёта»
КодПост
код поставщика
Номер партии
Номер партии прихода
номенклатура
номенклатурный номер товара
Кодификатор
Кодификатор
Склад
Место хранения товара
Таблица 6 - Атрибуты сущности «Счет»
Имя атрибута
Описание
кодСчета
Внутренний служебный код для однозначной идентификации
счета
Счет
Номер счета
Название
Наименование счета
Субсчет
Номер субсчета
Название_суб
Наименование субсчета
Таблица 7 - Атрибуты сущности «Кодификатор»
3. ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ БАЗЫ ДАННЫХ УЧЕТА ТМЦ ДЛЯ ИП
ЛИТВИНОВА А.Ю. ФИРМА «ЖЕСТЬ»
3.1 Обоснование актуальности разработки базы данных учета ТМЦ
3.2 Построение моделей базы данных для учета ТМЦ
3.2.1 Разработка инфологической модели
Описание
Кодификатор
код кодификатора
раздел
Номер счета
подраздел
Наименование счета
Таблица 8 - Атрибуты сущности «Убытие»
|
Имя атрибута |
Описание |
|
Код |
Внутренний служебный код для однозначной идентификации товара |
|
Название |
Наименование продукции |
|
Единица измерения |
Единица измерения |
|
Цена |
Цена за единицу измерения |
|
Дата |
Дата убытия |
|
Количество |
Количество товара |
|
Стоимость |
Стоимость отпущенного товара |
|
Номер накладной |
Номер накладной расхода |
.2.2 Логическая модель БД информационной системы для автоматизации поступления ТМЦ на склад
В логической модели базы данных установлены три родительские сущности: «Постащик», «Счет» и «Кодификатор», которые связаны с ТМЦ связями один ко многим по ключевым полям. В свою очередь из склада ТМЦ выдаются пользователям, что отображается как создание идентифицирующей связи один ко многим. Это значит, что во всех случаях один экземпляр первой сущности взаимодействует с несколькими экземплярами другой сущности. Взаимосвязи отображаются линиями, соединяющими две сущности, Каждая сущность делится на 2 группы. В первой группе находятся атрибуты, называемые первичным ключом. Первичный ключ - это набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Первичный ключ нужен для того, чтобы от него создавать связи между другими таблицами.
При создании сущности необходимо выделить атрибуты, которые могут стать первичным ключом (потенциальные ключи), затем произвести отбор атрибутов, следуя следующим рекомендациям:
первичный ключ должен быть подобран таким образом, чтобы по значениям атрибутов, в него включенных, можно было точно идентифицировать экземпляр сущности;
никакой из атрибутов первичного ключа не должен иметь нулевое значение;
значения атрибутов первичного ключа не должны меняться. Если значение изменилось, значит, это уже другой экземпляр сущности.
Не ключевые атрибуты располагаются под чертой, в области данных.
На диаграмме рядом со связью отражается ее имя, показывающее отношение между сущностями. При проведении связи между сущностями первичный ключ передается или мигрирует в дочернюю сущность.
На следующем этапе построения логической модели определяем ключевые атрибуты и типы атрибутов. Типы атрибутов представлены в таблице (номер накладной в данном случае текстовый).
Далее проводим нормализацию базы данных.
Нормализация - процесс проверки и
реорганизации сущностей и атрибутов с целью удовлетворения требований к
реляционной модели данных. Нормализация позволяет быть уверенным, что каждый
атрибут определен для своей сущности, значительно сократить объем памяти для
хранения данных.
Таблица 9 - Типы атрибутов
Атрибут
Тип
КодПост
Number
Название
String
Адрес
String
Контактная информация
String
Обращаться к
String
банковские реквизиты
String
Код
Numeric
Единица измерения
String
Цена
MONEY(,)
Количество
Number
стоимость
MONEY(,)
Дата
Date()
кодСчета
Number
КодПост
Number
Номер партии
String
номенклатура
String
Кодификатор
String
Склад
String
Счет
String
Субсчет
String
Название_суб
String
раздел
String
подраздел
String
Номер накладной
String
Для рассмотрения видов нормальных форм
введем понятия функциональной и полной функциональной зависимости.
Функциональная
зависимость
Атрибут В сущности Е функционально зависит
от атрибута А сущности Е, если и только если каждое значение А в Е связало с
ним точно одно значение В в E. Другими словами, А однозначно определяет В.
Полная функциональная
зависимость
Атрибут Е сущности В полностью
функционально зависит от ряда атрибутов А сущности Е, если и только если В
функционально зависит от А и не зависит ни от какого подряда А.
Существуют следующие виды нормальных форм:
Первая нормальная форма (1NF). Сущность Е
находится в первой нормальной форме, если и только если все атрибуты содержат
только атомарные значения. Среди атрибутов не должно встречаться повторяющихся
групп, т. е. нескольких значений для каждого экземпляра.
Вторая нормальная форма (2NF). Сущность Е
находится во второй нормальной форме, если она находится в первой нормальной
форме, и каждый не ключевой атрибут полностью зависит от первичного ключа, т.
е. не существует зависимостей от части ключа.
Третья нормальная форма (3NF). Сущность Е
находится в третьей нормальной форме, если она находится во второй нормальной
форме, и не ключевые атрибуты сущности Е зависят от других атрибутов Е.
После третьей нормальной формы существуют
нормальная форма Бойсса-Кодда, четвертая и пятая нормальные формы. На практике
ограничиваются приведением к третьей нормальной форме. Часто после проведения
нормализации все взаимосвязи данных становятся правильно определены, модель
данных становится легче поддерживать. Однако нормализация не ведет к повышению
производительности системы в целом, поэтому при создании физической модели в
целях повышения производительности приходится сознательно отходить от
нормальных форм, чтобы использовать возможности конкретного компьютера. Такой
процесс называется денормализацией.обеспечивает только поддержку нормализации,
но не содержит в себе алгоритмов, автоматически преобразующих модель данных из
одной формы в другую. Erwin поддерживает первую нормальную форму.
В модели каждая сущность или атрибут
идентифицируется с помощью имени. В Erwin поддерживает корректность имен
следующим образом:
отмечает повторное использование имени
сущности и атрибута;
не позволяет внести в сущность более
одного внешнего ключа;
запрещает присвоение неуникальных имен
атрибутов внутри одной модели, соблюдая правило «в одном месте - один факт».
Теперь нормализуем полученную базу данных
до третьей нормальной формы. Для приведения базы данных в первую нормальную
форму необходимо выполнить условие, при котором все атрибуты содержат атомарные
значения. Рассматривая все сущности БД можно убедиться, что все атрибуты
содержат атомарные значения и, следовательно, БД находится в первой нормальной
форме.
Проверим соответствие БД второй нормальной
форме. Все не ключевые атрибуты полностью должны зависеть от первичного ключа.
Это условие выполняется для всех сущностей БД, следовательно, делаем вывод о
том, что она находится уже и во второй нормальной форме.
Для приведения БД к третьей нормальной
форме необходимо обеспечить отсутствие транзитивных зависимостей не ключевых
атрибутов. Получим БД в третьей нормальной форме, так как транзитивных зависимостей
не ключевых атрибутов нет. Из этого следует, что полученная логическая модель
базы данных не изменится (рисунок 6).
В физической модели каждой сущности будет
соответствовать таблица базы данных, а каждому атрибуту - поле таблицы. Имена
таблиц и полей лучше задавать латинскими буквами и достаточно короткими для
удобства программирования и совместимости с системами, не поддерживающими
кириллицу. Поэтому названия полей, указанные кириллицей необходимо переименовать.
Рисунок 7 - Исходная модель
Рисунок 8 - Откорректированная модель
По готовой физической схеме можно
сгенерировать скрипты для выбранной СУБД.
Для реализации физической базы данных
будем использовать СУБД MySQL, входящую в установочный комплект XAMPP. Для создания связанных
таблиц в СУБД будем использовать графическую утилиту phpmyadmin.
Процесс создания таблиц в базе данных
представлен на рисунках ниже.
Рисунок 9 - Главное окно phpmyadmin
Рисунок 10 - Создание новой базы данных
Рисунок 11 - Создание таблицы «поставщик»
базы данных
Рисунок 12 - Создание таблицы «счет» базы
данных
Рисунок 13 - Создание таблицы
«кодификатор» базы данных
Рисунок 14 - Создание таблицы «ТМЦ» базы
данных
Рисунок 15 - Создание таблицы «убытие»
базы данных
Для организации предварительного отбора
сначала создаем глобальные переменные postnazw_,nazvanie_, date1, date2 в
которые пользователь с помощью отдельной формы помещает требования для отбора
нужной информации, и после этого SQL- запрос помещает данные во временную
таблице (cursor), с которой можно работать как с любой другой таблицей, но
нельзя вносить изменения: cursor уничтожается сразу после завершения программы.
SELECT Тмц.nazvanie,
Тмц.nomenklatu, Тмц.kluth, Тмц.kodschet, Тмц.kodif,;
Тмц.ed, Тмц.cena,
Тмц.kol, Тмц.stoim, Тмц.date, Тмц.partiya,;
Тмц.nomenkl, Тмц.sklad,
Поставщик.kluth, Поставщик.nazw, Поставщик.adres,;
Поставщик.telefon,
Поставщик.kontact, Поставщик.bank ;
FROM sklad!поставщик ;JOIN SKLAD!ТМЦ ;Поставщик.kluth = Тмц.kluth;IIF(!EMPTY(postnazw_),(postnazw_$
Lower(Поставщик.nazw)),.T.).and.;(!EMPTY(nazvanie_),(nazvanie_$
Lower(Тмц.nazvanie)),.T.)
