Материал: Прототип системы интеллектуального поиска документов на основе онтологии предметной области
- База данных документов - для хранения метаинформации документов, по которым осуществляется информационный поиск.
Описание связей между системами
Связь системы с сервисом морфологии
Текущая реализации системы поддерживает два вида сервисов морфологии:
- локальный, связь с которым осуществляется путем создания программного объекта соответствующего класса, осуществляющего работу со словарем и возвращающего по запросу необходимые формы слов;
- внешний, связь с которым осуществляется по протоколу HTTP [29] путем GET-запросов с необходимыми параметрами, возвращающих необходимые формы слов. Формат данного запроса не регламентируется в Настоящем Документе т.к. данный вид сервиса морфологии не используется в текущей версии системы - поддержка данного вида сервиса морфологии является экспериментальной;
В текущей версии прототипа используется локальный сервис морфологии. Связь системы с сервисом морфологии реализуется на уровне данных соответствующими интерфейсами системы. В результате взаимодействия системы с сервисом морфологии второй возвращает запрашиваемую форму слова или пустое поле в случае отсутствия запрашиваемого слова в словаре, используемом сервисом морфологии.
Связь системы с базой онтологий
Для загрузки в локальную память используемой в процессе обработки запроса онтологии предметной области используется связь системы с базой онтологий, которая может располагаться:
- локально (на одном сервере с компонентами бизнес-логики системы);
- отдельно (на отдельном сервере, связь с которым осуществляется по сети);
Выбор метода расположения базы онтологий определяется при развертывании системы. Текущая версия системы разворачивается с использованием отдельного сервера для размещения базы онтологий.
Описание регламента связи
В текущей версии системы связь системы с базой онтологий, расположенной на отдельном сервере реализуется при помощи протокола HTTP [29] путем GET-запросов с необходимыми параметрами:
- Протокол загрузки онтологии: HTTP;
- Адрес сервера базы онтологий (пример: 192.168.0.1);
- Порт доступа к базе онтологий (пример: 80);
- Каталог онтологии (пример /ontology/law/);
- Имя (Идентификатор) файла онтологии в нижнем регистре (пример: ontology123. owl).
Пример строки запроса для загрузки онтологии:
#"877770.files/image004.gif">
Рисунок 4 - Диаграмма варианта размещения компонентов системы
и используемых систем на трех серверах
Применяемые для обеспечения функционирования системы сервера:
- Web-сервер. Данный сервер предназначается для размещения:
- компонентов графического web-интерфейса пользователей системы;
- API-интерфейсов, предназначенных для взаимодействия системы со смежными системами.
- Сервер приложений. Данный сервер предназначается для размещения:
- компонентов бизнес-логики подсистемы поиска системы;
- компонентов уровня данных системы;
- системы полнотекстового поиска.
- Сервер баз данных. Данный сервер предназначается для размещения:
- базы данных документов;
- базы онтологий;
- сервиса морфологии;
- базы индексов документов;
- базы индексируемых образов документов.
Для обеспечения взаимодействия между компонентами системы, расположенными на разных серверах, данные сервера объединены в локальную сеть.
Пользователи системы имеют доступ к web-интерфейсу посредством web-браузера.
Сотрудники обслуживающего персонала системы имеют доступ к web-интерфейсу системы и базе данных, для редактирования баз данных документов и онтологий.
5.3 Описание информационного обеспечения системы
Состав информационного обеспечения
В состав информационного обеспечения системы входит:
- База данных документов. Предназначается для хранения метаинформации документов, по которым осуществляется поиск, онтологий и списки результатов поиска. Принципы организации, структура и содержание данной базы регламентируются в Настоящем Документе;
- База онтологий предметных областей. Предназначается для хранения файлов онтологий, используемых в процессе онтологической обработки поискового запроса. Принципы организации, структура и содержание данной базы регламентируются в Настоящем Документе;
- База индексов документов системы полнотекстового поиска. Предназначается для хранения составленных системой полнотекстового поиска для ускорения процесса обработки запроса результатов индексирования документов, по которым осуществляется поиск. Принципы организации, структура и содержание данной базы не регламентируются в Настоящем Документе. Данные аспекты регламентируются в документации к системе полнотекстового поиска [35];
- База индексируемых образов документов. Предназначается для хранения образов документов, предназначенных для индексирования системой полнотекстового поиска для ускорения процесса обработки запроса;
- Словари сервиса морфологии. Предназначается для обеспечения функционирования сервиса морфологии. Принципы организации, структура и содержание данной базы не регламентируются Настоящем документе. Формат данных словарей регламентируется в документации к системе морфологии [17];
- Файлы конфигурации системы. Предназначаются для хранения настроек, обеспечивающих правильное функционирование системы. Включают в себя:
- Файл конфигурации системы полнотекстового поиска. Принципы организации, структура и содержание данного файла частично регламентируются в Настоящем Документе. Наиболее подробно аспекты регламентируются в документации к системе полнотекстового поиска [35];
- Файл конфигурации системы логирования процесса обработки поискового запроса. Принципы организации, структура и содержание данного файла частично регламентируются в Настоящем Документе;
- Файлы конфигурации СУБД. Принципы организации, структура и содержание данного файла не регламентируются в Настоящем документе. Данные аспекты регламентируются в документации к СУБД [18];
- Файл конфигурации подсистемы поиска. Принципы организации, структура и содержание данного файла регламентируются в Настоящем Документе.
- Лог-файлы работы системы. Предназначаются для хранения записей о результатах процесса обработки поискового запроса. Принципы организации, структура и содержание данных файлов регламентируются в Настоящем документе.
Организация информационного обеспечения
Принципы организации информационного обеспечения
Принципы организации соответствующих составляющих информационного обеспечения системы регламентируются в п.3.3.4 "Организация внутримашинной информационной базы" и п.3.3.5 "Организация внемашинной информационной базы" Настоящего Документа.
Обоснование выбора носителей данных
В качестве носителей данных для всех информационных составляющих системы используются жесткие диски серверов, обеспечивающих размещение и функционирование соответствующих функциональных компонентов системы.
Принципы и методы контроля в маршрутах обработки данных
Данные характеристики системы не регламентируются в Настоящем Документе. Контроль корректности и целостности передаваемых данных осуществляется методами используемых системами протоколов передачи данных
Описание решений, обеспечивающих информационную совместимость АС с другими системами
База данных документов
Обеспечение информационной совместимости базы данных документов АС с другими системами в задаче организации данной базы достигается за счет:
- использования СУБД MySQL, распространяемая под GNU General Public License;
- использования стандарта ANSI SQL-92, регламентированного в [12];
База онтологий
Обеспечение информационной совместимости базы онтологий АС с другими системами в задаче организации данной базы достигается за счет:
- использования протокола HTTP для получения доступа к базе онтологий, регламентированного в [29];
- использования языка описания онтологий OWL (Ontology Web Language), для описания онтологий предметных областей, хранящихся с базе онтологий. Данный язык описания онтологий регламентирован в [19];
База индексов документов системы полнотекстового поиска
Обеспечение информационной совместимости базы индексов документов системы полнотекстового поиска АС с другими системами в задаче организации данной базы достигается за счет:
- использования протокола SSH (SCP) для получения доступа к базе индексов документом системы полнотекстового поиска. Данный протокол регламентирован в [15].
База индексируемых образов документов
Обеспечение информационной совместимости базы индексируемых образов документов АС с другими системами в задаче организации данной базы достигается за счет:
- использования протокола HTTP для получения доступа к базе индексируемых образов документов, регламентированного в [29];
- использования формата HTML для хранения индексируемых образов документов, регламентированного в [14];
Словари сервиса морфологии
Обеспечение информационной совместимости используемых в АС словарей сервисам морфологии с другими системами в задаче организации данной базы достигается за счет:
- в случае использования внешнего сервиса морфологии - за счет использования протокола HTTP для получения доступа к сервису морфологии, регламентированного в [17];
Файлы конфигурации системы
Обеспечение информационной совместимости конфигурационных файлов АС с другими системами в задаче организации данных файлов не ставится в задачи реализации АС, Т.о. данный вид совместимости не обеспечивается (поддерживается) текущей версией системы.
Лог-файлы работы системы
Обеспечение информационной совместимости лог-файлов работы АС с другими системами в задаче организации данных файлов достигается за счет:
- использования протокола SSH (SCP) для доступа к данным файлам, регламентированного в [15];
- использования текстового формата (Plain Text) для хранения содержимого данных файлов в кодировке UTF-8;
Организация сбора и передачи информации
Источники и носители информации
В качестве носителей информации используются жесткие диски сервером, обеспечивающих функционирование программных компонентов системы.
