Материал: Работа в аналитической платформе Deductor Studio

В Deductor сценарии отображаются в виде дерева с
иконками и пояснительным текстом (рис. 1.) Взглянув на это дерево, можно без
труда проследить логику сценария и понять особенности его реализации. Это
помогает не только модифицировать сценарии, но и передавать их другому
аналитику, который также просто сможет «прочесть» ход мысли аналитика,
создавшего сценарий. Анализ не ограничивается только обработкой данных,
визуализация данных позволяет значительно повысить результативность анализа. В
системе имеется множество удобных способов отображения данных. Программа
самостоятельно анализирует способы обработки, особенности набора данных, на
которых производился анализ и автоматически предлагает возможные способы
визуализации. Среди множества механизмов визуализации, встроенных в Deductor
Studio, имеется и мощный Online Analytical Processing (OLAP) модуль. OLAP -
один из наиболее популярных способов отображения табличных данных. Данные в
этом случае могут отображаться в виде кросс-таблиц или кросс-диаграмм. Кросс-таблицы
удобны тем, что большая часть операций манипулирования данных выполняется «на
лету». Одним щелчком мыши, можно данные сгруппировать произвольным образом,
отфильтровать, отсортировать, переставить столбцы/строки и произвести множество
других операций. Deductor Studio позволяет при помощи этого механизма
визуализации просмотреть любые данные, т. е. не только саму исходную
информацию, но и результаты любой обработки. Studio - это инструмент аналитика,
а он является ключевым лицом в процессе анализа данных, именно его знания
формализуются и тиражируются, но многие пользователи не являются аналитиками,
для них нужен более простой и понятный способ получения требуемой информации. В
Deductor Studio имеется панель отчетов, напоминающая проводник в известных операционных
системах. На этой панели аналитик формирует иерархическую структуру папок и в
определенные папки выносит ссылки на интересующие пользователей узлы сценария.
Viewer - это рабочее место конечного пользователя. В нем отсутствуют механизмы
построения сценариев, настройки источников, данных и прочие сложности. Работа с
программой упрощена до предела: пользователь видит настроенную аналитиком
панель отчетов, выбирает интересующий отчет, программа автоматически выполняет
все необходимые действия, и конечный пользователь получает результат. Эта
составляющая является частью более расширенных видов аналитической платформы и
в нашем случае не применяется, впрочем, как и Deductor Server/Client. Server
функционирует в виде Windows-службы, к которой можно обращаться удаленно при
помощи специального клиента - Deductor Client. Управлять выполнением сценарием
можно как из локальной сети, так и через Интернет. Использование Deductor
Server значительно упрощает создание полноценной корпоративной аналитической
системы, его применение позволяет воспользоваться всеми преимуществами
трехзвенной архитектуры, оптимально используя возможности серверной
аналитической обработки.
Глава II. ПРАКТИЧЕСКАЯ ЧАСТЬ
.1 Принципы работы
Импорт данных
Анализ любой информации в Deductor
начинается с импорта данных. В результате импорта данные приводятся к виду,
пригодному для последующего анализа при помощи всех имеющихся в программе
механизмов. Природа данных, формат, СУБД и прочее не имеют значения, т.к.
механизмы работы со всеми унифицированы. ![]() <#"774066.files/image002.gif"> <#"774066.files/image003.gif">
<#"774066.files/image002.gif"> <#"774066.files/image003.gif">
Рис. 2. Схема работы Deductor Studio
Studio позволяет аналитику автоматизировать рутинные операции по обработке данных и сосредоточиться на интеллектуальной работе: формализация логики принятия решений, построение моделей, прогнозирование. Остальные сотрудники компании могут легко воспользоваться готовыми результатами, не вникая в сложности анализа:
Аналитическая отчетность. Аналитик перетаскивает мышкой на специальную панель необходимые отчеты. Конечный пользователь при помощи Deductor Viewer просто выбирает интересующий отчет из списка и получает результат. Никаких дополнительных действий делать не требуется. Вся сложная аналитическая обработка выполняется автоматически.
Интеграция в бизнес-процесс. Аналитик экспортирует результаты в стороннюю систему: сайт, ERP, CRM и т.п., а конечный пользователь увидит в привычной ему программе итог сложной аналитической обработки. Обмен данными может производиться в режиме online или по регламенту. Для встраивания в бизнес-процесс необходимо воспользоваться Аnalytic или Integration Server.
Объединение всех описанных выше механизмов в
Deductor Studio обеспечивает принципиально новое качество анализа: быстрая
разработка и адаптация решений, интеграция в существующую инфраструктуру,
эволюционное развитие от простой отчетности к глубокой аналитике.