;
.and.date1<Тмц.date .and.
date2>Тмц.date ;BY Поставщик.kluth;CURSOR Sklad
NOFILTER
В зависимости от типа прикладного
приложения, работающего с базой данных, можно создавать различные формы. Так
как работа будет вестись в операционной системе Windows 8.1, то можно создать
формы в стилистике этой ОС. Примеры форм приведены ниже.
Для создания фильтра отбора создана
специальная форма:
(в запросе это строка: IIF(!EMPTY(postnazw_),(postnazw_$ Lower(Поставщик.nazw)),.T.).and.;
IIF(!EMPTY(nazvanie_),(nazvanie_$
Lower(Тмц.nazvanie)),.T.);
.and.date1<Тмц.date
.and. date2>ТМЦ.date )
Рисунок 16 - Пример формы отбора
Остальные формы приведены в ПРИЛОЖЕНИИ 1.
Основной операционной системой используемой на предприятии, является
Windows XP SP3. В настоящее время, Windows XP SP3 наиболее распространённой (по
данным статистики, более 45% всех персональных компьютеров оснащены этой
операционной системой).
В ближайшем времени, при проведении модернизации парка вычислительной
техники, планируется переход на операционную систему MicrosoftWindows 7 SP1.
Используемый системный архиватор - WinRAR, формат сжатия резервных копий
- zip.
Используемый корпоративный антивирус - ESET NOD32 Antivirus , обладающий
кроме антивирусной защиты функциями фаейрвола и блокиратора спама.
В качестве почтового клиента используется Outlook.
Таблица 10 - Конфигурация сервера
Название компонента
Характеристика
Процессор
Intel Xeon E4300
Материнская плата
Intel LGA 2011
Оперативная память
DDR III PC18000 12 Gb
Системный жёсткий диск
128 Gb SSD Intel 730
Набор накопителей
RAID 5+2 2048 Gb
Блок питания
350 Wt
Основным пакетом прикладного программного обеспечения является Microsoft
Office 2013. Наиболее используемые его компоненты Microsoft Office Word.
Используется программа ИС ПК ЕГРП для работы с ЕГРП. Для автоматизации
приема-выдачи документов используются возможности программного комплекса ПК
ПВД.
Системы управления базами данных (СУБД) - это программные средства,
предназначенные для создания, наполнения, обновления и удаления баз данных.
Различают три основных вида СУБД:
промышленные универсального назначения;
промышленные специального назначения;
разрабатываемые для конкретного заказчика.
Специализированные СУБД создаются для управления базами данных
конкретного назначения - бухгалтерские, складские, банковские и т. д.
Универсальные СУБД не имеют четко очерченных рамок применения, они рассчитаны
«на все случаи жизни» и, как следствие, достаточно сложны и требуют от
пользователя специальных знаний.
Как специализированные, так и универсальные промышленные СУБД
относительно дешевы, достаточно надежны (отлажены) и готовы к немедленной
работе, в то время как заказные СУБД требуют существенных затрат, а их
подготовка к работе и отладка занимают значительный период времени (от
нескольких месяцев до нескольких лет). Однако в отличие от промышленных
заказные СУБД в максимальной степени учитывают специфику работы заказчика (того
или иного предприятия), их интерфейс обычно интуитивно понятен пользователям и
не требует от них специальных знаний.
Создать обширную базу данных - это вовсе не значит создать качественную
базу данных. Лишь та база приносит пользу, данные в которой достоверны и
актуальны.
Современные базы данных являются основой многочисленных информационных
систем. Информация, накопленная в них, является чрезвычайно ценным материалом,
и в настоящий момент широко распространяются методы обработки баз данных с
точки зрения извлечения из них дополнительных знаний, методов, которые связаны
с обобщением и различными дополнительными способами обработки данных. Базы
данных в данной концепции выступают как хранилища информации, это направление
называется «Хранилища данных» (DataWarehouse).
Для работы с «Хранилищами данных» наиболее значимым становится так
называемый интеллектуальный анализ данных (ИАД), или datamining, - это процесс
выявления значимых корреляций, образцов и тенденций в больших объемах данных.
Учитывая высокие темпы роста объемов накопленной в современных хранилищах
данных информации, невозможно недооценить роль ИАД.
По мнению специалистов Gartner Group, уже в 1998 г. ИАД вошел в десятку
важнейших информационных технологий. В последние годы началось активное
внедрение технологии ИАД.
Ее активно используют как крупные корпорации, так и более мелкие фирмы,
которые серьезно относятся к вопросам анализа и прогнозирования своей
деятельности. Естественно, на рынке программных продуктов стали появляться
соответствующие инструментальные средства.
Особенно широко методы ИАД применяются в бизнес-приложениях аналитиками и
руководителями компаний. Для этих категорий пользователей разрабатываются
инструментальные средства высокого уровня, позволяющие решать достаточно
сложные практические задачи без специальной математической подготовки.
Актуальность использования ИАД в бизнесе связана с жесткой конкуренцией,
возникшей вследствие перехода от «рынка продавца» к «рынку покупателя».
В этих условиях особенно важно качество и обоснованность принимаемых
решений, что требует строгого количественного анализа имеющихся данных. При
работе с большими объемами накапливаемой информации необходимо постоянно
оперативно отслеживать динамику рынка, а это практически невозможно без
автоматизации аналитической деятельности. База данных с правильной структурой
обеспечивает доступ к обновленным и точным сведениям. Поскольку правильная
структура важна для выполнения поставленных задач при работе с базой данных,
целесообразно изучить принципы создания баз данных. Это позволит создать базу
данных в соответствии с требованиями и с возможностью быстро вносить в нее
изменения.
Используем в качестве СУБД для нашего производства MySQL.
Наш выбор аргументируем следующим образом:
СУБД MySQL имеет минимальную цену среди
корпоративных баз данных;
простота настройки и конфигурирования конфигурации при помощи бесплатного
инструмента phpmyadmin;
Повышение эффективности бизнеса - основная задача всех руководите-лей.
Приложения на платформе СУБД MySQL
- позволяеют снижать издержки торгового предприятия и стимулировать рост
продаж. Управление предприятием торговли - сложный и трудоемкий процесс.
Разрабатываемое программное обеспечение на базе СУБД MySQL предназначена специально для ведения
оперативного учета компании, а также для планирования продаж и закупок.
Разработанная база данных дает возможность:
вести партионный учет различными методами (FIFO, LIFO, по среднему);
осуществлять обмен данными с 1С:Бухгалтерия 8;
подключать ККМ и сканер штрихкодов;
резервировать заказы поставщиков и покупателей;
вести учет товаров по продажным ценам;
управлять продажами, поставками, складскими запасами и заказами;
управлять товарооборотом предприятия;
анализировать цены и управлять ценовой политикой.
Специально разработанная программа на платформе СУБД MySQL - позволяет снижать издержки
торгового предприятия и стимулировать рост продаж. Управление предприятием
торговли - сложный и трудоемкий процесс.
Программное обеспечение, созданное на основе СУБД MySQL даст возможность автоматизировать
учет ТМЦ в организации. При этом уменьшается загруженность персонала, снижается
количество ошибок при оформлении документов и уменьшается объем бумажной
работы.
Для разработки баз данных учета ТМЦ используем в
качестве СУБД MySQL с инструментом управления phpmyadmin.
Проект будет реализоваться за счет собственных средств
организации. Экономия обеспечивается за счет оптимизации бизнес-процессов,
исключения бумажного документооборота и дублирования операций, снижения затрат
на сопровождение информационной системы.
Чтобы определить эффективность разработки баз данных
учета ТМЦ на основе СУБД MySQL
необходимо рассчитать показатели общих капитальных затрат.
Общие капитальные затраты (К), связанные с разработкой
базы данных учета ТМЦ на фирме «Жесть» определяются по формуле:
К = Ккп + Кн + Ктех + Крм + Кпр, (1)
где Ккп - затраты на покупку необходимой
компьютерной программы;
Кн - капитальные затраты на
настройку компьютерной программы;
Ктех - капитальные затраты на
техническое оснащение рабочего места пользователя компьютерной программы;
Крм - капитальные затраты на
организацию рабочего места пользователя компьютерной программы;
Кпр - прочие капитальные
затраты, связанные с внедрением компьютерных программ.
Затраты на покупку необходимой компьютерной программы
(Ккп) СУБД MySQL составят 18 500 руб.
Рассчитаем
капитальные затраты на настройку компьютерной программы (Кн).
Примем их в размере равным 4
МРОТ:
Кн = 4 * 5965 = 23860 руб.
Рассчитаем капитальные
затраты на техническое оснащение рабочего места пользователя компьютерной
программы (Ктех). Они рассчитываются по формуле:
Ктех = где Цком - стоимость
компьютера, требуемого для обеспечения нормальной работы компьютерной
программы;
Цтех - стоимость дополнительного
технического оснащения;
Кт - коэффициент, учитывающий
затраты на транспортировку и наладку компьютера и других технических средств
(принято брать в размере 0,1%);
Киз - коэффициент, учитывающий
степень износа действующей компьютерной техники, Киз = 0;
Тм - величина затрачиваемого
машинного (компьютерного) времени на выполнение производственных задач;
Тоб - общее время эксплуатации
компьютера в течение года.
Рыночную стоимость компьютера,
требуемого для обеспечения нормальной работы компьютерной программы (Цком)
примем равную 45 000 руб.
Дополнительного технического
оснащения (Цтех) не требуется.
Величина затрачиваемого
машинного (компьютерного) времени на выполнение производственных задач (Тм)
рассчитывается по формуле:
Тм=Вз*Др, (3)
где Вз - время решения
исследуемых задач с помощью редактора Protégé-OWL в течение
одного рабочего дня, в часах.
