Материал: Распределение системами управления базами данных
Распределение системами управления базами данных
Министерство образования науки и молодежной политики РД
ГПОБУ
"Республиканский
аграрно - экономический колледж"
Курсовой проект
По дисциплине: "Технология разработки и защиты баз данных"
На
тему:
"Распределение
системами управления базами данных"
Выполнила студентка гр.:П-31
Алпаутова А.Х
Руководитель:
Магомедбегов Р.Р
Хасавюрт
2014 г.
Содержание
Введение
. Распределение базы данных
.1 Основные понятие базы данных
.2 Система клиент сервер
.3 Преимущества и недостатки СУБД
. Отражение структуры организации
.1 Повышение доступности данных
.2 Повышение надежности
.3 Повышение производительности
. Экономические выгоды
.1 Модульность системы
.2 Повышение сложности
.3 Увеличение сложности
. Усложнение контроля за условность данных
.1 Отсутствие стандартов
.2 Недостатки опыта
Заключение
Список использованной литературы
Введение
Основной предпосылкой разработки систем,
использующих базы данных, является стремление объединить все обрабатываемые в
организации данные в единое целое и обеспечить к ним контролируемый доступ.
Хотя интеграция и предоставление контролируемого доступа могут способствовать
централизации, последняя не является самоцелью. На практике создание
компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный
подход, по сути, отражает организационную структуру многих компаний, логически
состоящих из отдельных подразделений, отделов, проектных групп и т.п., которые
физически распределены по разным офисам, отделениям, предприятиям или филиалам,
причем каждая отдельная производственная единица имеет дело с собственным
набором обрабатываемых данных. Разработка распределенных баз данных, отражающих
организационные структуры предприятий, позволяет сделать общедоступными данные,
поддерживаемые каждым из существующих подразделений, обеспечив при этом их
хранение именно в тех местах, где они чаще всего используются. Подобный подход
расширяет возможности совместного использования информации, одновременно
повышая эффективность доступа к ней. Цель:
Исследование возможностей распределенных СУБД.
Распределенные
системы призваны решить проблему информационных островов. Если на предприятии
имеется несколько баз данных, их иногда рассматривают как некие разрозненные
территории, представляющие собой отдельные и труднодоступные для многих места,
подобные удаленным друг от друга островам. Данное положение может являться
следствием географической разобщенности, несовместимости используемой
компьютерной архитектуры, несовместимости используемых протоколов связи и т.д.
Подобное положение дел способна изменить интеграция отдельных баз данных в одно
логическое целое.
1. Распределенные базы данных
Появление вычислительных систем с базами данных привело к смене прежних способов обработки данных, в которых для каждого приложения определялись и поддерживались собственные наборы данных, новыми, в которых все данные определялись и поддерживались централизованно. А в последнее время происходит быстрое развитие технологий сетевой связи и обмена данными, вызванное созданием Шете1, появлением мобильных и беспроводных вычислительных средств, а также "интеллектуальных" устройств. Теперь под влиянием этих двух противоположных тенденций технология распределенных баз данных способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления распределенными базами данных является одним из самых больших достижений в области баз данных.
В основном мы рассматривали централизованные системы баз данных, т.е. системы, в которых единственная логическая база данных размещалась в пределах одного узла и находилась под управлением одной СУБД (данные из источников передавались в центральный вычислительный центр с супер ЭВМ и там обрабатывались).
Теперь обсудим принципы и проблемы, связанные с
распределенными СУБД, позволяющими конечным пользователям иметь доступ не
только к данным, сохраняемым на их собственном узле, но и к данным, размещенным
на различных удаленных узлах. В прессе уже неоднократно делались заявления о
том, что в связи с нарастающим процессом перехода организаций к технологии
распределенных баз данных централизованные базы данных буквально через
несколько лет превратятся в антикварную редкость.
1.1 Основные понятия
Чтобы начать обсуждение проблем, связанных с распределенными СУБД, прежде всего необходимо уяснить, что же такое распределенная база данных.
Распределенная база данных - набор логически связанных между собой совокупностей разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети.
Из этого вытекает следующее определение распределенной СУБД:
Распределенная СУБД - программный комплекс, предназначенный для управления распределенными базами данных и обеспечивающий прозрачный доступ пользователей к распределенной информации.
