Материал: Работа в аналитической платформе Deductor Studio
Имя столбца - указывается имя, которое будет служить идентификатором столбца в последующих узлах. По умолчанию предлагается заголовок столбца из текстового файла, если на предыдущем шаге был установлен флажок Первая строка является заголовком. Иначе будут предложены имена типа COL1, COL2 и т. д. Можно ввести любые имена, которые семантически отражают содержимое столбца, однако допускаются только латинские символы, и имя столбца должно быть уникальным в пределах всех столбцов импортируемого файла.
Метка столбца - название, под которым данный
столбец будет виден в визуализаторах. Допускаются любые символы, уникальность
имен не обязательна. Тип данных - указывается тип данных, содержащихся в
столбце. Тип выбирается из списка, открываемого щелчком по кнопке в правой
части поля? Доступные типы данных представлены в таблице 2.
Таблица 2
Типы данных в платформе Deductor
|
Тип Описание |
|
|
Логический дата/время вещественный целый строковый |
данные в поле могут принимать только два значения - 0 или 1 поле содержит данные типа дата/время числа с плавающей точкой целые числа строки символов |
Узел импорта всегда пытается автоматически распознать тип данных по первой строке файла (если имеются заголовки, то по второй строке). Такой алгоритм срабатывает не всегда.
Непрерывными могут быть только числовые данные. Дискретный характер носят, как правило, строковые данные, но не всегда.
Дискретными могут быть назначены в зависимости от контекста решаемой задачи данные целого типа, реже - вещественного. Вид данных столбца влияет на:
алгоритм расчета статистики по столбцу;
работу аналитических алгоритмов.
Назначение - определяет порядок использования
поля набора данных, полученного в результате импорта столбца (поля) при
дальнейшей обработке импортированных данных, примеры назначений представлены в
таблице 3.
Таблица 3.
Назначения полей в платформе Deductor
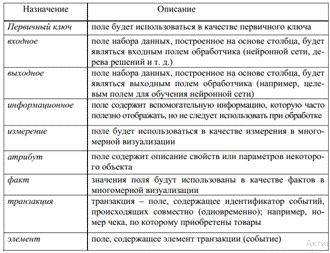
Изменить назначение группы столбцов одной операцией можно следующим образом:
удерживая клавишу Shift, выделить мышкой или клавишами Ctrl+↓, Ctrl+↑ первый и последний столбцы группы столбцов и изменить их назначение;
удерживая клавишу Ctrl, выделить мышкой только нужные столбцы и изменить их назначение.
На шаге Запуск процесса импорта стартует сам процесс импорта данных с ранее настроенными параметрами. Ход процесса импорта отображается с помощью индикатора. Если процесс импорта остановился, это сигнализирует о возможных ошибок при чтении данных. В этом случае появляется окно с сообщением об ошибке.
Пуск - запускает процесс в первый раз или возобновляет после паузы;
Пауза - временно приостанавливает импорт.
Стоп - останавливает процесс без возможности его продолжения.
На оставшихся двух шагах мастера импорта будет предложено выбрать визуализатор набора данных (по умолчанию предлагается Таблица) и задать сведения об узле.
Следующим шагом будет формирование столбцов импортируемого шага, а затем запускаем процесс импорта данных из текстового файла. Последовательно выполняя команду Далее, переходим к способу отображения данных, выбирая из предложенного перечня.
К любому узлу импорта можно добавить узел
обработки или узел экспорта, предварительно выделив узел импорта мышью. Новый
узел будет добавлен как подчиненный к узлу импорта.

Рис. 7. Мастер обработки
Создание нового узла обработки осуществляется с помощью мастера обработки (Рис. 7). Вызвать мастер можно следующими способами:
кнопка Мастер обработки на панели инструментов закладки Сценарии;
клавиша F7;
контекстное меню Мастер обработки.
При вызове Мастера обработки откроется окно первого шага мастера.
В нем все обработчики сгруппированы по следующим четырем категориям:
Очистка данных;
Трансформация данных;
Data Mining;
Прочее.
Некоторые узлы могут отсутствовать в списке. Причины этого следующее:
версия Deductor;
отключена «видимость» объекта (или целой категории) объекта;
узел «устарел» и в текущей версии Deductor его создание невозможно (допускается только его чтение и настройка).