Источником информации для базы данных документов системы является разработанный загрузчик метаинформации документов (OntoLoader), предназначенный для:
- загрузки в базу данных новых коллекций документов (их метаинформации);
- редактирования коллекций базы данных документов;
- редактирования рубрик и ключевых слов документов;
Принципы работы данного программного обеспечения не регламентируются в Настоящем Документе.
Общие требования к организации сбора, передачи, контроля и корректировки информации
Передача информации между подсистемой поиска и смежными/используемыми системами производится посредством протоколов передачи данных, предоставляемых используемыми системами и регламентируются в описании связей систем Настоящего Документа.
Организация внутримашинной информационной базы
База данных документов
Принципы построения внутримашинной информационной базы
База данных документов системы предназначена для:
- хранения информации о документах, используемых в процессе поиска и файлов, прикрепленных к этим документам;
- хранения метаинформации документов, используемых в процессе поиска;
- хранения схем классификаторов документов;
- хранения истории поисковых запросов и сформированных расширенных поисковых запросов;
- хранения информации о предметных областях, рубриках, ключевых словах и соответствующих им онтологиях
Данная база данных реализована с использованием СУБД MySQL. Доступ к базе данных осуществляется по протоколу СУБД, регламентированному в соответствующей документации. В качестве языка управления данными используется язык SQL стандарта ANSI SQL-92.
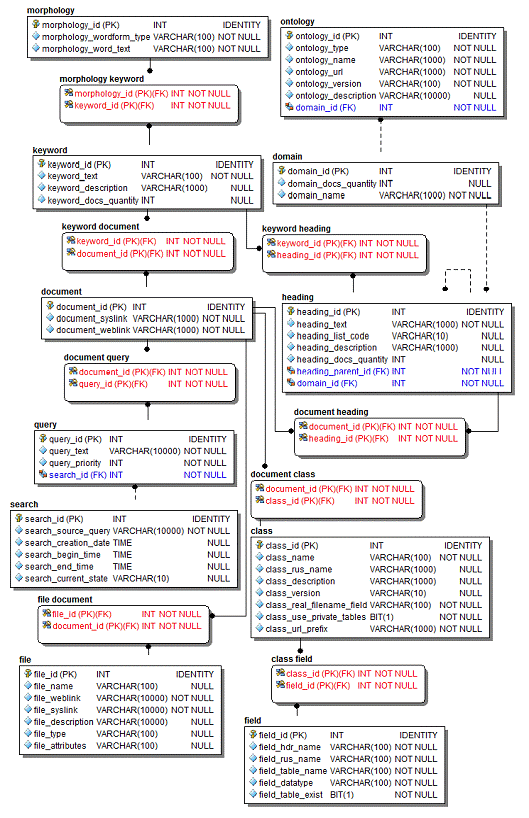
Данная база одержит следующие таблицы:
- Документ (doc). Таблица предназначена
для хранения информации о документе системы, используемом в процессах
индексации и поиска. Содержит следующие поля:
Таблица 5 - Поля таблицы "doc"
Имя поля в
таблице
Значение
Описание
document_id
Код документа
Уникальный
идентификатор документа в системе. Суррогатный ключ.
document_syslink
Системная
ссылка
Указатель на
поисковой образ документа, используемый для индексации документа системой
полнотекстового поиска. Представляет собой ссылку на локальный файл.
document_weblink
Web-ссылка
Указатель на
документ, используемый для отображения в списке результатов поиска.
Представляет собой ссылку на web-страницу с документом.
- Класс документа (class). Таблица предназначена
для описания классов документов. Содержит следующие поля:
Таблица 6 - Поля таблицы "class"
Имя поля в
таблице
Значение
Описание
class_id
Код класса
Уникальный
идентификатор класса документа в системе. Суррогатный ключ.
class_name
Имя класса
Уникальное имя
класса в системе. Записывается латинскими символами. Альтернативный ключ.
class_description
Описание класса
Текстовое
описание класса.
class_version
Версия класса
Номер версии
конфигурации класса
class_real_filename_field
Имя поля
реального названия файла
Имя поля в
метаинформации документа, содержащего реальное имя файла
class_use_private_tables
Использование
собственных таблиц
Решение
использования собственных таблиц для записи полей документов данного класса
либо использовать общие таблицы полей, встречающихся в разных классах
class_url_prefix
URL-префикс класса
URL-адрес,
указывающий на расположение документов класса
- Поле документа (field). Таблица предназначена
для хранения значений полей документов. Содержит следующие поля:
Таблица 7 - Поля таблицы "field"
Имя поля в
таблице
Значение
Описание
field_id
Код поля
Уникальный
идентификатор поля в системе. Суррогатный ключ.
field_hdr_name
Имя поля в HDR
Имя данного
поля в HDR-файлах документов
field_rus_name
Имя поля на
русском
Имя данного
поля на русском языке для отображения в карточке документа.
field_table_name
Имя таблицы
поля
Имя таблицы в
базе данных, хранящей значения данного поля для документов
field_datatype
Тип данных поля
Тип данных
метаинформации документа, содержащейся в данном поле (таблице поля)
field_table_exist
Существование
таблицы
Указание на
существование созданной таблицы данного поля в базе данных
- Рубрика документа (heading). Таблица предназначена
для хранения списка рубрик документов. Содержит следующие поля:
Таблица 8 - Поля таблицы "heading"
Имя поля в
таблице
Значение
Описание
heading_id
Код рубрики
Уникальный
идентификатор рубрики в системе. Суррогатный ключ.
heading_text
Текст рубрики
Текстовое
название рубрики
heading_list_code
Код рубрики в
списке
Номер рубрики указываемый
в списке (дереве) рубрикатора
heading_description
Описание
рубрики
Текстовое
описание рубрики
heading_docs_quantity
Количество
документов рубрики
Количество
документов в системе, соответствующих данной рубрике
heading_parent_id
Код родительской
рубрики
Указатель на
родительскую рубрику в дереве рубрикатора
domain_id
Код предметной
области
Указатель на
предметную область, к которой принадлежит данная рубрика
- Ключевое слово (keyword). Таблица предназначена
для хранения ключевых слов каждой из рубрик. Содержит следующие поля:
Таблица 9 - Поля таблицы "keyword"
Имя поля в
таблице
Значение
Описание
keyword_id
Код ключевого
слова
Уникальный
идентификатор ключевого слова в системе. Суррогатный ключ.
keyword_text
Текст ключевого
слова
Текстовое
значение ключевого слова в нормальной форме (им. п., ед. ч.)
keyword_description
Описание
ключевого слова
Текстовое
описание ключевого слова
keyword_docs_quantity
Количество
документов ключевого слова
Количество
документов в системе, соответствующих данному ключевому слову
- Морфология ключевого слова (morphology). Таблица предназначена
для хранения морфологических форм ключевых слов с целью ускорения получения
доступа к необходимым формам нужного ключевого слова. Содержит следующие поля:
Таблица 10 - Поля таблицы "morphology"
Имя поля в
таблице
Значение
Описание
morphology_id
Код
морфологической формы (словоформы)
Уникальный
идентификатор морфологической формы в системе. Суррогатный ключ
morphology_wordform_type
Тип словоформы
Описание вида
словоформы (падеж, число)
morphology_word_text
Текст
словоформы
Текстовое
представление словоформы
- Онтология (ontology). Таблица предназначена
для хранения метаинформации имеющихся в базе системы онтологий. Содержит
следующие поля:
Таблица 11 - Поля таблицы "ontology"
Имя поля в
таблице
Значение
Описание
ontology_id
Код онтологии
Уникальный
идентификатор онтологии в системе. Суррогатный ключ
ontology_type
Тип онтологии
Описание типа
онтологии (в текущей версии системы - "Онтология предметной области")
ontology_name
Название
онтологии
Текстовое
название онтологии
ontology_url
URL онтологии
Адрес OWL-файла онтологии в базе онтологий
системы
ontology_version
Версия онтлогии
Номер версии
онтологии
ontology_description
Описание
онтологии
Текстовое описание
онтологии Код предметной
области
Указатель на
предметную область онтологии
- Предметная область (domain). Таблица предназначена
для хранения списка предметных областей. Содержит следующие поля:
Таблица 12 - Поля таблицы "domain"
Имя поля в
таблице
Значение
Описание
domain_id
Код предметной
области
Уникальный
идентификатор предметной области в системе. Суррогатный ключ
domain_docs_quantity
Количество
документов предметной области
Количество
документов в системе, соответствующих данной предметной области
domain_name
Имя предметной
области
Полное
текстовое название предметной области
- Поиск (search). Таблица предназначена
для хранения списка пользовательских поисковых запросов. Содержит следующие
поля:
Таблица 13 - Поля таблицы "search"
Имя поля в
таблице
Значение
Описание
search_id
Код поиска
Уникальный
идентификатор экземпляра поиска в системе. Суррогатный ключ
search_source_query
Исходный запрос
Текст исходного
поискового запроса
search_creation_date
Дата создания
Дата создания
поискового запроса
search_begin_time
Время начала
Время начала
выполнения обработки запроса
search_end_time
Время
завершения
Время
завершения выполнения обработки запроса
search_current_state
Текущее
состояние
Текущие
состояние процесса выполнения обработки запроса
- Файл (file). Таблица предназначена
для хранения списка прикрепленных к документам в системе файлов: изображения,
таблицы и т.д. Содержит следующие поля:
Таблица 14 - Поля таблицы "file"
Имя поля в
таблице
Значение
Описание
file_id
Код файла
Уникальный
идентификатор файла в системе. Суррогатный ключ
file_name
Имя файла
Текстовое имя
файла
file_weblink
web-ссылка
Сетевая ссылка
на файл
file_syslink
Системная
ссылка
Системная
ссылка на файл
file_description
Описание файла
Текстовое описание
файла
file_type
Тип файла
Текстовое
описание типа файла
file_attributes
Атрибуты файла
Текстовое
описание атрибутов файла
- Поисковой запрос (query). Таблица предназначена
для хранения сформированных в процессе обработки пользовательского поискового
запроса новых поисковых запросов. Содержит следующие поля:
Таблица 15 - Поля таблицы "query"
Имя поля в
таблице
Значение
Описание
query_id
Код запроса
Уникальный
идентификатор запроса в системе. Суррогатный ключ
query_text
Текст запроса
Текст поискового
запроса
query_priority
Приоритет
запроса
Приоритет
поискового запроса.