2.3 Работа в аналитической платформе
.3.1 Начало работы в аналитической платформе
Запустите Deductor в меню компьютера Пуск. После запуска главное окно Deductor Studio выглядит следующим образом. По умолчанию панель управления представлена одной вкладкой - Сценарии. Кроме того, доступны еще две вкладки: Отчеты и Подключения. Сделать их видимыми можно следующими способами:
главное меню Вид → Отчеты и Вид → Подключения - кнопки Отчетов и Подключений на панели инструментов.
Можно производить «drag & drop» манипуляции
с вкладками, меняя их расположение и порядок.
Рис. 3. Рабочая площадь платформы Deductor в
момент старта
При нажатии правой кнопки мыши на любой вкладке
появляется контекстное меню (рис. 4).
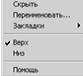
Рис. 4. Контекстное меню вкладки
- Скрыть - делает вкладку невидимой;
Переименовать - переименовывает название вкладки;
Закладки - переключается на выбранную закладку;
Верх/Низ - задает расположение названий вкладок: вверху либо внизу;
Помощь - открывает раздел справки.
.3.2 Понятие проекта
В Deductor Studio ключевым понятием является проект. Это файл с расширением *.ded, по структуре соответствующий стандартному xml-файлу. Он хранит в себе:
последовательности обработки данных (сценарии);
настроенные визуализаторы;
переменные проекта и служебную информацию.
Каждый проект имеет авторские сведения: Название, Версия, Автор, Компания, Описание. Они заполняются в диалоговом окне Свойства проекта (меню Файл→Свойства проекта…).
Создать новый проект можно следующими способами:
главное меню: Файл→Создать;
кнопка Создать новый проект на панели инструментов;
клавиша Ctrl+N.
Открытие существующего проекта:
главное меню: Файл→Открыть;
кнопка Открыть проект на панели инструментов;
клавиша Ctrl+O.
Открыть проект можно еще одним способом - в главном меню Файл→История найти имя проекта. Способ работает в том случае, если он сохранился в менеджере историй проектов.
В одной запущенной копии Deductor Studio можно открыть только один проект. В Deductor Studio вся работа ведется с использованием пяти мастеров:
Мастер импорта;
Мастер обработки;
Мастер визуализации;
Мастер подключений.
С помощью мастеров импорта, экспорта и обработки формируется сценарий. Сценарий состоит из узлов. Мастер подключений предназначен для создания настроек подключений к различным источникам и приемникам данных. Мастер визуализации настраивает визуализаторы для конкретного узла.
Визуализатором называется любое представление набора данных в како-либо виде: табличном, графическом, описательном.
Примеры визуализаторов: таблица, дерево,
гистограмма, диаграмма, OLAP-куб.
.3.3 Понятие сценария и узла обработки
В Deductor Studio для аналитика основополагающим понятием является сценарий. Сценарий представляет собой последовательность операций с данными, представленную в виде иерархического дерева. В дереве каждая операция образует узел, заголовок которого содержит: имя источника данных, наименование применяемого метода обработки, используемые при этом поля и т. д. Кроме этого, слева от наименования узла стоит значок, соответствующий типу операции (рис. 5).
Если узел имеет подчиненные узлы, то слева от
его названия будет расположен значок «+», щелчок по которому позволит
развернуть узел, т. е. сделать видимыми все его подчиненные узлы, при этом значок
«+» поменяется на «-». Щелчок по значку «-», наоборот, сворачивает все
подчиненные узлы.
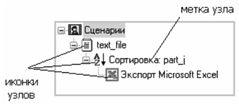
Рис. 5. Сценарная последовательность
С помощью клавиш Ctrl+↑ и Ctrl+↓ можно перемещать узлы по дереву вверх-вниз в пределах подчинения родительскому узлу. Сценарий состоит из ветвей. Deductor не имеет собственных средств для ввода данных, поэтому сценарий всегда начинается с узла импорта из какого-либо источника. Любой вновь создаваемый узел импорта будет находиться на верхнем уровне (подчиненным главному узлу - Сценарии).
Создание нового узла импорта осуществляется с помощью мастера импорта. Вызвать мастер можно следующими способами:
кнопка Мастер импорта на панели инструментов закладки Сценарии;
клавиша F6;
контекстное меню Мастер импорта.
При вызове мастера импорта откроется окно первого шага мастера (рис. 6, а).
В окне могут отражаться все источники данных, сгруппированных по следующим четырем категориям:
хранилища данных;
настроенные подключения;
файлы данных;
бизнес-подключения.
Однако в нашем случае некоторые категории отсутствуют в списке. Причины этого в следующем:
версия Deductor. Например, категории Настроенные подключения и Бизнес-подключения отсутствуют в версии Academic;
в дереве подключений (вкладка Подключения) не зарегистрировано ни одного объекта из данной категории. Например, если не настроено ни одного подключения к хранилищу данных, то категория Хранилища данных будет отсутствовать;
отключена «видимость» объекта или категории объекта.
Структурированный текстовый файл с разделителями
- в нашем случае единственный формат хранения данных. Этот файл представляет
собой обычный текстовый файл, столбцы данных в котором разделены однотипными
символами-разделителями, например, символами табуляции, пробела, точки с
запятой и так далее.