Др - количество рабочих дней
(либо недель, месяцев) в году, в течение которых решаются исследуемые задачи.
Время решения исследуемых задач
с помощью редактора Protégé-OWL
в
течение одного рабочего дня (Вз) примем равным 8 часам.
Определим количество рабочих
дней в году, в течение которых решаются исследуемые задачи (Др). Предположим,
что первые работы по обкатке системы выполнялись 22 рабочих дня, затем
систематический контроль происходит 3 раза в неделю или приблизительно 15 раз в
месяц: 22+15*12 мес = 202 дн.
Таким образом:
Тм = 8 * 202 = 1616 ч.
Рассчитаем общее время
эксплуатации компьютера в течение года (Тоб). Оно рассчитывается следующим
образом:
Toб =
ds * S * Др* Nm * Кис, (4)
где ds - длительность смены
(8 часов);- число смен работы компьютера (1 смена);
Др - среднее число рабочих дней
в месяце (22 день);- число месяцев в году эксплуатации компьютера (12 месяцев);
Кис - средний коэффициент
использования компьютера в течение смены (принято брать 0,9).
Таким образом, б = 8 * 1* 22 * 12
* 0,9 = 1900,8 ч.
Рассчитав все необходимые
данные, можем найти Ктех:
Ктех = Рассчитаем капитальные затраты на организацию рабочего
места пользователя компьютерной программы (Крм). Их следует рассчитать по
формуле:
Крм = где S - размер площади,
которую занимает мебель под компьютер и другую оргтехнику и специалист,
работающий с помощью компьютера;
Цпл - стоимость 1 м2
производственной площади;
Кмеб - капитальные затраты на
приобретение специальной мебели, повышающей производительность и комфортность
работы пользователя компьютерной программы.
Размер площади, которую занимает
мебель под компьютер и другую оргтехнику и специалист, работающий с помощью
компьютера(S) примем 6 м2.
Стоимость 1 м2
производственной площади, условно примем равную 1000 руб.
Капитальные затраты на
приобретение специальной мебели, повышающей производительность и комфортность
работы пользователя компьютерной программы (Кмеб) принято брать в размере 15%
от рыночной цены компьютера, используемого для решения поставленных задач.
Стоимость компьютера в нашем
случае составляет 45 000 руб. Таким образом,
Кмеб = 45 000 * 15% = 6750 руб.
Исходя из приведённых выше
показателей, рассчитывается Крм:
Крм = Рассчитаем размер прочих капитальных затрат, связанные с
внедрением компьютерных программ (Кпр).
В прочие капитальные вложения, связанные с
использованием компьютерных программ, включаются расходы на покупку
оборудования для архивных копий баз данных, по обучению работников пользованию
новой программой, по приобретению учебных пособий по использованию купленных
программ и др. Их принято брать в размере 5 МРОТ:
Кпр = 5 * 5965 = 29825 руб.
В таблицу 2 сведем рассчитанные показатели для
определения общего числа капитальных затрат, связанных с разработкой базы данных учета ТМЦ на фирме «Жесть».
Таблица 11 - Капитальные затраты на разработку базы данных учета ТМЦ с конфигурации «1С:
Управление торговлей 8»на фирме «Жесть»
Статья затрат
Сумма, руб.
Затраты на покупку необходимой компьютерной программы (Ккп)
18500
Затраты на настройку компьютерной программы (Кн)
23860
Затраты на техническое оснащение рабочего места
пользователя компьютерной программы (Ктех)
42083
Затраты на организацию рабочего места пользователя
компьютерной программы (Крм)
10840
Прочие капитальные затраты, связанные с внедрением
компьютерных программ (Кпр)
29825
Итого капитальных затрат
125108
По данным таблицы 2 видно, что
капитальные затраты на разработку
разработки базы данных учета ТМЦ с использованием СУБД MySQL на фирме «Жесть» составят 125108 руб. Следовательно,
объем инвестиций требуется в размере 125108 руб. для разработки базы
данных учета с использованием СУБД MySQL на фирме «Жесть».
Рассчитаем себестоимость разработки базы данных учета ТМЦ с
использованием СУБД MySQL на фирме
«Жесть».
Себестоимость продукции - это затраты предприятия на ее
производство и реализацию, выраженные в денежной форме. Калькулирование
себестоимости является одной из основных задач управленческого учёта на
предприятии. Калькуляция сметной стоимости разработки базы данных учета
ТМЦ с использованием СУБД MySQL
включает следующие статьи затрат:
заработная плата (ЗПпр) - это сумма основной и
дополнительной заработной платы программиста;
отчисления на социальные нужды, 30% от заработной платы (Он);
затраты на оплату машинного времени (Змв);
затраты на электроэнергию (Сэ);
прочие затраты (3п).
Сметная стоимость разработки базы данных учета ТМЦ с
использованием СУБД MySQL - это
эксплуатационные расходы на разработку базы знаний:
Зобщ = ЗПпр + Он
+ Змв + Сэ + 3п. (6)
Определение затрат на оплату труда программиста
предваряет расчет трудозатрат на разработки базы данных учета ТМЦ с
конфигурации «1С: Управление торговлей 8»:
T = tи + tа + tбс + tп + tн + tотл + tд, (7)
где tи -
затраты труда на исследование алгоритма решения задачи;
tа - затраты на разработку алгоритма;
tбс - затраты на разработку блок-схемы
алгоритма;
tп - затраты на программирование;
tн - затраты на набивку программы;
tотл - затраты на отладку программы на
ПК;
tд - затраты на подготовку
документации.
Затраты труда на исследование алгоритма решения задачи
с учетом уточнения описания и квалификации программиста:
где
Q - условное число операторов в программе;
В - коэффициент увеличения затрат в зависимости от
сложности программы (1,2...5). Среднее для наиболее точных расчетов В =
2;
K -
коэффициент квалификации разработчика.
Составляющие
затраты труда можно определить через условное число операторов в программном
продукте. В их число входят те операторы, которые нужно учесть программисту в
процессе работы над задачей с учетом возможных уточнений постановки задачи и
совершенствования алгоритма:
где q - предполагаемое число операторов, в зависимости от типа задачи (таблица 3); с
- коэффициент сложности программы (таблица 4).
Таблица 12 - Число команд в зависимости от типа задач
Тип задачи
Пределы изменений коэффициента
Задачи учета
от 1400 до 1500
Задачи оперативного управления
от 1500 до 1700
Задачи планирования
от 3000 до 3500
Многовариантные задачи
от 4500 до 5000
Комплексные задачи
от 5000 до 5500
Программные продукты по степени новизны могут быть отнесены к
одной из 4-х групп:
группа А - разработка принципиально новых задач;
группа Б - разработка оригинальных программ;
группа В - разработка программ с использованием типовых
решений;
группа Г - разовая типовая задача.
По степени сложности программные продукты могут быть отнесены
к одной из 3-х групп:
) алгоритмы оптимизации и моделирования систем;
) задачи учета, отчетности и статистики;
) стандартные алгоритмы.
Таблица 13 - Значение коэффициента сложности программы
Язык программирования
Группа сложности
Степень новизны
А
Б
В
Г
Высокого уровня
1
1,38
1,26
1,15
0,69
2
1,30
1,19
1,08
0,65
3
1,20
1,10
1,00
0,60
Низкого уровня
1
1,58
1,45
1,32
0,79
2
1,49
1,37
1,24
0,74
3
1,38
1,26
1,15
0,69
Коэффициент
квалификации разработчика зависит от стажа работы программиста следующим
образом:
стаж
до 2 лет - К = 0.8;
от
2 до 3 лет - К = 1;
от
3 до 7 лет - К = 1,3...1,4;
от
7 лет - К = 1,5...1,6.
Затраты
труда программиста на разработку базы данных учета ТМЦ на базе СУБД MySQL
составят: Расчет
трудозатрат на разработку алгоритма:
Трудозатраты
на разработку блок-схемы алгоритма равны tа = tбс =
108.
Программирование
- процесс и создания компьютерных программ и (или) программного обеспечения с
помощью языков программирования. Время написания
программы на языке программирования:
Время набивки программы:
Отладкой программы занимается программист. Отладка
программы - выполнение программы для выявления дефектов в функциях, в логике,
проводится проверка программного продукта на соответствие техническому заданию.
Расчет трудозатрат на отладку:
Трудовые
затраты на подготовку документации будут складываться из затрат труда на
подготовку рукописного текста и затрат труда на редактирование, печать и
оформление документации:
где
tдп -
трудовые затраты на подготовку материалов в рукописи;
tдр - затраты на редактирование, печать и оформление
документации.
Трудозатраты
на подготовку материалов в рукописи:
Затраты
на редактирование, печать и оформление tдр прямо пропорционально зависит от затрат на подготовку
материалов в рукописи:
Определим
затраты на оплату труда программиста на разработку базы данных учета ТМЦ:
T = 138 +108
+ 108 + 162 +108 + 453,6 + 55,7 = 1133,3 ч.
Расходы
на оплату труда разработчика программы (ЗПпр):
где
Сч.1 - часовая тарифная ставка 1-го разряда;
Кт
- тарифный коэффициент, соответствующий разряду
тарифной сетки, по которому работает исполнитель.
Месячный
оклад специалиста занятого решением поставленных задач в соответствии со
штатным расписанием фирмы 15 000 руб.
Дополнительная
заработная плата определяется в процентах от основной (15%) и составит:
*15%
= 2250 руб.
Отчисления
на социальные нужды (Осн) составляют 30% от затрат на оплату
труда программиста.
Осн = (15000+2250)*30% = 5175 руб.