Вызвать Мастер обработки можно следующими способами:
кнопка Мастер Экспорта на панели инструментов закладки Сценарии;
клавиша F8;
контекстное меню Мастер экспорта...
В нем все приемники данных сгруппированы по следующим 5 категориям:
хранилища данных;
базы данных;
файлы;
Web-серверы;
прочее.
Причины отсутствия некоторых объектов или
категорий мастера экспорта аналогичны тем, что перечислены при описании мастера
импорта. После узла экспорта невозможно добавить ни один узел.
.3.4 Базовые операции над узлами сценария
Кроме команд вызова мастеров, к каждому узлу применимы базовые операции. Операции над узлами и ветками сценария можно выполнять следующими способами:
кнопки панели инструментов на закладке Сценарии;
контекстное меню;
мышь.
Список доступных операций.
. Открытие узла - узел запускается на выполнение, причем выполняются все родительские узлы, а справа открываются визуализаторы, настроенные для данного узла. В интерактивном режиме для каждого узла должен быть настроен хотя бы один визуализатор, например, Таблица или Сведения. Операция вызывается:
двойным щелчком мышью на узле;
клавишами Ctrl+Enter;
контекстным меню Открыть.
. Настройка узла - вызывается мастер импорта, мастер обработки или мастер экспорта, в зависимости от типа узла, для изменения параметров обработки, производимой в узле. Операция вызывается:
кнопкой;
клавишами Alt+Enter;
контекстным меню Настроить…
. Активация/деактивация узла - узел может быть либо активным, либо неактивным. Если узел неактивный, то, сделав его активным, выполнится сценарий для этого узла, но визуализаторы отображены не будут. Делая узелне активным, закрываются все визуализаторы для него и для всех подчиненных узлов, а сам узел и подчиненные узлы превращаются в неактивные. Эта операция может быть использована для освобождения памяти. Операция активации/деактивации вызывается:
клавишами Shift+Enter;
контекстным меню Активный…
. Перечитать данные узла - все узлы до корневого включительно будут закрыты, а затем выполнена ветка сценария от корневого до текущего узла. Операция вызывается контекстным меню Перечитать данные…
. Вырезать узел - удаляет текущий узел из сценария обработки.
Все его потомки при этом перемещаются на один уровень вверх и начинают подчиняться родителю удаленного узла. Операция вызывается:
кнопкой;
контекстным меню Вырезать узел.
. Вставить узел - вставляет перед текущим узлом сценария новый узел и вызывает для него мастер обработки. Вставить узел перед узлом импорта данных нельзя. Операция вызывается:
кнопкой;
контекстным меню Вставить узел.
После вставки нового узла или удаления существующего узлы потомки могут стать неработоспособными в зависимости от обработки, выполняемой новым узлом.
. Копировать ветвь - копирует ветвь сценария, начиная с текущего узла и включая все его потомки. Операция вызывается:
кнопкой;
контекстным меню Копировать ветвь;
при помощи механизма drag & drop - выделив узел и удерживая нажатой клавишу Ctrl, указать курсором мыши на новый узел, который должен стать родителем старого. При этом переносимая ветка целиком скопируется в новое место.
. Удалить ветвь - удаляет узел сценария и все его под-узлы. Удаленная ветвь восстановлению не подлежит, поэтому к данной операции необходимо подходить с осторожностью. Операция вызывается:
кнопкой;
клавишами Ctrl+Del;
контекстным меню Удалить ветвь.
. Перенос ветви - переносит ветку сценария к новому узлу. Операция производится аналогично копированию ветви с помощью drag & drop без удерживания клавиши Ctrl.
. Переименовать - позволяет изменить метку текущего узла. Операция вызывается:
клавишей F2;
. Сведения - открывает диалоговое окно Сведения для текущего узла. В нем редактируется имя, метка и описание к узлу. Операция вызывается:
контекстным меню Сведения...;
открыв скрытую панель узла с помощью кнопки и нажать там одну из кнопок:
Имя, Метка или Описание.