search_id
Код поиска
Указатель на
экземпляр объекта поиска, вызвавший формирование данного запроса
Логическая модель базы данных документов приведена рис.5.
Данная структура представляет собой модель данных, основанную на сущностях
предметной области и связях между ними.
Рисунок 5 - Логическая модель данных базы данных документов
системы
Реляционная схема базы данных документов системы приведена на
рис. 6.
Рисунок 6 - Реляционная схема базы данных документов системы
База данных онтологий предметных областей системы
предназначается для:
- хранения и учета данных всех онтологий
системы;
- предоставления доступа к OWL-файлам онтологий.
Данная база представляет собой иерархическую структура
каталогов, каждый из которых относится к определенной предметной области и
хранит соответствующие OWL-файлы онтологий, доступ к которым осуществляется
по протоколу HTTP [29].
База индексов документов системы формируется системой
полнотекстового поиска в процессе индексирования базы индексируемых образов
(массива) документов. В дальнейшем построенные индексы используются системой
полнотекстового поиска в процессе обработки поискового запроса.
База индексов документов системы представляет собой каталог
файлов, формат которых не регламентируется в Настоящем Документе. Формат
индексов документов системы регламентируется в документации к системе
полнотекстового поиска [35].
База индексируемых образов документов системы представляет
собой массив текстовых (или иных, содержащих текст форматов) файлов в кодировке
UTF-8, содержимое которых
индексируется системой полнотекстового поиска для построения базы индексов
документов системы.
База индексируемых образов документов системы представляет
собой иерархическое дерево каталогов, в котором каждый конечный каталог (ветка
дерева) представляет собой отдельную коллекцию индексируемых образов
документов.
База словарей сервиса морфологии не регламентируется в
Настоящем Документе в силу отсутствия необходимости прямого взаимодействия
подсистемы поиска с базой данных словарей сервиса морфологии. Формат данной
базы регламентируется в документации к программному обеспечению, реализующему
функции сервиса морфологии [17].
База файлов конфигурации системы представляет собой
совокупность текстовых конфигурационных файлов в кодировке UTF-8, используемых
подсистемой поиска и вспомогательными системами для обеспечения корректного
функционирования системы. Конфигурации, входящие в состав базы файлов
конфигурации системы:
- Конфигурация системы полнотекстового
поиска. Используется системой полнотекстового поиска для определения параметров
индексирования и поиска документов. Конфигурация системы полнотекстового поиска
описывается в POSIX-совместимом формате и регламентируется в [16]. Пример
конфигурационного файла приведен в приложении к Настоящему Документу.
- Конфигурация подсистемы поиска.
Используется подсистемой поиска для определения используемой системы
полнотекстового поиска, базы данных документов, сервиса морфологии и параметров
подключения к ним. Конфигурация подсистемы поиска описывается в POSIX-совместимом формате и
регламентируется Настоящем Документе. Данная конфигурация включает в себя:
Таблица 16 - Состав конфигурации подсистемы поиска
Имя поля
Описание
Конфигурация
модуля морфологической обработки поискового запроса
morpho_type
Тип
используемой системы морфологии
morpho_server
Адрес сервера
сервиса морфологии
morpho_port
Порт сервиса
морфологии на сервере
morpho_min
Минимальное
число обрабатываемых элементов пользовательского поискового запроса,
необходимое для инициализации процесса морфологической обработки запроса.
morpho_max
Максимальное
число обрабатываемых элементов пользовательского поискового запроса
Конфигурации
модуля онтологической обработки поискового запроса
onto_type
Тип
используемой базы онтологий системы
onto_server
Адрес сервера
базы онтологий системы
onto_port
Порт базы
онтологий системы на сервере
onto_max
Максимальное
число используемых в процессе онтологической обработки поискового запроса
онтологий
Конфигурация
модуля поиска документов
search_type
Тип
используемой системы полнотекстового поиска
search_server
Адрес сервера
системы полнотекстового поиска системы
search_port
Порт системы
полнотекстового поиска системы
search_index
База индексов
документов, используемая для поиска документов
search_sort
Метод
сортировки результатов поиска
search_max
Максимальное число
загружаемых результатов поиска
search_param
Дополнительные
параметры использования системы полнотекстового поиска
Конфигурация
модуля формирования дополнительных (расширенных) поисковых запросов
query_min
Минимальное
число элементов запроса
query_max
Максимальное
число элементов запроса
Конфигурация
модуля документов системы
db_type
Тип
используемой базы данных документов системы
db_server
Адрес сервера
базы данных документов системы
db_name
Имя схемы базы
данных документов системы
db_user
Имя
пользователя при подключении к базе данных документов системы
db_pass
Пароль
аутентификации при подключении к базе данных документов системы
db_res_type
Тим
формируемого списка результатов поиска
Пример конфигурационного файла подсистемы поиска приводится в
приложении к Настоящему Документу.
- Конфигурация системы логирования процесса
обработки поискового запроса. Используется системой логирования процесса
обработки поискового запроса для определения параметров ведения лог-журналов
процессов обработки поисковых запросов. Конфигурация системы логирования
процесса обработки поискового запроса регламентируется в документации к системе
логирования процесса обработки поискового запроса [38]. Пример
конфигурационного файла приведен в приложении к Настоящему Документу;
- Конфигурация СУБД. Используется СУБД для
определения параметров функционирования базы данных документов системы.
Конфигурация СУБД описывается в POSIX-совместимом формате [16] и регламентируется в
[18]. Пример конфигурационного файла приведен в приложении к Настоящему
Документу.
База файлов конфигурации системы представляет собой
иерархически организованную структуру каталогов, каждый из которых
предназначается для хранения определенного класса конфигурационных файлов.
База лог-файлов работы системы представляет собой коллекцию
текстовых файлов в кодировке UTF-8, используемых для ведения лог-журнала (протокола)
работы подсистемы поиска. Синтаксис лог-файла работы системы регламентируется в
документации к системе логирования процесса обработки поискового запроса [38].
База лог-файлов работы системы представляет собой
иерархически организованную структуру каталогов, каждый из которых
предназначается для хранения лог-файлов работы системы за определенный период
времени (определяется администратором системы).
В качестве внемашинной информационной базы выступает:
- Рабочая документация пользователя системы;
- Рабочая документация администратора
системы;
- Рабочая документация сотрудника
обслуживающего персонала системы;
- Рабочая документация разработчика системы;
Данное информационное обеспечение представляет собой
коллекцию соответствующих документов в электронном (Microsoft Office Word Document 2003 (*. doc)) и распечатанном
бумажном на листах А4 форматах, хранящуюся у администратора системы или
ответственного лица.
При внесении дополнений и изменений в исходные коды или
конфигурации системы в целях поддержания актуального состояния документации
системы необходимо своевременно отражать внесенные дополнения и изменения в
вышеописанных документах.
Для контроля качества и актуальности документации системы
назначается ответственное лицо. В настоящий момент таковым является разработчик
системы.