Стоимость
машинного времени определяется по формуле:
где С - цена машино-часов:
где За - затраты на амортизацию -
годовые издержки на амортизацию;
Звм - годовые издержки на
вспомогательные материалы;
Зтр - затраты на текущий ремонт
компьютера;
Зпр - годовые издержки на прочие и
накладные расходы;
ТПК - действительный годовой фонд
времени ЭВМ.
Годовые издержки на амортизацию:
где Cбал -
балансовая стоимость компьютера; НА - норма амортизации, %.
Балансовая стоимость компьютера:
где Спер - рыночная стоимость ПК;
Зду - прочие затраты на доставку и
установку, 10% от стоимости ПК.
Срок
службы ПК составляет 3 года.
Годовые
издержки на вспомогательные материалы примем равными 5000 руб. Затраты на
текущий ремонт компьютера примем равными 15000 руб. Годовые издержки на прочие
и накладные расходы составляют 6% от балансовой стоимости компьютера и составят
2970 руб.
Действительный
годовой фонд времени ЭВМ:
где
Дк - число календарных дней в планируемом году, Дк
= 365 дн.;
СВ - количество субботних и воскресных нерабочих дней в
году, СВ = 110 дн.; Пр - количество праздничных
нерабочих дней в планируемом году, Пр = 8 дн.;
ППр
- число предпраздничных дней в
планируемом году, ППр = 6 дн.;
Тсм - продолжительность рабочего дня, Тсм
= 8 ч;
Рассчитаем
цену машино-часа:
Определим
стоимость машинного времени:
Затраты
на электроэнергию:
где
Зэ - стоимость электроэнергии, руб./1 кВтч;
P -
мощность, потребляемая ПК.
Прочие
затраты (Зп) при разработке программного продукта составляют
5% от суммы остальных затрат и составляет 2320 руб.
Сметная
стоимость разработки базы данных учета ТМЦ на базе СУБД MySQLсоставит:
Зобщ = 17250 + 5175 + 14617 + 9352 + 2320 = 48714 руб.
Таким образом, себестоимость разработки базы данных
учета ТМЦ на базе СУБД MySQL на фирме «Жесть» составят 48714 руб.
Годовую экономию от разработки базы данных учета ТМЦ
на базе СУБД MySQL (Эг) определяют по формуле:
Эг = Зд - Зобщ, (24)
где 3д - затраты, связанные с осуществлением
поставленных задач действующим на фирме ручным способом.
Разработанная база данных даст возможность автоматизировать учет ТМЦ в
организации. После разработки базы данных учета ТМЦ на базе СУБД MySQL
произойдет снижение времени с поиском необходимой информации.
Затраты по поиску необходимой информации ручным
способом (Зд) определяется по формуле:
Зд=Р*(Вуч/Др* ds) * (Ом+П + Осн), (25)
где Р - число работников, участвующих в решении
задач ручным способом в течение года;
Вуч - время участия каждого работника в решении задач
ручным способом в течение года, в часах;
П - премия, предусмотренная для работников,
участвующих в решении задач;
Осн - отчисления на социальные нужды (30%).
Число работников, участвующих в решении поставленных
задач ручным способом в течение года (Р) примем 5 чел.
Время участия каждого работника в решении задач ручным
способом в течение года (Вуч): предположим, что в месяц уходит 160 часов.
Следовательно, 160*12 = 1920 часов.
Премия, предусмотренная для работников, участвующих в
решении задач (П) принято брать в размере 25% от Ом, т. е.
П = 15 000 * 0,25 = 3750 руб.
Отчисления на социальные нужды (30%), включают 22% - пенсионный
фонд; 2,9% - социальное страхование; 5,1% - федеральный фонд обязательного
медицинского страхования.
Осн = (15 000 + 3750) *0,3 = 5625 руб.
Таким образом, затраты при ручном способе поиска
необходимой информации в год составят:
Зд = 5 *1920/8*22 *(15000+3750+5625) = 1 329 545 руб.
Годовая экономия от разработки базы данных учета ТМЦ
на базе СУБД MySQLсоставит:
Эг = 1 329 545 - 48714 = 1280831 руб.
Таким образом, годовая экономия от разработки базы
данных учета ТМЦ на базе СУБД MySQLсоставит 1280831 руб.
При оценке эффективности инвестиционных проектов
используется такой показатель, как период окупаемости проекта.
Рассчитаем период окупаемости проекта (Ток), который
определяется по формуле:
Ток = К / Эг, (26)
Ток = 125108/
1280831 = 0,1 года.
Таким образом, срок окупаемости затрат, вложенных в
проект, составляет 0,1 года (<2 лет), что говорит об эффективности данного
проекта.
Таким образом, проект по разработке разработки базы
данных учета ТМЦ на базе СУБД MySQL экономически выгоден.
5. БЕЗОПАСНОСТЬ ЖИЗНЕДЕЯТЕЛЬНОСТИ ПРИ РАЗРАБОТКЕ БАЗЫ ДАННЫХ УЧЕТА ТМЦ ДЛЯ
ИП ЛИТВИНОВА А.Ю. ФИРМА «ЖЕСТЬ»
5.1 Анализ условий труда программиста
на ИП Литвинова А.Ю. фирма «Жесть»
Помещения для эксплуатации ПЭВМ должны иметь естественное и искусственное
освещение.
Естественное и искусственное освещение должно соответствовать требованиям
действующей нормативной документации. Окна в помещениях, где эксплуатируется
вычислительная техника, преимущественно должны быть ориентированы на север и
северо-восток.
Оконные проемы должны быть оборудованы регулируемыми устройствами типа:
жалюзи, занавесей, внешних козырьков и др.
Площадь на одно рабочее место пользователей ПЭВМ с ВДТ на базе
электронно- лучевой трубки (ЭЛТ) должна составлять не менее 6м2, в
помещениях культурно- развлекательных учреждений и с ВДТ на базе плоских
дискретных экранов (жидкокристаллические, плазменные)- 4,5м2.
При использовании ПЭВМ с ВДТ на базе ЭЛТ (без вспомогательных устройств-
принтер, сканер и др.), отвечающих требованиям международных стандартов безопасности
компьютеров, с продолжительностью работы менее 4 ч в день допускается
минимальная площадь 4,5м2 на одно рабочее место пользователя
(взрослого и учащегося высшего профессионального образования).
Для внутренней отделки интерьера помещений, где расположены ПЭВМ, должны
использоваться диффузно отражающие материалы с коэффициентом отражения для
потолка- 0,7-0,8; для стен -0,5-0,6; для пола -0,3-0,5.
Полимерные материалы используются для внутренней отделки интерьера
помещений с ПЭВМ при наличии санитарно- эпидемиологического заключения.
Помещения, где размещаются рабочие места с ПЭВМ, должны быть оборудованы
защитным заземлением (занулением) в соответствии с техническими требованиями по
эксплуатации.
Не следует размещать рабочие места с ПЭВМ вблизи силовых кабелей и
вводов, высоковольтных трансформаторов, технологического оборудования,
создающего помехи в работе ПЭВМ.
Дверь помещения открывается наружу, что соответсвует правил по пожарной
безопасности. У всех работников свободный проход к выходу. Вся документация
хранится в специальных шкафах. Обеспечены нормальные метеорологические условия
в помещении отдела. Метеорологические условия или микроклимат характеризуются
следующими показателями:
температура воздуха;
относительная влажность воздуха;
интенсивность теплового излучения и тд.
Все эти параметры регламентируются Сан Пин 2.2.2.542-96 «Гигиенические
требования к видеодисплейным терминалам, персональным электронно-
вычислительным машинам и организации работы».
Все производственные помещения оборудованы кондиционерами, системами
принудительной вентиляции и радиаторами центрального отопления. Климатические и
метеорологические условия соответствуют норме.
Уровень шума в помещении постоянный 43дБ и не превышает допустимого 50дБ.
В помещении отдела предусмотрено смешанное освещение:
Естественное (боковое) через окна в боковых и фронтальных стенах.
Естественное освещение представлено 4 окнами 2 из которых выходят на
восток, а 2 на юг. Площадь каждого окна равна 2,0 м2 соответственно
их суммарная площадь равна 8 м2. КЕО равен 1,2%.
Искусственное (с помощью боковых светильников).
Освещение в помещении преимущественно естественное. В отделе присутствует
4 окна.
Общее искусственное освещение представлено 2 светильниками, в каждом из
которых находится по 2 люминесцентной лампе мощностью каждая 35 Вт. Помещение
оборудовано 5 компьютерами, 1 принтером, 1 сканером, 2 телефонами и 1 сервером.
Компьютеры используются постоянно.
Рабочее место располагается с учетом требований СанПин 2.2.2.542-96,
расстояние между этим рабочим местом и другими не менее 1,2 м.
Регламентированные перерывы составляют до 50 минут. Сотрудники периодически
проходят медосмотр.
В помещении с ПЭВМ проведен анализ условий труда на соответствие СанПин
2.2.2.542-96 «Гигиенические требования к видеодисплейным терминалам,
персональным электронно- вычислительным машинам и организации работы».
В случае возникновения пожара эвакуация работников из зоны возгорания не
будет затруднена, потому что имеется два эвакуационных выхода. Имеется
огнетушитель марки ОПУ 5-04. Также помещение оборудовано медицинской аптечкой.
В отделе также имеются инструкции по технике безопасности гигиенический
сертификат.
5.2 Мероприятия по обеспечению и
улучшению условий безопасности жизнедеятельности в помещении с АРМ ПК
В процессе анализа условий труда работающих в помещении с ПЭВМ, было
выявлено несколько недостатков в системе охраны труда. Для их устранения и
создания оптимальных условий труда предлагается внедрить некоторые мероприятия:
обеспечение нормируемых параметров воздушной среды;
организация рабочего места оператора методом сокращения затрат
вспомогательного времени.