Распределенная система управления базой данных (распределенная СУБД) состоит из единой логической базы данных, разделенной на некоторое количество фрагментов. Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, работающих под управлением отдельных СУБД и соединенных между собой сетью связи. Любой узел способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (т.е. каждый узел обладает определенной степенью автономности), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения могут подразделяться на не требующие доступа к данным на других узлах (локальные приложения) и требующие подобного доступа (глобальные приложения). В распределенной СУБД должно существовать хотя бы одно глобальное приложение, поэтому любая такая СУБД должна иметь следующие характеристики:
• имеется набор логически связанных разделяемых данных;
• сохраняемые данные разбиты на некоторое количество фрагментов;
• может быть предусмотрена репликация фрагментов данных;
• фрагменты и их копии распределяются по разным узлам;
• узлы связаны между собой сетевыми соединениями;
• доступ к данным на каждом узле происходит под управлением СУБД;
• СУБД на каждом узле способна поддерживать автономную работу локальных приложений;
• СУБД каждого узла поддерживает хотя бы одно
глобальное приложение;
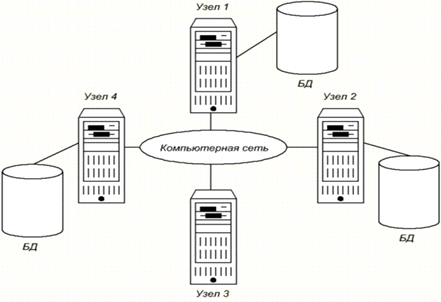
Но нет необходимости в том, чтобы на каждом из
узлов системы существовала своя собственная локальная база данных, что и
показано на примере топологии распределенной СУБД, представленной на рисунке
1:Рис. 1. Топологии распределенной СУБД, с локальной базой данных на каждом из
узлов системы.
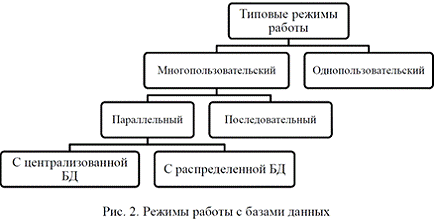
В общем случае режимы использования БД имеют вид (рис. 2):
Рассмотри основные понятия, применяемые в системах управления распределенными базами данных.
Архитектура клиент-сервер - структура локальной сети, в которой применено распределенное управление сервером и рабочими станциями (клиентами) для максимально эффективного использования вычислительной мощности.
Атрибут - характеристика элемента данных в объекте.
Вызов процедуры - передача управления подпрограмме или процедуре с последующим возвратом к основной программе по окончании выполнения подпрограммы или процедуры.
Вызов удаленной процедуры (RemoteProcedureCall) - вызов процедуры с другого компьютера.
Запрос - процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Инкапсуляция - объединение данных и программы (кода) в "кап¬суле", модуле.
Класс - объединяющая концепция набора объектов, имеющих общие характеристики (атрибуты).
Компонент - аналог класса в приложении Delphi.
Клиент - компьютер, обращающийся к совместно используемым ресурсам, которые предоставляются другим компьютером (сервером).
Логическая структура БД - определение БД на физически независимом уровне; ближе всего соответствует концептуальной модели БД.
Локализация (размещение) - распределение данных по узлам (участкам) сети с учетом дублирования (наличия копий).
Локальная автономность означает, что информация локальной БД и связанные с ней определения данных принадлежит локальному владельцу и им управляются.
Локальная вычислительная сеть (ЛВС) - коммуникационная система, поддерживающая в пределах здания или некоторой другой территории один или несколько скоростных каналов передачи цифровой информации, предоставленных подключенным устройствам для кратковременного монопольного использования.
Метод - набор подпрограмм, оперирующих с данными.
Наследование - передача определенных свойств от класса к его производному.
Объект - комбинация элементов данных, характеризующихся атрибутами, и методов их обработки, упакованных вместе в одном модуле.
Пользователь БД - программа или человек, обращающийся к базе данных
Полиморфизм - возможность переопределения процедуры в производном классе.
Прозрачность - устройство или часть программы, которая работает настолько четко и просто, что ее действия незаметны пользователю.
Распределенный запрос - запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Свойство - аналог атрибута в приложении Delphi.
Сервер - узловая станция компьютерной сети, предназначенная в основном для хранения данных коллективного пользования и для обработки в ней запросов, поступающих от пользователей других узлов.
Событие - сигнал запуска метода.
Среда (ComputerAidedSoftwareEngineering - CASE) - среда создания программного обеспечения, ориентированная на разработку программы от планирования и моделирования до кодирования и документирования.
Топология БД, или структура распределенной БД, - схема распределения физической организации базы данных в сети.
Транзакция - последовательность операций модификации данных в БД, переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Удаленный запрос - запрос, который выполняется с использованием модемной связи.
Фрагмент логический - блок данных, однородных для транзакций с точки зрения доступа.
Фрагментация (расчленение) - процесс разбиения целостного объекта глобального типа на несколько частей (фрагментов).