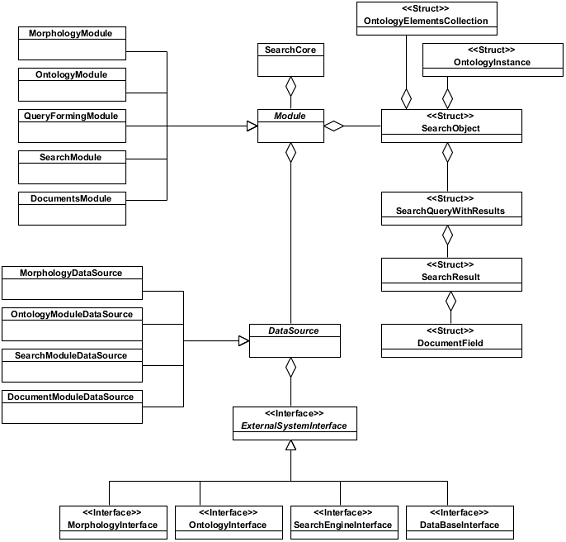
Структура программного обеспечения подсистемы реализации
интеллектуального поиска разработана с т. з. модульного и
объектно-ориентированного подходов. Диаграмма классов подсистемы реализации
интеллектуального поиска приводится на рис. 7.
Рисунок 7 - Диаграмма классов подсистемы реализации
интеллектуального поиска
Данная диаграмма включает в следующие классы:
Классы уровня бизнес-логики интеллектуального поиска:
- Класс "SearchCore". Представляет
собой монолитную реализацию Поискового ядра;
- Класс "Module". Представляет
собой абстрактный образ функционального модуля системы. Является абстрактным и
используется только на унификации модулей подсистемы;
- Класс "MorphologyModule". Представляет
собой монолитную реализацию Модуля морфологии;
- Класс "OntologyModule". Представляет
собой монолитную реализацию Модуля онтологии;
- Класс "QueryFormingModule". Представляет
собой монолитную реализацию Модуля формирования запросов;
- Класс "SearchModule". Представляет
собой монолитную реализацию Модуля поиска;
- Класс "DocumentsModule". Представляет
собой монолитную реализацию Модуля документов;
Классы уровня данных:
- Класс "DataSource". Представляет
собой абстрактный образ источника данных для конкретного модуля системы.
Является абстрактным и используется только для унификации источников данных
подсистемы;
- Класс "MorphologyModuleDataSource". Представляет
собой реализацию источника данных для реализации морфологических операций;
- Класс "OntologyModuleDataSource". Представляет
собой монолитную реализацию источника данных для реализации операций с
онтологиями;
- Класс "SearchModuleDataSource". Представляет
собой реализацию источника данных для реализации поисковых операций;
- Класс "DocumentModuleDataSource". Представляет
собой монолитную реализацию источника данных для операций с документами;
- Класс "ExternalSystemInterface". Представляет
собой абстрактный образ интерфейса к внешней системе, используемой в процессе
обработки поискового запроса. Является абстрактным и используется только для
унификации интерфейсов к внешним системам, используемым подсистемой реализации
интеллектуального поиска;
- Класс "MorphologyModule". Представляет
собой интерфейс доступа к сервису морфологии. В текущей версии реализации
прототипа системы интеллектуального поиска не используется в силу упрощения
процесса морфологической обработки запроса и использования внутренней
программной подсистемы морфологии;
- Класс "OntologyInterface". Представляет
собой интерфейс доступа к базе онтологий;
- Класс "SearchEngineInterface". Представляет
собой интерфейс доступа к системе полнотекстового поиска;
- Класс "DataBaseInterface". Представляет
собой интерфейс доступа к СУБД;
Структуры данных, приведенные на диаграмме классов системы:
- Структура "SearchObject". Представляет
собой временное хранилище всех данных, связанных с пользовательским поисковым
запросом;
- Структура "SearchQueryWithResults". Представляет
собой временное хранилище поискового (исходного или сгенерированного системой в
процессе генерации дополнительных (расширенных)) запроса и списка результатов,
найденных при выполнении поиска по этому запросу;
- Структура "SearchResult". Представляет
собой временное хранилище данных документа-результата поиска;
- Структура "DocumentField". Представляет
собой временное хранилище единицы метаинформации документа-результата поиска.
Функции программного обеспечения регламентируются в п.3.4.3
"Методы и средства разработки программного обеспечения", п.3.4.4
"Операционная система", п.3.4.5 "Средства, расширяющие
возможности операционной системы" Настоящего Документа.
В процессе разработки системы использовались:
- Язык программирования Java [26] - функциональные
компоненты системы реализации интеллектуального поиска;
- Технология JavaServer Pages (JSP) [27] - компоненты
графического интерфейса системы реализации интеллектуального поиска;
- Структурированный язык запросов SQL [28] - выполнение
запросов к базе данных документов системы;
- Язык разметки гипертекста HTML [14] - компоненты
графического интерфейса системы реализации интеллектуального поиска;
- Язык скриптов JavaScript [30] - элементы
контроллера системы реализации интеллектуального поиска;
- Унифицированный язык моделирования UML [31] - описание и документирование
архитектуры и методов функционирования системы;
- Visual Paradigm for UML Enterprise Edition 7.2 [32] - описание и
документирование архитектуры и методов функционирования системы;
- Embarcadero ER/Studio 8.0.3 [33] -
проектирование модели данных и генерация ее реляционной схемы;
- NetBeans IDE 7.0.1 [34] - реализация
функциональных компонентов системы;
- Log4j [38] - система
логирования сообщений в Java;
- Sphinx Java API [36] - API-интерфейсы системы
полнотекстового поиска для Java;
- MySQL Java Connector [37] - API-интерфейсы СУБД MySQL для Java;
- OWL API [19] - API интерфейсы OWL для Java;
- Morphology API [17] - API интерфейсы морфологии
для Java.
Операционной системой, используемой для обеспечения
выполнения всех функций системы является Debian GNU/Linux 6.0 Squeeze i386. Данный выбор
обусловлен:
- высокой надежностью данной операционной
системы;
- свободным распространением данной
операционной системы в соответствии с лицензией GNU GPL;
- открытыми стандартами данной операционной
системы;
Установка и конфигурированное данной операционной системы
должна производиться в соответствии с:
- пользовательской документацией Debian GNU/Linux [25];
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документу;
Кроссплатформенный свободно распространяемый Web-сервер. В разработанной
системе применяется с целью:
- предоставления к графическому Web-интерфейсу системы;
- предоставления доступа к API-интерфейсам системы;
- предоставления доступа к базе онтологий
предметных областей системы;
- предоставления доступа к компонентам
бизнес-логики подсистемы реализации интеллектуального поиска документов.
Установка и конфигурирование Web-сервера Apache производится в
соответствии с:
- пользовательской документацией к Web-серверу Apache [21];
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документы;
Данное программное обеспечение должно предоставлять доступ к вышеописанным
составляющим системы по протоколу HTTP на порт 80 стандартным GET-запросом,
регламентируемым в документации к использующей данное программное обеспечение
системе.
Набор программ, предоставляющих шифрование сеансов связи по
компьютерным сетям с использованием протокола SSH. В разработанной системе
применяется с целью:
- предоставления доступа к операционной
системе, под управлением которой работает система. Данный доступ реализуется
для обеспечения возможности администрирования системы;
- предоставления доступа к базе
конфигураций. Данный доступ реализуется для обеспечения правильного
конфигурирования всех составляющих системы и их функционирования в актуальном
(установленном/корректном) режиме;
- предоставления доступа к базе лог-файлов
системы. Данные доступ реализуется для обеспечения протоколирования процессов
обработки поисковых запросов;
- предоставления доступа к базе поисковых
образов документов системы, по которым в процессе обработки поискового запроса
осуществляется поиск. Данный доступ реализуется для обеспечения возможности
индексирования документов системой полнотекстового поиска;
- предоставления доступа к базе индексов
документов системы, по которым в процессе обработки поискового запроса
осуществляется поиск. Данный доступ реализуется для обеспечения поиска
документов по представленному поисковому запросу;
Установка и конфигурирование OpenSSH производится в
соответствии с:
- пользовательской документацией к OpenSSH [22];
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документу;
Данное программное обеспечение должно предоставлять доступ к
использующей его системе про протоколу SSH на порт 22. Особенности
использования данного программного обеспечения какой-либо системой
(подсистемой) регламентируются в документации к этой системе (подсистеме).
Кроссплатформенная свободно распространяемая система
управления базами данных.
В разработанной системе применяется с целью:
- предоставления доступа к базе данных
документов системы, по которым в процессе обработки поискового запроса
производится поиск. Данные доступ реализуется для обеспечения возможности
чтения метаинформации документов
Установка и конфигурирование системы управления базами данных
MySQL производится в
соответствии с:
- пользовательской документацией к СУБД MySQL;
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документу;
Данное программное обеспечение должно предоставлять доступ к
использующей его системе (подсистеме) по внутреннему протоколу MySQL на указанный в
конфигурации системы используемый для этого порт и производить управление базой
данных, к которой производится предоставление доступа. Особенности
использования данного программного обеспечения какой либо системой
(подсистемой) регламентируются в документации к этой системе (подсистеме).