В качестве факультативных мероприятий можно предложить предусмотреть
установку кондиционера.
5.2.1 Обеспечение нормируемых
параметров воздушной среды
Вентиляционные установки- устройства, обеспечивающие в помещении такое
состояние воздушной среды, при котором человек чувствует себя нормально и
микроклимат помещений не оказывает неблагоприятного действия на его здоровье.
Для обеспечения требуемого по санитарным нормам качества воздушной среды
необходима постоянная смена воздуха в помещении, вместо удаляемого вводится
свежий, после соответствующей обработки, воздух.
В данном подразделе будет произведен расчет общеобменной вентиляции от
избытков тепла.
Общеобменная вентиляция- система, в которой воздухообмен, найденный из
условий борьбы с вредностью, осуществляется путем подачи и вытяжки воздуха из
всего помещения. Количество вентиляционного воздуха определяется по формуле:
Gвент= где Qизб- выделение в помещении явного тепла, Вт;
С-
теплоемкость воздуха (С=1,0 кДж/кг*К);
р-
удельная плотность воздуха (1,3 кг/м3);
tух, tпр- температура удаляемого и приточного воздуха, град.
Температура
удаляемого воздуха определяется по следующей формуле:
tух=tпз+d(h-2), (28)
где tпз- температура воздуха в рабочей зоне (tпз=24 град)
d- коэффициент
нарастания температуры на каждый метр высоты (d= 1,0 град/ м)
h- высота
помещения (h= 3,05 м)
Отсюда
tух= 24+
1,0х(3,05-2) = 25 0С.
Количество
избыточного тепла определяется из теплового баланса, как разница между теплом,
поступающим в помещение и теплом, удаляемым из помещения и поглощаемым в нем.
Qизб=Qприх-Qрасх, (29)
Поступающее
в помещение тепло определяется по следующей формуле:
Qприх=Qобор +Qл+ Qосв +Qрад, (30)
где Qобор- тепло от работы оборудования;
Qл- тепло, поступающее от людей;
Qосв- тепло от источников освещения;
Qрад- тепло от солнечной радиации через окна.
Qобор=jхPустхn=0,15*450х7=472, (31)
где j -
доля энергии, переходящей в тепло;
Pуст- мощность установки;
n - количество
оборудования.
Qл=n/q=5х90=450, (32)
где n -
количество человек в зале (n=5);
q- количество
тепла, выделяемое человеком (q= 90Вт).
Qосв= jхРосв=0,75х4х35=105, (33)
где j=0,75
для люминесцентных ламп;
Росв-
мощность осветительной установки (4 ламп по 35 Вт)
Qрад= АхкхSхm= 180х2,0х4х0,8= 1 152, (34)
где А
- теплопоступление в помещение с 1 кв.м стекла (127-234Вт/м);
S - площадь окна
(S=2,0 м2);
m - количество
окон (m=4);
k - коэффициент,
учитывающий характер остекления (k= 0,8).
Qприх=472+450+105+1152= 2 179 Вт.
Qрасх=0,1х Qприх=0,1х
2 179=218, (35)
Отсюда
по формуле Qизб= 1 961
Вт
Находим
необходимый воздухообмен по формуле
Gвент Определяем
необходимую кратность воздухообмена
К= где р
- удельная плотность воздуха (1,3 кг/м3));
Vпом=nхSчелхh;
n = 5 - число
людей в помещении;
Sчел - площадь производственного помещения, приходящаяся на
1 человека (по нормам для умственного труда Sчел = 4 м);
h = 3,05 м-
высота помещения
Кратность
воздухообмена:
К= 5.2.2 Определение мощности
вентилятора
Произведем подбор вентилятора по аэродинамическим характеристикам и
специальным номограммам, составленным на основе стендовых испытаний различных
видов вентиляторов. Исходными данными для выбора вентилятора являются:
расчетная производительность вентилятора:
Vрасч= 1,1* Vвент= 1,1х2353 Вт=2588 Вт, (37)
где 1,1- коэффициент, учитывающий утечки и подсосы воздуха;
Vвент - напор (полное давление),
обеспечиваемый вентилятором:
где р=1,3
кг/ м- плотность воздуха,
v - окружная
скорость вентилятора, ограничивается предельно допустимым уровнем шума в
помещении. Для центробежных вентиляторов низкого давления в помещениях с малым
шумом v должна быть не более 35 м/с. Для расчета примем v=25м/с.
Тогда
Нв=406Па
По
исходным данным выбираем центробежный вентилятор низкого давления Ц4-70N5.
По номограммам определяем его характеристики:
число
оборотов- 1000 об/мин;
КПД
вентилятора - 80%.
Необходимая
установочная мощность электродвигателя
N= где b -
КПД вентилятора.
Ближайшая
мощность электродвигателя вентилятора - 380 Вт.
5.3 Организация рабочего места
инженера-программиста методом сокращения затрат вспомогательного времени
В настоящее время для улучшения условий труда работников предприятия и,
как следствие, для увеличения производительности их труда широко используется
эргономическое обоснование или расчет. При этом зачастую определяются или
анализируются удобства габаритов зоны обслуживания или рабочего места в целом,
а также рациональность движений работников. Облегчить такую работу позволяет
применение соответствующих компьютерных программ, которые существенно сокращают
продолжительность расчетов и дают объективную (типа документации) информацию.
Важную роль в проведении таких расчетов играет прикладная эргономика.
Прикладная эргономика изучает функциональные возможности человека в
трудовом процессе, дает общие и конкретные рекомендации по оптимизации
производственной среды и, в конечном счете, способствует поддержанию
работоспособности человека на уровне, детерминированном заданной
производительностью труда. Существенное место в современной прикладной
эргономике продолжает занимать учет размеров характерных частей тела человека
(антропометрия), параметров углов и зон его зрения, закономерностей трудовых
движений и перемещений ((биомеханика).
Проведён эргономический анализ рабочего места оператора АРМ ПК, используя
методику компьютерного анализа рабочего места. Антропометрический анализ зоны
обслуживания (рабочего места) показал, что в общем габариты рабочего места
отвечают требованиям удобства и безопасности. Исключением является неудобное
положение принтера, он находится вне зоны досягаемости оператора.
Также был проведен расчет условий зрительной зоны. После вычерчивания
трех основных зон проведён анализ зрительной работы оператора. По результатам
анализа можно сказать, что зоны зрения соответствуют расположению объектов
зрительного контроля.
Анализ затрат вспомогательного времени оператора показал реальные затраты
времени на определенную операцию, и выявил непродуктивные потери времени и
уточнил недостатки рабочего места. К недостаткам можно отнести: неудобное
положение принтера, отсутствие подставок для бумаг, неудобный стул. Расчет
коэффициента эргономичности производился следующим образом. Выбирается операция
и делится на приемы, которые в свою очередь делятся на микроэлементы, а затраты
времени на них, затраты времени на лишние элементы и количественная оценка
удобства рабочего места рассчитывается:
скрипт база данных учет
Кэ= Коэффициент
эргономичности по базе получился равным:
Кэб=0,65
Принимаем от 0,7 до 0,9.
Для
улучшения эргономичности показателя рабочего места путем сокращения
вспомогательного времени предложен ряд мероприятий: установка принтера в зону
досягаемости, использование подставок для бумаг и специальных стульев с
регулируемым углом отклонения спинки.
Пересчитав
коэффициент эргономичности с учетом предложенных мероприятий получим:
Кэп
= 0,9
Определим
величину ликвидированных потерь рабочего времени:
В=
(Кэп- Кэб)*100, (40)
где В
= 25%
Вычислим
коэффициент уплотнения рабочего дня:
Ку= где Фд-
действительный фонд рабочего времени за смену;
Тр-
затраты рабочего времени за смену на выполнение ручных приемов и перемещений в
течении рабочего дня;
К-
доля затрат на выполнение ручных приемов и перемещений (К=0,2), (Ку=5%).
Рост
производительности труда составит:
ΔП= ΔП =5,26%.
5.4 Прогнозирование эффективности
проведённых мероприятий
Оценим значимость мероприятий по улучшению условий труда. Оценку будем
производить по 2 критериям:
по производительности труда
по полученному годовому экономическому эффекту.
Для оценки воспользуемся методом определения эффективности за счет
сокращения компенсирующего отдыха. Этот метод применяется в тех случаях, когда
имеют место значительные вредные факторы и планируется компенсирующий отдых.
Перечислим предложенные мероприятия которые повлекли за собой улучшение
условий труда:
Замена обычных ламп накаливания люминесцентными позволит улучшить
освещенность и привести ее в соответствие норме (0), а ранее ее можно было
охарактеризовать как недостаточное (1).
За счет замены офисной мебели, в частности стульев удастся улучшить
положение работающих. Ограниченное (1), недостаточное (2).
Компенсирующий отдых по базе составил:
+1+2=5%
Компенсирующий отдых по проекту составит:
+1+0=1%
Время на компенсирующий отдых по базе за месяц , час по формуле:
где tк.о.б
- время на компенсирующий отдых в %
отработанного времени;
Фд
- действительный фонд рабочего времени.
Время
на компенсирующий отдых по проекту за месяц, час по формуле:
где tк.о.п- время на компенсирующий отдых в % отработанного
времени
Фд-
действительный фонд рабочего времени.