Имя узла может быть задано только латинскими символами, тогда как метка - любыми. Кроме того, имя узла должно быть уникально в пределах одного сценария. Как правило, необходимости в переименовании имен узлов не возникает.
. Статус пакетной обработки - устанавливает статус пакетной обработки для узла.
. Добавить в Избранное - текущий узел добавляется в список избранных узлов.
. Сохранение ветви - вызывается стандартный диалог Сохранение, в котором можно указать путь и имя файла для сохранения ветви сценария, начинающейся с текущего узла. Операция вызывается контекстным меню Сохранить ветвь.
. Загрузка ветви - вызывает стандартный диалог Открытие файла, в котором можно указать путь и имя файла, хранящего ветвь сценария. Загруженная ветвь сценария станет потомком текущего узла. Ветвь, начинающаяся с узла импорта данных, будет добавлена в проект как новая корневая ветвь. Операция вызывается контекстным меню Загрузить ветвь.
По умолчанию ветвь сценария имеет расширение
*.deb.
2.3.5 Экспорт в текстовый файл
Выполняется при помощи мастера экспорта. В нем процесс экспорта данных в текстовый файл с разделителями (категория Файлы) содержит следующие шаги:
настройка форматов экспорта;
указание символа-разделителя столбцов;
выбор экспортируемых полей;
запуск процесса экспорта;
выбор способа визуализации;
задание сведений об узле.
На шаге Настройка параметров экспорта задаются параметры экспорта данных из текстового файла аналогично тем, что задавались в мастере импорта. Экспортироваться будут не все поля, а только те, у которых поднят флажок на шаге Выбор экспортируемых полей.
Здесь же задается имя файла экспорта. По
умолчанию предлагается имя файла export.txt. Как и в случае с импортом,
допускается использовать относительные пути.
.4 Создание базы данных и построение диаграмм
Для начала нужно создать свою базу данных.
Поскольку Deductor умеет работать с текстовыми файлами как с базами данных, то
за основу возьмем именно этот формат файла. Создадим текстовой документ с
именем base.txt. Теперь нужно определиться со структурой файла, поскольку он
будет являться базой данных, то все его данные должны быть логически разделены
по какому-то признаку. Для разделения колонок в базе данных возьмем за основу
разделитель «табуляция», а за основу разделения строк в базе данных будет
являться «Enter» знак перехода на новую строку. Заполним документ данными, как
это выглядит на рисунке 8.
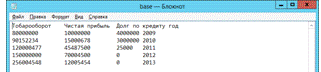
Рис. 8. Содержимое файла base.txt
Откроем программу Deductor Studio Academic как
показано на рисунке 9.
Рис. 9. Старт
программы
Deductor Studio Academic
В левой части экрана есть объект с именем
«Сценарий», нажав правой кнопкой мыши по нему всплывет меню объекта как
показано на рисунке 10 и выберем пункт «Мастер импорта».
Рис. 10 Меню объекта «Сценарий»
В появившемся мастере импорта (рис. 11) выберем файл данных «Текстовой файл» и жмем кнопку далее.
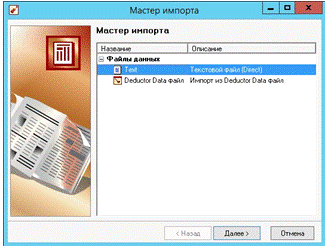
Рис.11. Мастер импорта
В следующем окне (рис.12) выбираем файл данных
base.txt и жмем кнопку «Далее». В окне мастера «3 из 9» (рис. 13) соглашаемся с
условиями выбранными разделителями и жмем кнопку далее. В окне мастера «4 из 9»
(рис.14) жмем кнопку далее. В окне мастера «5 из 9» свойства всех объектов
выставляем как показано на рис. 13. В окне мастера «6 из 9» жмем «Далее». В
окне мастера «7 из 9» (рис 15) жмем кнопку «Пуск», а затем «Далее». В окне
мастера «8 из 9» (рис. 16) жмем кнопку «Далее», а в «9 из 9» копку «Готово»
(рис. 17). По завершению всех операций в главном окне программы появятся
таблицы с импортированными данными (рис. 18).