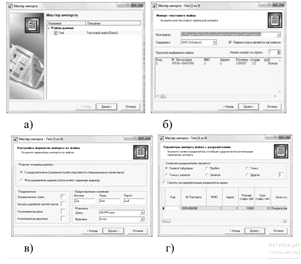
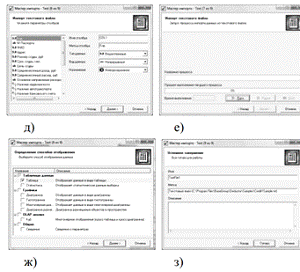
Рис. 6. Мастер импорта
Процесс импорта данных из текстового с разделителями файла в мастере импорта (категория текстовой файл (Direct)) последовательно отображена на рис. 6, б) и содержит следующие шаги:
указание имени файла;
настройка параметров импорта;
настройка импортируемых полей;
запуск процесса импорта;
выбор способа визуализации;
задание сведений об узле.
На шаге Указание имени файла, нажав кнопку, необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных. После этого в поле «Имя файла» окна Мастера импорта появится имя выбранного файла и путь. Допускается вручную ввести путь к файлу в строке поля «Имя файла». Имеется возможность использовать как абсолютные, так и относительные пути для файлов. Они указываются относительно текущей директории Deductor. При открытии Deductor текущей директорией является директория файла проекта. Поэтому, если файл проекта и текстовые файлы располагаются в одной папке, то использование относительных путей в Мастере импорта позволит не перенастраивать узлы импорта при изменении расположения папки на жестком диске.
Здесь также доступны настройки:
начать импорт со строки - номер строки, начиная с которой будет делаться импорт данных из файла;
флаг Первая строка является заголовком - установка флажка означает, что узел будет импортировать данные с учетом того, что все записи первой строки являются заголовками столбцов;
кодировка - ANSI (Windows) или ANCII (MS DOS).
На шаге Настройка параметров импорта (рис. 6, в, г) нужно настроить параметры импорта данных из текстового файла, так как существует несколько форматов структурированных текстовых файлов. Доступные опции:
переключатель Формат исходных данных, который определяет символ-разделитель в файле (например, символ табуляции, пробел, запятая). Разделитель чаще всего присутствует. Если же нет, то нужно выбрать переключатель Фиксированной ширины (поля имеют заданную ширину), а позже установить ширину каждого поля;
Ограничитель строк - при задании данного параметра необходимо указать, какой именно ограничитель строкового значения нужно использовать при импорте данных из текстового файла. Обычно таким ограничителем является символ двойной кавычки ";
Разделитель дробной и целой части числа - при задании данного параметра необходимо указать символ, разделяющий дробную и целую части в числовых значениях, содержащихся в файле;
Разделитель компонентов даты - указывается символ, разделяющий компоненты даты в соответствующих значениях, содержащихся в файле;
Разделитель компонентов времени - указывается символ, разделяющий компоненты времени в соответствующих значениях, содержащихся в файле;
Форматы Даты/Времени - указываются форматы даты/времени, используемые в импортируемом файле;
Представление значений - опция для полей логического типа, которое может принимать одно из трех значений - истина (true), ложь (false) и пустое значение (null).
Дальнейшие шаги мастера импорта будут зависеть от того, какой объект дерева категорий был выбран аналитиком (рис. 6, д). Выполняя рекомендации в открытом окне, последовательно выбираем требуемый для анализа файл в текстовом формате. Затем выбираем требуемый формат данных и переходим к заданию разделителей, назначая их из перечня. В качестве разделителей, представлений значений и форматов по умолчанию всегда предлагаются системные настройки операционной системы. Поэтому при импорте необходимо обращать внимание на их соответствие формату в импортируемом текстовом файле. Следующее окно мастера зависит от установленного переключателя в флажке Формат исходных данных. Если был выбран формат с разделителями, то появится вкладка, на которой нужно явно указать символ-разделитель (по умолчанию - табуляция). Здесь же находится флаг Считать последовательные разделители одним - в случае последовательно идущих символов-разделителей они будут восприниматься за один. Такое бывает, например, когда символом-разделителем выступают несколько пробелов. Пред просмотр текстового файла в виде таблицы внизу (загружаются только первые 10 строк) позволяет убедиться в корректности выбора настроек импорта, даже не запуская его. Если был выбран флаг Формат фиксированной ширины, то появится вкладка, на которой нужно задать границы каждого поля. Создание, как и удаление маркера границы, производится одним щелчком мыши. Двигая маркеры границ столбцов, можно изменять их, если они расставлены неправильно. Данные, распределенные по столбцам, показываются в области предварительного просмотра. На шаге Настройка параметров столбцов нужно настроить следующие параметры столбцов, импортируемых данных, указав соответствующие значения в полях.