Далее
рассчитаем экономию рабочего времени за счет сокращения компенсирующего отдыха
по формуле:
Δ tк.о.= tк.о.б- tк.о.п, (45)
Δ tк.о.=8,8-3,52= 5,28, час
Теперь
рассчитаем коэффициент уплотнения рабочего дня сотрудника отдела:
Ку= Рост
производительности труда определяем по формуле
ΔП= И наконец рассчитаем годовой экономический эффект, рублей:
где Зср-
среднемесячная заработная плата работающего;
R-
среднесписочное число работников отдела.
Эгод= Подводя
итог данного раздела можно сказать, что предложенные мероприятия по улучшению условий
труда и технике безопасности будут иметь благотворные для организации
результаты выразившиеся в повышении производительности труда на 3,09%. А
конечный экономический эффект составит 9696 рублей.
ЗАКЛЮЧЕНИЕ
Результатом произведенной работы над дипломным проектом стал программный
продукт, представляющий из себя базу данных в виде набора файлов, содержащую в
себе связанные по ключевым полям таблицы. Данные в базе данных прошли
нормализацию до третей нормальной формы. Для созданной базы данных разработана
универсальная форма запроса, позволяющая вносить данные в базу данных,
сортировать их и получать отчет по движению товарно-материальных ценностей.
Формат отчета - документ Microsoft Office Word 2003 и выше.
В процессе написания дипломного проекта в теоретической части были
собраны сведения о современных методах учета товарно-материальных ценностей и
реляционных базах данных.
В аналитической части проанализирована информационно-техническая
инфраструктура предприятия, составлен план мероприятий по ее последующей
модернизации.
В практической части получен готовый программный продукт.
В экономико-технической части дано обоснование проекта, он признан
рентабельным.
В части безопасность жизнедеятельности произведен анализ условий труда
программиста и предложены мероприятия по улучшению его условий труда.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
1 Федеральный закон «Об информации, информатизации и защите
информации» /Собрание законодательства Российской Федерации 20.02.1995 г.:
Официальное издание. - М.: Юридическая литература: Администрация Президента
Российской Федерации, 1995. - с. 1213 - 1225.
ГОСТ Р50922-96. Государственный стандарт РФ «Защита
информации». Общие положение от 2000-01-01
ГОСТ 19.701-90 (ИСО 5807-85). ЕСПД. Схемы алгоритмов,
программ, данных и систем. Условные обозначения и правила выполнения.
Ручкин, В.Н. Архитектура компьютерных сетей. / В.Н. Ручкин,
В.А. Фулин - Диалог-МИФИ, 2008. - 240 с.
Описание стандартов семейства IDEF www.idef.org /
[Электронный ресурс]. - Internet recourse режим доступа www.idef.org
Столингс, В. Основы защиты сетей. Приложения и стандарты. /
В. Столингс - Вильямс, 2012. - 432 c.
Величко, В.В Основы инфокоммуникационных технологий. Уч. пос.
для Вузов. / В.В. Величко - М.:Горячая линия-Телеком, 2009. - 712 с.
Социальная сеть работников IT-индустрии HabraHabr.ru /
[Электронный ресурс]. - Internet recourse режим доступа habrahabr.ru
Практикум по информатике и информационным технологиям.
Учебное пособие для общеобразовательных учреждений/Н.Д. Угринович, Л.Л. Босова,
Н.И. Михайлова. - 3-е изд. - М. БИНОМ. Лаборатория знаний, 2011. - 394 с.: ил.
Автоматизированные информационные технологии в экономике:
Учебник [Текст] / Под общ. ред. проф. И.Г.. Титоренко - М.: ЮНИТИ-ДАНА, 2007. -
416 с.: ил.
Петров, В.Н. Информационные системы [Текст] / В.Н. Петров -
СПб.: Питер, 2012. - 688 с.: ил.
Симонович, С.В. Информатика: Базовый курс [Текст]/ С.В.
Симонович и др. - СПб.: Питер, 2007. - 640 с.
Технические средства информатизации: Учебник [Текст] / Колл.
авторов. - 2-е изд., перераб. и доп. - М.: Форум: Инфа-М, 2008 - 592 с.: ил.
Chip. [Текст], [Электронный ресурс] - М.: Издательский дом
«Бурда», №1-12, 2013.
Ильина, И.Л. Проектирование автоматизированных систем:
Учебное пособие / И.Л. Ильина - Ангарск: АГТА, 2015.
Исаченко Олег: Программное обеспечение компьютерных сетей.
Учебное пособие / О. Исаченко - ИНФРА-М, 2012. - 117 с.
17 Барановская, Т.П. Информационные
системы и технологии в экономике/Т.П. Барановская, В.И. Лойко. - М.: Финансы и
статистика, 2015. - 416 с.
Брага, В.В. Автоматизированные
информационные технологии в экономике: учебник / В.В. Брага, Н.Г. Бубнова, Г.А.
Титоренко. - М.: Компьютер, ЮНИТИ, 2011. - 399 с.
Братухин, П.И.
Информационно-вычислительные системы как объект технического регулирования для
обеспечения безопасности критически важных систем / П.И. Братухин, Ю.А. Панов,
В.П. Шахин // Повышение обороноспособности и госбезопасность. [Электронный
ресурс]: режим доступа: http://federalbook.ru
Горфинкель, В.Я. Экономика
предприятия [Текст]: учебник / Под ред. проф. В.Я. Горфиниеля, проф. В.А.
Швандара. - М.: ЮНИТИ-ДАНА, 2014. - 670 с.
Душин, В.К. Теоретические основы
информационных процессов и систем: учебное пособие / В.К. Душин. - М.: Дашков и
К, 2012. - 250 с.
Ефимова, О.В. Финансовый анализ -
современный инструментарий обоснования экономических решений: учебное пособие
/О.В. Ефимова. - М.: Омега-Л, 2010. - 208 с.
Каляное, Г.Н. Консалтинг: от
бизнес-стратегии к корпоративной информационно-управляющей системе: учебное
пособие/ Г.Н. Каляное - М.: Горячая Линия - Телеком, 2014. - 210 с.
ПРИЛОЖЕНИЕ 1 - Формы приложения
ПРИЛОЖЕНИЕ 2 - Список часто используемых
команд MySQL
Консоль MySQL позволяет вводить как
инструкции SQL, так и служебные команды MySQL, предназначеные для
администрирования и использования таблиц в базах данных MySQL. К основным
командам относятся SHOW, USE и CREATE. Рассмотрим каждую из них отдельно.
Эта команда предназначена для просмотра
доступных баз данных и таблиц в конкретных базах данных. Для просмотра списка
баз данных необходимо ввести такую команду:DATABASES;
Если, например, существуют две базы данных
- mysql и test (эти две базы как правило создаются автоматически при
инсталляции сервера), то MySQL ответит примерно так:
+----------+
| Database |
+----------+
| mysql |
| test |
+----------+
Для просмотра списка таблиц используется
эта же команда в таком виде: TABLES;
Эта команда выдаст список таблиц в текущей
базе данных:
+-----------------+
| Tables in mysql |
+-----------------+
| test |
| mysql |
+-----------------+
Замечание: вы можете работать только с
одной базой данных в одно и то же время, поэтому в приведенном выше примере нет
нужды указывать название базы данных, список таблиц которой стоит вывести,
поскольку производится поиск в активной на данный момент базе.
Эта команда позволяет создавать новые базы
данных. Как было сказано выше, по умолчанию сервер создает две базы данных -
mysql и test. Для удобства стоит создавать новую базу данных для каждой
отдельной задачи, потому что легче работать с набором таблиц, которые связаны
между собой (даже если эта связь только смысловая). Создадим новую базу данных
при помощи этой команды: DATABASE staff
После этой операции будет создана новая
база данных не содержащая никаких таблиц, а команда SHOW DATABASES выдаст
следующее:
+----------+
| Database |
+----------+
| mysql |
| test |
| staff |
+----------+
Как уже было сказано выше, в один и тот же
момент только одна база данных может быть активна. Команда USE служит для
выбора этой активной базы. Для перехода к некоторой базе данных необходимо
выполнить следующую операцию: staff
Стоит отметить, что при создании новой
базы данных (см. выше), новая база не становится активной автоматически - для
ее использования необходимо сделать это самостоятельно.
Нижеследующее ознакомит вас с методами
извлечения и занесения данных в таблицы при помощи языка SQL.
Просмотр данных
Наипростейшей командой является
следующая:* FROM mysql;
Эта команда подразумевает, что в активной
базе данных существует таблица mysql, из которой она просто извлекает все
данные и выводит их на экран.
Замечание: На SQL-команды распространяется
одно ограничение, которое не имеет отношения к командам MySQL - инструкции SQL
обязательно должны заканчиваться точкой с запятой. Это позволяет вводит
многострочные запросы к бызе данных, что не требуется для MySQL-команд, которые
как правило лаконичные и короткие.
Как вы уже наверное поняли, команда SELECT
служит для просмотра данных таблиц. Ее упрощенный синтаксис таков: <список
полей> FROM <список названий таблиц> [WHERE <список условий>]
[ORDER BY <список полей>];
В списке поля может быть как один элемент,
так и несколько; кроме того возможно указание символа "*" (), который
говорит, что следует показать все поля таблицы. Часть WHERE ... является
необязательной и позволяет выбрать из таблицы строки, удовлетворяющие
определенному(ым) условию(ям). Раздел ORDER BY ... служит для сортировки
полученных данных по определенным полям.
Вот пример более сложного запроса,
демонстрирующий сказанное выше. Допустим таблица staff содержит информацию о
сотрудниках некоторой организации. Этот запрос находит записи о тех из них, кто
работает больше двух лет и кого не зовут Иваном.