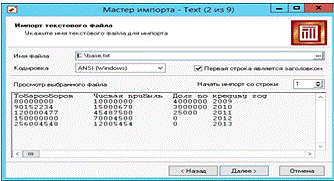
Рис.12. Выбор файла для импорта
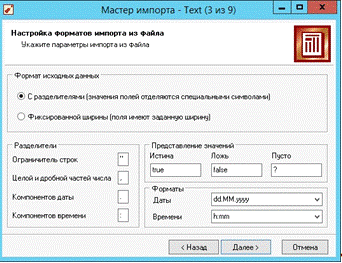
Рис. 13. Настройка формата файла для импорта
Рис. 14. Выбор символа - разделителя для импорта
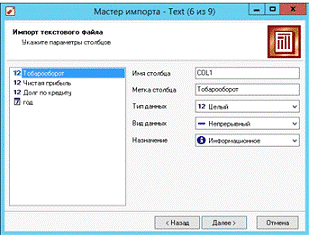
Рис. 15. Настройка параметров столбцов для
импорта
Рис. 16. Запуск процесса импорта
Рис. 17. Определение способов отображения
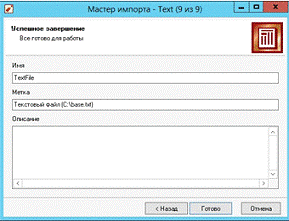
Рис. 18. Завершение импорта файла

Рис. 19. Начало работы с импортированным файлом
Так же можно заметить, что ниже объекта
«Сценария» создался еще один объект «Текстовой документ». Пришло время
построить отчет в виде диаграмм над анализируемыми данными. Для этого по
объекту «Текстовой документ» нужно щелкнуть правой кнопкой мыши и в появившемся
меню выбрать пункт «Мастер визуализации» как показано на рис. 20.
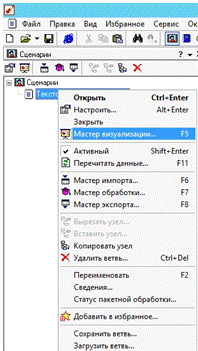
Рис. 20. Мастер визуализации
Откроется окно «Мастер Визуализации» (рис. 20)
на котором нужно продолжить работу мастера нажав на кнопку «Далее»
Рис. 21. Мастер визуализации
В следующем окне мастера визуализации «2 из 3»
выбираем типы визуализации установкой слева от них галочек, как показано на
рис. 22.
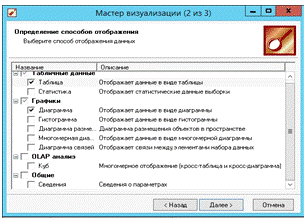
Рис. 22. Мастер визуализации
В следующем окне мастера визуализации
настраиваем данные согласно рисунку 23.
Рис. 23. Мастер визуализации
Далее нам приходится только нажать на кнопку
«Готово» для завершения построения визуализации анализируемых данных (рис. 24).
Рис. 24. Мастер визуализации
После этого окно мастера закроется, а на главной
области программы появится новая вкладка «Диаграмма», щелкнув по которой левой
кнопкой мыши нам откроется созданный отчет с применением визуализации на основе
диаграмм, как показано на рис. 25.
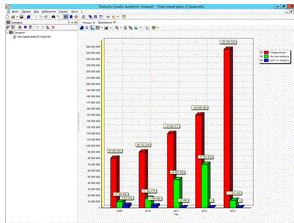
Рис. 25
ЗАКЛЮЧЕНИЕ
Практика экономической жизни требует непрерывного обновления знаний и умения добывать их. Обработка накопленных данных, проведение анализа их и построение прогнозов на основе полученной информации являются актуальными проблемами не только финансовых аналитиков, но и практикующих финансовых менеджеров. Наличие специализированных программных средств, позволяющих не просто интерпретировать полученную информацию в виде таблиц и графиков, но и создавать на их базе информационные системы с аналитическими свойствами позволяет значительно формализовать, ускорить и упростить рутинные процессы добывания знаний и принятия решений. Мы закрепили усвоенный теоретический материал практическим заданием и создали самостоятельно базу данных, которую впоследствии визуализировали на основе анализа данных.