Контейнер сервлетов, реализующий спецификацию сервлетов и
спецификацию JavaServer Pages (JSP). В разработанной системе применяется с целью:
- обеспечения функцонирования компонентов
бизнес-логики подсистемы реализации интеллектуального поиска;
- предоставления доступа к компонентам
бизнес-логики подсистемы реализации интеллектуального поиска.
Установка и конфигурирование Apache Tomcat производится в
соответствии с:
- пользовательской документацией к Apache Tomcat [23];
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документу;
Особенности использования данного программного обеспечения
регламентируются в документации в соответствии с параметрами функционирования
системы.
Виртуальная машина Java, основная часть исполняющей системы Java - Java Runtime Environment (JRE). В разработанной
системе применяется с целью:
- обеспечения функционирования компонентов
системы, реализованных с использованием языка программирования Java (подсистема реализации
интеллектуального поиска).
Установка и конфигурирование Java Virtual Machine производится в
соответствии с:
- пользовательской документацией Java Virtual Machine [24];
- параметрами функционирования системы,
приведенными в приложении к Настоящему Документу.
Данное программное обеспечение должно обеспечивать выполнение
JAR-файлов системы.
Алгоритм онтологической обработки поискового запроса
предназначен для осуществления "поиска верхнего уровня" - поиска в
указанной онтологии предметной области указанных типов элементов относительно элементов
поискового запроса и формирования списков найденных элементов.
Данный документ приведен в Техническом Задании на разработку
системы в п. ХХ.
Данный алгоритм производит управление работой модуля
онтологической обработки поискового запроса.
Условиями функционирования настоящего алгоритма являются:
- наличие списка нормализованных элементов
исходного пользовательского поискового запроса, включающегося как минимум один
элемент;
- наличие списка онтологий предметных
областей, включающегося указатель как минимум на одну онтологию предметной
области;
- наличие в базе онтологий файлов онтологий,
указанных в списке онтологий, используемых для онтологической обработки
поискового запроса;
- наличие доступа к базе онтологий;
- наличие списка искомых типов элементов
онтологии предметной области, включающего как минимум один тип;
Требования к условиям функционирования настоящего алгоритма в
зависимости от наличия входных данных регламентируются в п.3.5.1.1.4 Настоящего
Документа.
Общие требования к входным данным алгоритма:
- Список нормализованных элементов исходного
поискового запроса. Данный список должен представлять собой массив строк,
каждая из которых содержит нормализованную форму соответствующего элемента
исходного поискового запроса;
- Список онтологий предметных областей.
Данный список должен представлять собой массив строк, каждая из которых
содержит уникальный идентификатор (в системе) онтологии предметной области,
которые необходимо использовать в процессе онтологической обработки поискового
запроса;
- Список искомых типов элементов онтологии
предметной области. Данный список должен представлять собой массив строк,
каждая из которых содержит уникальный идентификатор (в системе) типа искомых в
онтологии предметной области элементов по отношению к каждому значению из
списка нормализованных элементов исходного поискового запроса;
Перечисленные данные должны входить в объект типа SearchObject и регламентируется в
п.5.2.1.2 "Используемая информация" Настоящего Документа.
Общие требования к выходным данным алгоритма:
) Выходные данные должны представлять собой массив
списков найденных в каждой онтологии предметной области соответствующих
нормализованным элементам исходного поискового запроса указанные типы связей.
Каждый список такого вида должен включать:
- уникальный (в системе) идентификатор
онтологии предметной области, в которой осуществлялся поиск элементов;
- уникальный (в системе) идентификатор типа
искомых в онтологии предметной области элементов, указывающий на тип найденных
элементов, содержащихся в данном списке;
- соответствующий нормализованный элемент
исходного поискового запроса, соответствующие указанным типом связи которому
найденные в онтологии предметной области элементы расположены в данном списке;
- порядковый номер соответствующего
нормализованного элемента исходного поискового запроса в строке исходного
поискового запроса;
- массив строк, содержащий найденные в
указанной онтологии предметной области элементы, указанным типом связи
соответствующие указанному нормализованному элементу исходного поискового
запроса.
Требования к используемым (входным) данным регламентируются в
п.3.5.1.1.5 "Общие требования к входным и выходным данным" Настоящего
Документа. Входные данные должны представлять собой объект класса SearchObject, диаграмма которого приведена
на рис.8:
Рисунок 8 - Диаграмма класса SearchObject
Атрибуты объекта класса SearchObject:
- _searchId - уникальный идентификатор процесса
поиска в системе;
- _query - исходный поисковой
запрос;
- _norm_query - нормализованный поисковой запрос;
- _words_forms - формы слов (элементов) исходного поискового
запроса;
- _searchQueries - массив поисковых
запросов (исходный и сгенерированные);
- _searchQueriesQuantity - количество поисковых
запросов;
- _ontoElemQuantity - количество элементов в
массиве сформированных в результате онтологической обработки поискового запроса
объектов класса OntologyElementsCollection;
- _queryElements - список нормализованных
элементов исходного поискового запроса;
- _usedOntologies - список используемых в
процессе онтологической обработки запроса онтологий;
- _ontoTypes - список искомых в процессе
онтологической обработки запроса элементов онтологии предметной области;
- _ontoElements - массив сформированных в результате
онтологической обработки поискового запроса объектов класса OntologyElementsCollection.
Методы объекта класса SearchObject:
- getResources () - функция выделения
памяти для атрибутов объекта класса SearchObject;
- clearResources () - функция
освобождения (очистки) памяти, используемой атрибутами объекта класса SearchObject.
Массивы информации, сформированные из входных сообщений
регламентируются в п.3.5.1.3.1 "Массивы информации и (или) сигналы,
формируемые для выдачи выходных сообщений" Настоящего Документа по причине
упрощения схемы реализации алгоритма с генерацией выходных массивов информации
"на лету" без генерации "промежуточных"
("временных") массивов данных.
Результаты решения регламентируются в п.3.5.1.1.5 "Общие
требования к входным и выходным сигналам", п.3.5.1.3.1 "Массивы
информации и (или) сигналы, формируемые для выдачи выходных сообщений",
п.3.5.1.3.2 "Массивы информации, сохраняемой для решения данной и других задач
АС" Настоящего Документа.
Массивы информации, формируемые для выдачи выходных сообщений
регламентируются в п.3.5.1.1.5 "Общение требования к входным и выходным
данным" Настоящего Документа. Данный массив информация должен представлять
собой массив объектов класса OntologyElementsCollection, диаграмма которого
приведена на рис.9.
Рисунок 9 - Диаграмма класса OntologyElementsCollection
Атрибуты объекта класса OntologyElementsCollection:
- _ontology - идентификатор онтологии;
- _type - тип искомых элементов (связей);
- _inQueryNumber - порядковый номер
элемента исходного запроса;
- _sourceElement - нормализованный
элемент исходного запроса;
- _elements - список найденных в онтологии предметной
области элементов.
Массивом информации, сохраняемым для решения данной или
других задач АС является массив выходных данных, регламентируемый в п.3.5.1.1.5
"Общие требования к входным и выходным данным" и п.3.5.1.3.1
"Массивы информации и (или) сигналы, формируемые для выдачи выходных
сообщений" Настоящего Документа. Данные массивы информации сохраняются во
входном объекте класса SearchObject, регламентированном в п.3.5.1.1.5 "Общие
требования к выходным и выходным данным" и п.3.5.1.2 "Используемая
информация" Настоящего Документа.
Математическое описание данного алгоритма отсутствует и не
регламентируется в Настоящем Документе.
На рис.10 приведена диаграмма последовательности
взаимодействия между собой компонентов системы, реализующих выполнение
алгоритма онтологической обработки поискового запроса и информация,
передаваемая между ними.
Рисунок 10 - Диаграмма последовательности процесса
онтологической обработки запроса
Диаграмма деятельности (высокоуровневой, независимой от
архитектуры системы), реализуемой в алгоритме онтологической обработки запроса
приводится на Рис. 11.
Рисунок 11 - Диаграмма деятельности алгоритма онтологической
обработки запроса (высокоуровневая, независимо от архитектуры системы)
Выполнение алгоритма онтологической обработки запроса представляет
собой циклическое прохождение:
- всех отмеченных для использования в данном
алгоритме онтологий;
- всех нормализованных элементов
пользовательского поискового запроса;
- всех отмеченных типов искомых в онтологии
элементов.
Это реализуется через циклическое прохождение всех трех
списков - тройной вложенный цикл с выполнением запроса к онтологии в каждой
итерации.