SELECT name, project,
works_sincestaff> 'Иван' AND_since '1998-04-26';
Рассмотрим этот запрос. Первая строка велит
MySQL показать содержимое только полей name, project и works_since. Вторая
строка указывает на таблицу, в которой следует искать эти данные. Оставшаяся
часть запроса указывает критерии выбора - имя не должно быть 'Иван', а дата
быть более ранней, чем 26-е апреля 1998-го года. Вот пример вывода после такой
операции:
+----------+--------------+-------------+
| name | project | works_since |
+----------+--------------+-------------+
| Fred | Secret data |
1997-01-01 |
| Jonathan | Blue apples
| 1997-06-01 |
+----------+--------------+-------------+
Для показа данных одного поля может
использоваться такой запрос:
SELECT project FROM staff
ORDER BY project;
+-------------+
| project |
+-------------+
| Blue apples |
| Blue apples |
| Cornichons |
| Secret data |
| Secret data | +-------------+
Как видите, этот запрос просто выбирает
значения из нужного поля из каждой строки и выводит их, заодно сортируя по
(единственному) полю project, поэтому в результатах встречаются повторения. Для устранения их используется инструкция
DISTINCT:DISTINCT project FROM staff ORDER BY project;
+-------------+
| project |
+-------------+
| Blue apples |
| Cornichons |
| Secret data |
+-------------+
SQL позволяет производить некоторые
вычисления и получать некоторую описательную информацию при помощи агрегатных
функций. Среди этих функций - COUNT, SUM, MAX, MIN и AVG.
COUNT - вычисляет количество найденых
строк
SUM - находит сумму значений в найденых
строках
MAX - находит найбольшее среди найденых
значений
MIN - находит наименьшее среди найденых
значений
AVG - находит среднее значение от найденых
Используются эти функции как элементы
списка таблиц в запросе с аргументом - названием поля. Вот несколько примеров.
COUNT (project) FROM
staff;MAX (projects_done) FROM staff;AVG (project_done) FROM staff
Эти запросы находят количество выполняемых
проектов, наибольшее количество проектов, выполняемое одним человеком и среднее
количество проектов, в которых участвуют работники соответственно.
SQL также располагает средствами работы с
регулярными выражениями (работе с которыми в Perl вы можете ознакомиться,
прочтя соответствующую статью на нашем сайте). Для сравнения значения с
регулярным выражением используется оператор LIKE, а для конструирования
простеших выражений - символы '_' (произвольный символ) и '%' (произвольное
количество произвольных символов). Пример. Этот запрос находит все имена,
которые начинаются с 'Jo':
SELECT name FROM
staffname LIKE 'Jo%n';
+----------+
| name |
+----------+
| Jonathan |
| John |
+----------+
MySQL также позволяет производить более
развитое сравнение с шаблоном при помощи оператора REGEXP и средств построения
шаблона теми же методами, что используются в Perl (см. Регулярные выражения в Perl).
name, project FROM
staffproject REGEXP "[bB]";
Этот запрос выведет все строки, в которых
название проекта содержит букву 'b' вне зависимости от регистра.
И последнее по порядку, но не по значению
- использование более чем одной таблицы. Особенность заключается в том, что
используемые таблицы могут иметь общие поля, которыми они связаны. Для того,
чтобы точно указывать, о поле какой таблицы идет речь, используется запись типа
staff.project, где перед точкой стоит название таблицы, а после нее - название
поля. Второй вариант - назначения псевдонимов (алиасов) таблицам для большего
удобства. Для этого в списке таблиц название каждой таблицы указывается вместе
с псевдонимом - например stuff x, projects y.
SELECT x.name, x.project,
x.descriptionstaff x, projects x.project = x.project_name;
В этом примере объединяются таблицы staff
и projects, причем выводятся имя сотрудника, проект над которым он работает и
описание этого проекта.
+----------+-------------+------------------------------+
| name | project |
description |
+----------+-------------+------------------------------|
| Jonathan | Blue apples
| Worldwide apple distribution |
| Fred | Secret data |
Secret data |
| John | Secret data |
Secret data |
+----------+-------------+------------------------------+
Объединив все это в один запрос получим
следующее:
SELECT DISTINCT
y.project_name, y.description, COUNT(x.name), FROM staff x, projects
yWHERE.project_name = x.project AND.project_name > 'Secret data' AND.project_name
LIKE "Wo__d%"BY_name;
+--------------+--------------------------+-------------+
| project_name |
description | COUNT(name) |
+--------------+--------------------------+-------------+
| Blue apples | Worldwide
apple delivery | 3 |
+--------------+--------------------------+-------------+
Этот запрос показывает названия проектов,
описания их и количество сотрудников, которые заняты в них для тех проектов,
которые не являются секретными и описания которых начинаются с 'Wo', следом за
которыми идут еще два символа, после чего - 'd' и дальше что угодно, и
сортирует единственное значение по полю project_name.
Редактирование данных
Редактирование данных - это добавление,
удаление и изменение их. Для выполнения этих операций используются команды
INSERT, DELETE и UPDATE соответственно.
Команда INSERT служит для вставки строк в
таблицы. Вот как может выглядеть такой запрос:
INSERT INTO staff VALUES
("Robert", "1980-05-07", "2000-04-26",
"$100", "Secret
data");
Возможна также вставка отдельных значений.
В таком случае необходимо указать, в какие поля стоит вставлять данные, причем
оставшиеся поля будут незаполнены - при выполнении запросов SELECT они будут
представлены как NULL - специальное начение, означающее, что данное
отсутствует.
INSERT INTO staff(name,
date_of_birth) VALUES ("Jack", "1977-07-29");* FROM
staffname = "Jack";
+------+---------------+-------------+---------+---------+
| name | date_of_birth |
works_since | project | sallary |
+------+---------------+-------------+---------+---------+
| Jack | 1997-07-29 | NULL | NULL |
NULL |
+------+---------------+-------------+---------+---------+
Удаление данных производится командой
DELETE. Для этого нужно указать таблицу и (необязательно) условия, которым
должны удовлетворять строки, которые следует удалить. Если условия опущены, эта
команда, как и SELECT, проделает эту операцию надо всеми строками - то есть
очистит таблицу.
DELETE FROM staff=
"Jack";
Изменение данных производится при помощи
команды UPDATE. Необходимо указать, значения каких полей следует изменить, а
также (опять же необязательно) условия, которым должны удовлетворять строки,
которые следует обновить.
UPDATE staff_since =
"2000-04-26"= "$200"= "Secret data"=
"Jack";
ПРИЛОЖЕНИЕ 3 - Список основных консольных
команд Ubuntu Server
/home перейти в директорию
‘/home’.. перейти в директорию уровнем выше../.. перейти в директорию
двумя уровнями выше перейти в домашнюю директорию~user перейти
в домашнюю директорию пользователя user- перейти в директорию, в которой находились
до перехода в текущую директорию показать текущюю директорию отобразить
содержимое текущей директории-F отобразить содержимое текущей директории
с добавлением к именам символов, храктеризующих тип-l показать детализированое
представление файлов и директорий в текущей директории-a показать скрытые
файлы и директории в текущей директории*[0-9]* показать файлы и
директории содержащие в имени цифры показать дерево файлов и директорий,
начиная от корня (/) dir1 создать директорию с именем ‘dir1′dir1 dir2 создать
две директории одновременно-p /tmp/dir1/dir2 создать дерево директорий-f
file1 удалить файл с именем ‘file1′dir1 удалить директорию с
именем ‘dir1′-rf dir1 удалить директорию с именем ‘dir1′ и
рекурсивно всё её содержимое-rf dir1 dir2 удалить две директории и
рекурсивно их содержимоеdir1 new_dir переименовать или переместить файл
или директориюfile1 file2 сопировать файл file1 в файл file2dir/* . копировать
все файлы директории dir в текущую директорию-a /tmp/dir1 . копировать
директорию dir1 со всем содержимым в текущую директорию-a dir1 dir2 копировать
директорию dir1 в директорию dir2-s file1 lnk1 создать символическую
ссылку на файл или директориюfile1 lnk1 создать «жёсткую» (физическую)
ссылку на файл или директорию-t 0712250000 fileditest модифицировать
дату и время создания файла, при его отсутствии, создать файл с указанными
датой и временем (YYMMDDhhmm)
Поиск файлов / -name file1 найти
файлы и директории с именем file1. Поиск начать с корня (/)/ -user user1 найти
файл и директорию принадлежащие пользователю user1. Поиск начать с корня
(/)/home/user1 -name «*.bin» Найти все файлы и директории, имена которых
оканчиваются на ‘. bin’. Поиск начать с ‘/ home/user1′/usr/bin -type f
-atime +100 найти все файлы в ‘/usr/bin’, время последнего обращения к
которым более 100 дней/usr/bin -type f -mtime -10 найти все файлы в
‘/usr/bin’, созданные или изменённые в течении последних 10 дней/ -name *.rpm
-exec chmod 755 ‘{}’ \; найти все фалы и директории, имена которых оканчиваются
на ‘.rpm’, и изменить права доступа к ним/ -xdev -name «*.rpm» найти все
фалы и директории, имена которых оканчиваются на ‘.rpm’, игнорируя съёмные
носители, такие как cdrom, floppy и т.п.«*.ps» найти все файлы,
сожержащие в имени ‘.ps’. Предварительно рекомендуется выполнить команду
‘updatedb’halt показывает размещение бинарных файлов, исходных кодов и
руководств, относящихся к файлу ‘halt’halt отображает полный путь к файлу
‘halt’
Монтирование файловых систем/dev/hda2
/mnt/hda2 монтирует раздел ‘hda2′ в точку монтирования ‘/mnt/hda2′.