Фрагмент хранимый - физическая реализация логического фрагмента.
Шлюз - устройство для соединения разнотипных сетей, работающих по разным протоколам.
Возможность реализации удаленной транзакции - обработка одной транзакции, состоящей из множества SQL-запросов, на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле.
Большинство требований, предъявляемых к распределенным БД, аналогично требованиям к централизованным БД, но их реализация имеет свою, рассматриваемую ниже специфику. В частности, в распределенной БД иногда полезна избыточность.
Дополнительными специфическими требованиями являются:
• язык описания данных (ЯОД) в рамках схемы должен быть один для всех локальных БД;
• доступ должен быть коллективным к любой области РБД с соответствующей защитой информации;
• подсхемы должны быть определены в месте сосредоточения алгоритмов (приложений, процессов) пользователя;
• степень централизации должна быть разумной;
• необходим сбор и обработка информации об эффективности функционирования РБД.
В дальнейшем К. Дейт сформулировал 12 правил для РБД.. Локальная автономность.
. Отсутствие опоры на центральный узел.
.Непрерывное функционирование (развитие) РБД.
.Независимость РБД от расположения локальных БД.
.Независимость от фрагментации данных.
.Независимость от репликации (дублирования) данных.
. Обработка распределенных запросов.
. Обработка распределенных транзакций.
. Независимость от типа оборудования.
. Независимость от операционной системы.. Независимость от сетевой архитектуры.
. Независимость от типа СУБД.
Схема распределенной БД может быть представлена
в виде, показанном на рис. З.
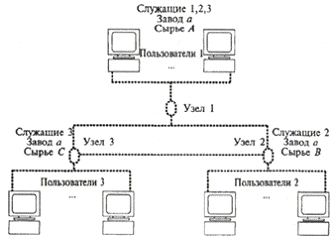
Рис. 3. Схема распределенной БД
В ней выделяют пользовательский, глобальный
(концептуальный), фрагментарный (логический) и распределенный (локальный)
уровни представления данных (рис. 4), определяющие сетевую СУБД.
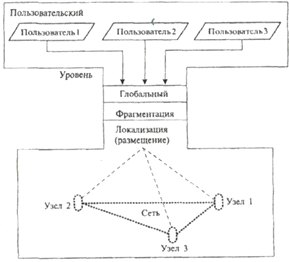
Рис. 4. Уровни представления данных в
распределенной БД
Пользовательский уровень состоит из фрагментов глобального уровня, которые составляют фрагментарный, логический уровень.
Выделяют горизонтальную и вертикальную фрагментации (расчленение). Горизонтальная фрагментация связана с делением данных но узлам. Горизонтальные фрагменты не перекрываются. Вертикальная фрагментация связана с группированием данных по задачам.
Фрагментация чаще всего не предполагает дублирования информации в узлах. В то же время при размещении фрагментов по узлам (локализации) распределенного уровня в узлах разрешается иметь копии той или иной части РБД.
После размещения данных каждый узел имеет локальное, узловое представление (локальная логическая модель). Физическую реализацию (логического) фрагмента называют хранимым фрагментом.
Сеть в распределенной БД образуют сетевые операционные системы (например, Windows NT, NovellNetWare). В качестве СУБД, изначально предназначавшихся для использования в сети, следует назвать BTrieve, Oracle, InterBase, Sybase, Informix.
В силу распределённой данных особую значимость приобретает словарь данных (справочник) распределенной БД, который в отличие от словаря централизованной БД имеет распределенную, многоуровневую структуру.
В общем случае могут быть выделены сетевой, общий внешний, общий концептуальный, локальные внешние, локальные концептуальные и внутренние составляющие словаря распределенной БД.
Естественно, что для работы в распределенной БД необходимы администраторы распределенных БД и локальных БД, рабочими инструментами которых являются перечисленные словари.
Схема работы распределенной БД показана на рис.
5.
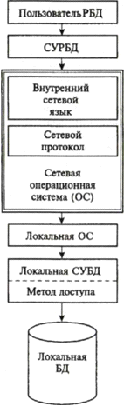
Рис. 5. Схема работы распределенной базы данных
Пользовательский запрос, определяемый приложением, поступает в систему управления распределенной базы данных (СУРБД), через сетевую и локальную операционные системы попадает в локальную СУБД. Если запрос связан с локальными данными, СУБД осуществляет вызов данных из локальной БД, которые поступают пользователю. Если часть данных для выполнения приложения находится в другой локальной БД, локальная СУБД дополнительно через локальные и сетевую операционные системы осуществляет удаленный вызов процедуры (RemoteProcedureCall - PRC), после выполнения которой данные передаются пользователю.