Основные шаги выполнения алгоритма с учетом программной
архитектуры системы:
- Передача массива с необходимыми для
выполнения алгоритма онтологической обработки запроса данными модулю
онтологической обработки запроса;
- Передача модулем онтологической обработки
запроса источнику данных названия онтологии предметной области;
- Передача источником данных интерфейсу базы
онтологий названия онтологии;
- Отправка интерфейсом базы онтологий
запроса к базе онтологий, направленного на получение OWL-файла указанной в
запросе онтологии предметной области;
- Получение интерфейсом базы онтологий OWL-файла запрашиваемой
онтологии или кода ошибки в случае ее возникновения (например, отсутствия
запрашиваемого OWL-файла онтологии в базе онтологий системы);
- Получение источником данных OWL-файла онтологии;
- Создание источником данных объекта класса
Онтологии (Регламентируется спецификой используемой библиотеки для работы с
онтологиями) по полученному файлу онтологии;
- Возврат источником данных кода результата
выполнения загрузки и чтения OWL-файла онтологии;
- Передача модулем онтологической обработки
поискового запроса источнику данных:
- нормализованного элемента исходного
поискового запроса;
- идентификатора типа искомых в онтологии
предметной области и связанных с нормализованным элементом исходного поискового
запроса указанным типом связи элементов;
- названия используемой онтологии предметной
области;
- Выполнение источником данных
регламентируемого спецификой используемой API-библиотеки запроса к
объекту онтологии на предмет получения списка найденных элементов;
- Возврат объектом класса Онтологии
источнику данных результатов выполнения запроса;
- Формирование источником данных списка
найденных элементов;
- Возврат источником данных списка найденных
элементов модулю онтологической обработки запроса;
- Запись полученного списка найденных
элементов онтологии в массив выходных данных алгоритма;
- Возврат ядру системы массива результатов
выполнения "поиска первого уровня".
Примечания к алгоритму онтологической обработки запроса:
- шаги 2-14 выполняются для каждой указанной
в списке используемых в процессе онтологической обработки запроса онтологии;
- шаги 9-14 выполняются для каждого
указанного в списке нормализованных элементов исходного поискового запроса
значения;
- шаги 9-14 выполняются для каждого
указанного в списке искомых типов элементов онтологии значения.
Фрагмент кода модуля онтологической обработки поискового
запроса, реализующего данный алгоритм приведен в приложении А.
Достоверность вычислений данного алгоритма определяется на
завершающем этапе обработки пользовательского поискового запроса, исходя из
показателей релевантности и пертинентности результатов поиска. Определение
релевантности найденных документов поисковому запросу определяется при помощи
встроенных средств системы полнотекстового поиска. Определение пертинентности
результатов поиска производится статистически, путем анализа поведения
пользователя - отслеживании открываемых пользователем документов-результатов
поиска, а так же методом экспертных оценок специалистами предметных областей на
этапе оценки результатов работы системы. При открытии пользователем ссылки из
списков документов-результатов поиска производится сопоставление и инкремент
показателя пертинентности открытого документа относительно исходного
пользовательского поискового запроса, независимо от списка результатов -
выполненного по исходному пользовательскому запросу либо по расширенному при
помощи онтологии предметной области.
Для данного алгоритма описание связей между частями и
операциями алгоритма не регламентируется в Настоящем Документе. Область применения заключается в выполнении интеллектуального
поиска документов в информационной системе.
- Предоставление пользователю системы
удобного интерфейса для формирования поискового запроса, выбора онтологий,
используемых для обработки поискового запроса а так же искомых в онтологиях
элементов;
- Выполнение морфологической обработки
пользовательского поискового запроса к системе с целью приведения всех
элементов (слов) запроса к нормальной форме (им. падеж, единственное число);
- Выполнение онтологической обработки
пользовательского поискового запроса - поиск первого уровня. Представляет собой
поиск по онтологии предметной области с целью расширения запроса выбранными
элементами;
- Выполнение поиска по коллекциям
документов;
- Формирование списка результатов поиска;
- Предоставление доступа к
документам-результатам поиска.
Пользователь системы должен:
- уметь работать с web-браузером,
предоставляющим доступ к информационно-поисковой системе;
- иметь возможность сформулировать поисковой
запрос к системе в виде текстовой строки;
- знать название предметной области, в
которой необходимо осуществлять поиск документов;
Дополнительные (не обязательные) знания пользователя:
- URL дополнительных
онтологий, отсутствующих в системе, которые можно использовать в процессе
поиска;
- направления расширения запроса - элементы,
которыми необходимо расширить запрос.
Администратор системы должен:
- иметь навыки работы с операционной
системой Debian Linux;
- иметь представление об устройстве системы;
- уметь пользоваться программным
обеспечением, используемым в системе: Sphinx search engine, OntoLoader, Apache Tomcat, MySQL.
- уметь пользоваться программным
обеспечением и скриптами, предназначенными для установки и конфигурирования
(настройки) системы.
В состав эксплуатационной документации входит:
- Настоящая Рабочая Документация к системе;
- Рабочая документация к программному
обеспечению, обеспечивающему функционирование системы
- Debian Linux 6.0 x86;
- Web-сервер Apache;
- Контейнер сервлетов Tomcat 6.0;
- СУБД MySQL 5.3;
- Sphinx Search Engine 2.0;
- Java EE 1.7;
- Apache Ant 1.8.3;
- Система морфологии УИС "РОССИЯ".
Требования к аппаратному обеспечению сервера системы:
- Процессор с тактовой частотой не менее 800
МГц;
- Жесткий диск объемом не менее 20 Гб;
- Оперативная память объемом не менее 512
Мб;
- Сетевое соединение (сетевая карта),
скоростью подключения к сети не менее 100 Мбит\сек.
Требования к программному обеспечению сервера системы:
- Операционная система Debian Linux x86 версии 6.0;
- Web-сервер Apache версии 2.0;
- Контейнер сервлетов Tomcat версии 6.0;
- Система полнотекстового поиска Spring версии 2.0
- Cервис морфологии УИС
"РОССИЯ";
- СУБД MySQL версии 5.3;
В состав дистрибутива системы входят:
- Программные компоненты системы в формате WAR-файла;
- SQL-скрипт создания базы
данных системы;
- Дистрибутив операционной системы Debian Linux 6.0 x86;
- Дистрибутив web-сервера Apache версии 2.0;
- Дистрибутив контейнера сервлетов Tomcat версии 6.0;
- Дистрибутив СУБД MySQL версии 5.3;
- Дистрибутив Java JDK, Java EE версии 1.7;
- Дистрибутив системы полнотекстового поиска
Sphinx версии 2.0;
- Дистрибутив системы морфологии УИС
"РОССИЯ";
- Дистрибутив утилиты автоматизации Apache Ant версии 1.8.3
- Конфигурационный файл системы
полнотекстового поиска Sphinx;
- Конфигурационный файл СУБД MySQL;
- Конфигурационный файл компонентов системы;
- Настоящая рабочая документация системы;
- Скрипт автоматизированной установки и
конфигурации (настройки) системы;
- Скрипт самотестирования системы;
- Скрипт тестового набора данных;
- Тестовая коллекция документов;
- Тестовая онтология предметной области.
Для запуска функционирования системы необходимо:
- Установить на каждый сервер операционную
систему Debian Linux 6.0 x86;
- Обеспечить к каждому из серверов доступ по
протоколу SSH;
- Установить на сервер баз данных СУБД MySQL 5.3 Допускается
установка как с диска с дистрибутивом, так и из специального сетевого
репозитория операционной системы;
- Установить на сервер баз данных Web-сервер Apache 2. Допускается установка
как с диска с дистрибутивом, так и из специального сетевого репозитория
операционной системы;
- Установить на сервер приложения
виртуальную машину Java EE 1.7;
- Установить на сервер приложений контейнер
сервлетов Tomcat 6.0. Допускается установка как с диска с дистрибутивом, так и из
специального сетевого репозитория операционной системы;
- Установить на сервер приложений систему
полнотекстового поиска Sphinx 2.0;
- Запустить скрипт установки и
конфигурирования системы с диска с дистрибутивом системы. Следовать указания
скрипта;
- После успешного завершения работы скрипта
установки и конфигурирования системы запустить скрипты заполнения тестовыми
данными и самотестирования системы.
В случае успешной установки и конфигурирования системы web-интерфейс системы будет
доступен по адресу: [сервер]: 8080/OntoSearcher
После ввода запроса, указания онтологии предметной области и
искомых элементов запустить поиск. В случае успешной установки и конфигурации
системы будет выдан список найденных по запросу документов.