Убедитесь в наличии директории-точки монтирования ‘/mnt/hda2′/dev/hda2 размонтирует
раздел ‘hda2′. Перед выполнением, покиньте ‘/mnt/hda2′-km /mnt/hda2 принудительное
размонтирование раздела. Применяется в случае, когда раздел занят каким-либо
пользователем-n /mnt/hda2 выполнить размонитрование без занесения информации
в /etc/mtab. Полезно когда файл имеет атрибуты «только чтение» или недостаточно
места на диске/dev/fd0 /mnt/floppy монтировать флоппи-диск/dev/cdrom
/mnt/cdrom монтировать CD или DVD/dev/hdc /mnt/cdrecorder монтировать
CD-R/CD-RW или DVD-R/DVD-RW(+-)-o loop file.iso /mnt/cdrom смонтировать
ISO-образ-t vfat /dev/hda5 /mnt/hda5 монтировать файловую систему
Windows FAT32-t smbfs -o username=user,password=pass //winclient/share
/mnt/share монтировать сетевую файловую систему Windows (SMB/CIFS)-o
bind /home/user/prg /var/ftp/user «монтирует» директорию в директорию
(binding). Доступна с версии ядра 2.4.0. Полезна, например, для предоставления
содержимого пользовательской директории через ftp при работе ftp-сервера в
«песочнице» (chroot), когда симлинки сделать невозможно. Выполнение данной
команды сделает копию содержимого /home/user/prg в /var/ftp/user
Дисковое пространство -h отображает
информацию о смонтированных разделах с отображением общего, доступного и
используемого пространства(Прим.переводчика. ключ -hработает не во всех *nix
системах)-lSr |more выдаёт список файлов и директорий рекурсивно с
сортировкой по возрастанию размера и позволяет осуществлять постраничный
просмотр-sh dir1 подсчитывает и выводит размер, занимаемый директорией ‘dir1′
(Прим.переводчика. ключ -h работает не во всех *nix системах)-sk * | sort -rn отображает
размер и имена файлов и директорий, с соритровкой по размеру-q -a -qf
‘%10{SIZE}t%{NAME}n’ | sort -k1,1n показывает размер используемого дискового
пространства, занимаемое файлами rpm-пакета, с сортировкой по размеру (fedora,
redhat и т.п.)query -W -f=’${Installed-Size;10}t${Package}n’ | sort -k1,1n показывает
размер используемого дискового пространства, занимаемое файлами deb-пакета, с
сортировкой по размеру (ubuntu, debian т.
Пользователи и группыgroup_name создать
новую группу с именем group_name
groupdel group_name удалить группу group_name-n
new_group_name old_group_name переименовать группу old_group_name в new_group_name-c «Nome Cognome» -g admin -d
/home/user1 -s /bin/bash user1 создать пользователя user1, назначить ему в качестве домашнего каталога /home/user1, в качестве shell’а /bin/bash, включить его в группу admin и добавить комментарий Nome Cognome
useradd user1 создать пользователя
user1-r user1 удалить пользователя user1 и его домашний каталог
usermod -c «User FTP» -g
system -d /ftp/user1 -s /bin/nologin user1 изменить атрибуты пользователя
passwd сменить парольuser1 сменить
пароль пользователя user1 (только root)-E 2005-12-31 user1 установить
дату окончания действия учётной записи пользователя user1 проверить
корректность системных файлов учётных записей. Проверяются файлы /etc/passwd и
/etc/shadow проверяет корректность системных файлов учётных записей.
Проверяется файл/etc/group[-] group_name изменяет первичную группу
текущего пользователя. Если указать «-», ситуация будет идентичной той, в
которой пользователь вышил из системы и снова вошёл. Если не указывать группу,
первичная группа будет назначена из /etc/passwd
Выставление/изменение полномочий на файлы -lh просмотр
полномочий на файлы и директории в текущей директории/tmp | pr -T5 -W$COLUMNS вывести
содержимое директории /tmp и разделить вывод на пять колонокugo+rwx directory1 добавить
полномочия на директорию directory1 ugo(User Group Other)+rwx(Read Write
eXecute) - всем полные права. Аналогичное можно сделать таким образом chmod 777
directory1go-rwx directory1 отобрать у группы и всех остальных все
полномочия на директорию directory1.user1 file1 назначить владельцем файла
file1 пользователя user1-R user1 directory1 назначить рекурсивно владельцем
директории directory1 пользователя user1group1 file1 сменить группу-владельца
файла file1 на group1user1:group1 file1 сменить владельца и группу владельца
файла file1/ -perm -u+s найти, начиная от корня, все файлы с выставленным SUID
chmod u+s
/bin/binary_file назначить SUID-бит файлу /bin/binary_file. Это даёт возможность любому пользователю
запускать на выполнение файл с полномочиями владельца файла.
chmod u-s
/bin/binary_file снять SUID-бит с файла
/bin/binary_file.g+s /home/public назначить SGID-бит директории
/home/public.g-s /home/public снять SGID-бит с директории
/home/public.o+t /home/public назначить STIKY-бит директории /home/public.
Позволяет удалять файлы только владельцамo-t
/home/public снять STIKY-бит с директории /home/public
Специальные атрибуты файлов +a file1 позволить
открывать файл на запись только в режиме добавления+c file1 позволяет
ядру автоматически сжимать/разжимать содержимое файла.+d file1 указавет
утилите dump игнорировать данный файл во время выполнения backup’а+i file1 делает
файл недоступным для любых изменений: редактирование, удаление, перемещение,
создание линков на него.+s file1 позволяет сделать удаление файла безопасным,
т.е. выставленный атрибут s говорит о том, что при удалении файла, место,
занимаемое файлом на диске заполняется нулями, что предотвращяет возможность
восстановления данных.+S file1 указывает, что, при сохранении изменений,
будет произведена синхронизация, как при выполнении команды sync+u file1 данный
атрибут указывает, что при удалении файла содержимое его будет сохранено и при
необходимости пользователь сможет его восстановить показать атрибуты файлов
Архивирование и сжатие файлов file1.bz2 разжимает
файл ‘file1.gz’
gunzip file1.gz file1 сжимает файл ‘file1′file1 -9
file1 сжать файл file1 с максимальным сжатиемa file1.rar
test_file создать rar-архив ‘file1.rar’ и включить в него файл test_filea
file1.rar file1 file2 dir1 создать rar-архив ‘file1.rar’ и включить в него file1, file2 и dir1x file1.rar распаковать rar-архивx file1.rar -cvf
archive.tar file1 создать tar-архив archive.tar, содержащий файл file1-cvf
archive.tar file1 file2 dir1 создать tar-архив archive.tar, содержащий файл file1, file2 и dir1
tar -tf archive.tar показать содержимое
архива-xvf archive.tar распаковать архив-xvf archive.tar -C /tmp распаковать
архив в /tmp-cvfj archive.tar.bz2 dir1 создать архив и сжать его с
помощью bzip2(Прим.переводчика. ключ -jработает не во всех *nix системах)-xvfj
archive.tar.bz2 разжать архив и распаковать его(Прим.переводчика. ключ -j
работает не во всех *nix системах)-cvfz archive.tar.gz dir1 создать
архив и сжать его с помощью gzip-xvfz archive.tar.gz разжать архив и
распаковать егоfile1.zip file1 создать сжатый zip-архив-r file1.zip
file1 file2 dir1 создать сжатый zip-архив и со включением в него
нескольких файлов и/или директорийfile1.zip разжать и распаковать
zip-архив
3.2.3 Физическая модель базы данных
.3 Создание таблиц базы данных
3.4 Создание скрипта отбора данных
3.5 Создание форм
4. ТЕХНИКО-ЭКОНОМИЧЕСКОЕ ОБОСНОВАНИЕ ПРОЕКТА РАЗРАБОТКИ БАЗЫ
ДАННЫХ УЧЕТА ТМЦ ДЛЯ ИП ЛИТВИНОВА А.Ю. ФИРМА «ЖЕСТЬ»
4.1 Общие положения
4.2 Определение ключевых показателей
4.3 Расчет объема капитальных вложений
![]() , (2)
, (2)
![]() =42 083 руб.
=42 083 руб.
![]() , (5)
, (5)
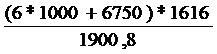 =10 840 руб.
=10 840 руб.
4.4 Расчет себестоимости базы данных
![]() , (8)
, (8)
![]() , (9)
, (9)
![]() .
.
![]() . (10)
. (10)
![]() ч.
ч.
![]() , (11)
, (11)
![]() ч.
ч.
![]() , (12)
, (12)
![]() ч.
ч.
![]() . (13)
. (13)
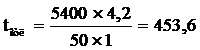 ч.
ч.
![]() , (14)
, (14)
![]() , (15)
, (15)
![]() ч.
ч.
![]() . (16)
. (16)
![]() ч.
ч.
![]() ч.
ч.
![]() , (17)
, (17)
![]() , (18)
, (18)
![]() , (19)
, (19)
![]() , (20)
, (20)
![]() , (21)
, (21)
![]() руб.
руб.
![]() руб.
руб.
![]() , (22)
, (22)
![]() час.
час.
![]() руб.
руб.
![]() руб.
руб.
![]() , (23)
, (23)
![]() руб.
руб.
4.5 Расчет финансовых результатов реализации проекта
![]() , (27)
, (27)
![]() , кг/ч
, кг/ч
![]() , (36)
, (36)
![]()
![]() , (38)
, (38)
![]() Вт
Вт
![]()
![]() , (39)
, (39)
![]() , (41)
, (41)
![]() (42)
(42)
![]() , (43)
, (43)
![]() , час.
, час.
![]() , (44)
, (44)
![]() , час.
, час.
![]() , (46)
, (46)
![]() , (47)
, (47)
![]() , (48)
, (48)
![]() , рублей
, рублей