Для проверки работы системы необходимо открыть web-страницу формирования
запроса, после чего:
- Ввести текст запроса "Оплата
жилья";
- Выбрать онтологию предметной области
"Государственное управление: Жилищная политика";
- Выбрать искомые типы элементов:
Суперклассы, Эквивалентные классы, Субклассы;
- Нажать "Поиск"
В результате выполненных действий будет осуществлен поиск
документов и, в результате которого будет представлен список
документов-результатов поиска по двум запроса:
- "Оплата жилья" - введенный
пользователем запрос;
- "Оплата жилья | Оплата недвижимости |
Оплата жилища | Жилищный кредит жилья | Жилищный кредит недвижимости | Жилищный
кредит жилища | Ипотека жилья | Ипотека недвижимости | Ипотека жилища |
Ипотечный кредит жилья | Ипотечный кредит недвижимости | Ипотечный кредит
жилища
При этом, каждый из запросов будет соответствовать списку
документов-результатов поиска.
В результате работы был разработан прототип системы
интеллектуального поиска документов на основе онтологии предметной области,
включающий в себя регламентированные в Настоящем Документе разработанные
программную архитектуру системы и алгоритм расширения исходного
пользовательского поискового запроса. Данный прототип системы предназначается
для проведения дальнейших исследований в области применения онтологий
предметной области в задачах информационного поиска.
Оценка показателей релевантности результатов поиска
производится при помощи используемого системой внешнего программного
обеспечения.
Оценка показателей пертинентности результатов поиска будет
производиться при помощи статистического анализа результатов работы
пользователя с системой методом отметки открытых пользователем системы ссылок
на документы-результаты поиска по поисковому запросу.
1. ГОСТ
34.601-90. Информационная технология. Автоматизированные системы. Стадии
создания.
2. ГОСТ
34.602-89 Информационная технология. Техническое задание на создание
автоматизированной системы
. Требования
к оформлению квалификационных работ: метод. указания для студентов по
направлению 230200 "Информационные системы" / Сост.: А.П. Власов,
Н.А. Марчук: Иван. гос. хим. - технол. ун-т. - Иваново, 2010, 35 с.
. Требования
к содержанию квалификационных работ: метод. указания для студентов по
направлению 230200 "Информационные системы" / сост.: А.П. Власов,
С.П. Бобков, Н.И. Терехин: Иван. гос. хим. - технол. ун-т. - Иваново, 2010. -
40 с.
. Леоненков
А.В. Нотация и семантика языка UML -
http://www.intuit.ru/department/pl/umlbasics (28.03.2012) Сайт
"intuit.ru"
. Н.В.
Лукашевич. Тезаурусы в задачах информационного поиска, М.: Издательство
Московского Университета, 2011. - 512 с.
7. О.И. Россеева, Ю.А.
Загорулько. Организация эффективного поиска на основе онтологий. Труды
Международного семинара Диалог'2001 по компьютерной лингвистике и ее
приложениям, т.2, 2001. - http://www.dialog-21.ru/materials/archive. asp?
id=7029&y=2001&vol=6078
<http://www.dialog-21.ru/materials/archive.asp?id=7029&y=2001&vol=6078>
(01/04/2012)
. "Введение в
поисковые системы" / Ю. Лифшиц. - http://yury.
name/modern/05modernnote. pdf (01.04.2012);
9. "Архитектура
Google" / Александр Азаров, Ист. Вебпланета -
http://www.i2r.ru/static/334/out_22655. shtml
<http://www.i2r.ru/static/334/out_22655.shtml> (01.04.2012);
. "Профессиональный
поиск в Интернете: планирование поисковой процедуры" / Михаил Талантов -
http://citforum.ru/internet/search/prof_search02. shtml
<http://citforum.ru/internet/search/prof_search02.shtml> (10.04.2012)
. "Пертинентность
поиска - новый тренд в конкуренции поисковых систем" -
http://www.seonews.ru/analytics/detail/121831. php
<http://www.seonews.ru/analytics/detail/121831.php> (10.04.2012)
. "Университетская
Информационная Система РОССИЯ. Краткое описание" - http://uisrussia.
msu.ru/is4/main. jsp <http://uisrussia.msu.ru/is4/main.jsp> (10.04.2012)
. "Интеллектуальный
поиск изнутри" - <http://compsciclub.ru/courses/informationretrieval>
(10.04.2012)
14. "Information
Technology - Database Language SQL (Proposed revised text of DIS 9075)" /
Digital Equipment Corporation, Maynard, Massachusetts - http://www.contrib.
andrew. cmu.edu/~shadow/sql/sql1992. txt (01.04.2012);
. "RFC
2616 - Hyper Transfer Protocol - HTTP/1.1" / R. Fielding, UC Irvine, J.
Gettys, Compaq/W3C, J. Mogul, etc. - http://tools. ietf.org/html/rfc2616
(01.04.2012);
. "HTML5
- A vocabulary and associated APIs for HTML and XHTML - W3C Working Draft 29
March 2012" / Ian Hickson, Google, Inc. - http://dev. w3.org/html5/spec/
(01.04.2012)
17. "Теория и
практика использования SSH" / Vsevolod Stakhov -
http://www.opennet.ru/base/sec/ssh_intro. txt.html (01.04.2012)
. POSIX
. "Документация к
системе морфологии, разработанной в рамках системы УИС РОССИЯ"
. "Документация к
MySQL" - http://www.mysql.ru/docs/ (01.04.2012)
. "OWL, язык
веб-онтологий. Руководство" -
http://sherdim.ru/pts/semantic_web/REC-owl-guide-20040210_ru.html (01.04.2012)
22. "Uniform
Resource Locators (URL)" - http://tools. ietf.org/html/rfc1738
(01.04.2012)
. "Apache
HTTP Server Documentation" - http://httpd. apache.org/docs/ (01.04.2012)
. "OpenSSH
Manual pages" - http://www.openssh.com/manual.html (01/04/2012)
. "Apache
Tomcat 6.0 Documentation Index" - http://tomcat.
apache.org/tomcat-6.0-doc/index.html (01.04.2012)
. "Java
SE Specifications" - http://docs. oracle.com/javase/specs/ (01.04.2012)
27. "Документация
Debian Linux" - http://www.debian.org/support#doc (01.04.2012)
. "Центр справки
Java" - http://www.java.com/ru/download/help/index. xml (01.04.2012)
. "JavaServer
Pages Technology" -
http://www.oracle.com/technetwork/java/javaee/jsp/index.html (01.04.2012)
. "Справочник с
примерами по языку SQL" - http://sql. itsoft.ru/ (01.04.2012)
31. "RFC
2616 - Hyper Transfer Protocol - HTTP/1.1" / R. Fielding, UC Irvine, J.
Gettys, Compaq/W3C, J. Mogul, etc. - http://tools. ietf.org/html/rfc2616
(01.04.2012);
. "JavaScript
Tutorial" - http://www.w3schools.com/js/ (01.04.2012)
. "Documents
associated with UML Version 2.4.1" - http://www.omg.org/spec/UML/2.4.1/
(01.04.2012)
. "Visual
Paradigm for UML 9.0 Model-Code-Deploy Platform FAQ" -
http://www.visual-paradigm.com/product/vpuml/faq. jsp (01.04.2012)
35. "Embarcadero
Technologies Product Documentation - ER/Studio" - http://docs.
embarcadero.com/products/er_studio_enterprise/ (01.04.2012)
36. "Net
Beans - Documentation, Training, & Support" -
http://netbeans.org/kb/index.html (01.04.2012)
37. "Sphinx Online
HTML Documentation" - http://sphinxsearch.com/docs/ (01.04.2012)
. "Sphinx Online
HTML Documentation" - http://sphinxsearch.com/docs/ (01.04.2012)
39. "MySQL
Connector/J" - http://dev. mysql.com/doc/refman/5.1/en/connector-j.html
(01.04.2012)
. "Apache
Log4j 1.2.16 API" - http://logging.
apache.org/log4j/1.2/apidocs/index.html (01.04.2012)
Приложение
А
Фрагмент программного кода модуля онтологической обработки
запроса:
/*
* Project: Domain Ontology Driven Retrieval
System
* Organization: SRCC MSU, CIR
* Author: Krylov Al.
*
* Name: Ontology module
* Version: 1.0.0.0
* Date: Marth 2012
*
* Description: This class process ongology-query
semantic
*/
package search. modules;
import java. util. ArrayList;
import java. util. Iterator;
import java. util. List;
import java. util. Set;
import java. util. Properties;
import java. io. *;
import search. *;
import org. apache. log4j. *;
import org. semanticweb.
owlapi. apibinding. OWLManager;
import org. semanticweb.
owlapi. io. *;
import org. semanticweb.
owlapi. model. *;
import org. semanticweb.
owlapi. reasoner. *;
import org. semanticweb.
owlapi. util. SimpleIRIMapper;
import org. semanticweb.
owlapi. util. DefaultPrefixManager;
import org. semanticweb.
owlapi. io. *;
import org. semanticweb.
owlapi. model. *;
import org. semanticweb.
owlapi. reasoner. *;
import org. semanticweb.
owlapi. util. SimpleIRIMapper;
import org. semanticweb.
owlapi. util. DefaultPrefixManager;
/**
*
* @author blook
*/
public class
OntologyModule
{
private static Logger
logger = Logger. getLogger (SearchModule. class. toString ());
public int
FillOntologyQueryElements (SearchObject so)
{
int res = 0;
int onto_elements = 0;.
_ontoElements = new OntologyElementsCollection [16];
// for each ontologies in list.
for (String ontology_url:
so. _usedOntologies)
{ontology = this. GetOntology
(ontology_url);
if (ontology == null)
{
return 6101; // error in
ontology loading
}
// for each ontology elements type in list.
for (String query_element:
so. _queryElements)
{
for (String onto_type: so.
_ontoTypes)
{onto_el_col = new
OntologyElementsCollection ();= this. FillQueryElementsByOntology
(onto_el_col, onto_type, query_element, ontology);
if (res! = 0) { return
res; };. _ontoElements [onto_elements] = onto_el_col;_elements++;
}
}
}. _ontoElemQuantity = onto_elements;
return res;
}
public int
FillQueryElementsByOntology (OntologyElementsCollection onto_el_col,onto_type,
String element_name, OWLOntology ontology)
{
int res = 0;
// OntologyElementsCollection onto_el_col = new
OntologyElementsCollection ();
if (onto_type. equals
("SUB"))
{_el_col. _elements = this.
GetSubClassesForElement (element_name, ontology);
}
else if (onto_type.
equals ("EQU"))
{_el_col. _elements = this.
GetEquivalentClassesForElement (element_name, ontology);
}
else if (onto_type.
equals ("SUP"))
{_el_col. _elements = this.
GetSuperClassesForElement (element_name, ontology);
}
else
{. error ("Error in ontology elements type
list - unknown type: [" + onto_type + "] ");
return 6102; // error in
ontology elements type list (unknown type)
}_el_col. _type = onto_type;_el_col.
_sourceElement = element_name;_el_col. _ongology = ontology. getOntologyID ().
toString (). substring (1, ontology. getOntologyID (). toString (). length () -
1);
return res;
}
public OWLOntology GetOntology
(String ontology_url)
{. info ("stat GetOntology. [" +
ontology_url + "] ");onto_iri = IRI. create (ontology_url);ontology =
null;manager = OWLManager. createOWLOntologyManager ();
try
{= manager. loadOntology (onto_iri);
}
catch
(OWLOntologyCreationException ex)
{. error ("Error loading ontology: [" +
ontology_url + "] ");
}
return ontology;
}
// finction for filling list of subclsses by
ontology element name and ontology object
public List<String>
GetSuperClassesForElement (String element_name, OWLOntology ontology)
{. info ("start GetSuperClassesForElement.
[" + element_name + "] ");
int res = 0;<String>
sup_elements = new ArrayList<String> (); // FIXME! we mast
allocated memory in function body
// fixme
// ConsoleProgressMonitor progressMonitor = new
ConsoleProgressMonitor ();
// OWLReasonerConfiguration config = new
SimpleConfiguration (progressMonitor);manager = OWLManager.
createOWLOntologyManager ();fac = manager. getOWLDataFactory ();onto_id =
ontology. getOntologyID (). toString (). substring (1, ontology. getOntologyID
(). toString (). length () - 1);cls1Iri = IRI. create (onto_id + "#"
+ element_name);cls1 = fac. getOWLClass (cls1Iri);<OWLClassExpression>
classes = cls1. getSuperClasses (ontology);
for (OWLClassExpression cls:
classes)
{
// logger. info ("Equivalent class: " +
cls. toString (). substring (cls. toString (). indexOf ("#") +1, cls.
toString (). length () - 1));_elements. add (cls. toString (). substring (cls.
toString (). indexOf ("#") +1, cls. toString (). length () - 1));
}
return sup_elements;
}
// finction for filling list of super clsses by
ontology element name and ontology object
public List<String>
GetSubClassesForElement (String element_name, OWLOntology ontology)
{. info ("start GetSubClassesForElement.
[" + element_name + "] ");
int res = 0;<String>
sub_elements = new ArrayList<String> (); // FIXME! we mast
allocated memory in function body
// fixme - -
// ConsoleProgressMonitor progressMonitor = new
ConsoleProgressMonitor ();
// OWLReasonerConfiguration config = new
SimpleConfiguration (progressMonitor);manager = OWLManager.
createOWLOntologyManager ();fac = manager. getOWLDataFactory ();onto_id =
ontology. getOntologyID (). toString (). substring (1, ontology. getOntologyID
(). toString (). length () - 1);cls1Iri = IRI. create (onto_id + "#"
+ element_name);cls1 = fac. getOWLClass (cls1Iri);<OWLClassExpression>
classes = cls1. getSubClasses (ontology);
for (OWLClassExpression cls:
classes)
{
// logger. info ("Equivalent class: " +
cls. toString (). substring (cls. toString (). indexOf ("#") +1, cls.
toString (). length () - 1));_elements. add (cls. toString (). substring (cls.
toString (). indexOf ("#") +1, cls. toString (). length () - 1));
}
return sub_elements;
}
// function for filling list of equivalent
classes by ontology element name and ontology object
public List<String>
GetEquivalentClassesForElement (String element_name, OWLOntology ontology)
{. info ("start GetEquivalentClassesForElement.
[" + element_name + "] ");
int res = 0;<String>
equ_elements = new ArrayList<String> (); // FIXME! we mast
allocated memory in function body
// fixme - -
// ConsoleProgressMonitor progressMonitor = new
ConsoleProgressMonitor ();
// OWLReasonerConfiguration config = new
SimpleConfiguration (progressMonitor);manager = OWLManager.
createOWLOntologyManager ();fac = manager. getOWLDataFactory ();onto_id =
ontology. getOntologyID (). toString (). substring (1, ontology. getOntologyID ().
toString (). length () - 1);cls1Iri = IRI. create (onto_id + "#" +
element_name);cls1 = fac. getOWLClass (cls1Iri);<OWLClassExpression>
classes = cls1. getEquivalentClasses (ontology);
for (OWLClassExpression cls:
classes)
{
// logger. info ("Equivalent class: " +
cls. toString (). substring (cls. toString (). indexOf ("#") +1, cls.
toString (). length () - 1));_elements. add (cls. toString (). substring (cls.
toString (). indexOf ("#") +1, cls. toString (). length () - 1));
}
return equ_elements;
}
// module testing
public static void
main (String [] args)
{onto_url =
"http://budgetrf.ru/Publications/Ontology/Ontology1321427863687.
owl";
// String z = localPizza. getOntologyID ().
toString (). substring (1, localPizza. getOntologyID (). toString (). length ()
- 1);test_so = new SearchObject ();_so. getResources ();_so. _query =
"Оплата жилья";_so.
_queryElements. add ("Р-РёР"СЊРµ");_so. _queryElements. add ("РћРїР"ата");_so. _ontoTypes.
add ("SUB");_so. _ontoTypes. add ("EQU");_so. _ontoTypes.
add ("SUP");_so. _usedOntologies. add (onto_url);test_onto_mod = new
OntologyModule ();
int res = test_onto_mod.
FillOntologyQueryElements (test_so);
for (int i = 0; i
< test_so. _ontoElemQuantity; i++)
{
// System. out. println ("Ontology: " +
test_so. _ontoElements [i]. _ongology);
for (int j = 0; j
< test_so. _ontoElements [i]. _elements. size (); j++). out. println
(test_so. _ontoElements [i]. _elements. get (j));
}_so. clearResources ();
}
}
Структура
внутримашинной информационной базы

База
онтологий
Принципы
построения внутримашинной информационной базы
Структура
внутримашинной информационной базы
База
индексов документов системы
Принципы
построения внутримашинной информационной базы
Структура
внутримашинной информационной базы
База
индексируемых образов документов системы
Принципы
построения внутримашинной информационной базы
Структура
внутримашинной информационной базы
База
словарей сервиса морфологии
База
файлов конфигурации системы
Принципы
построения внутримашинной информационной базы
Структура
внутримашинной информационной базы
База
лог-файлов работы системы
Принципы
построения внутримашинной информационной базы
Структура
внутримашинной информационной базы
Организация
внемашинной информационной базы
5.4 Описание
программного обеспечения
Структура
программного обеспечения
Подсистема
реализации интеллектуального поиска
Функции
программного обеспечения
Методы
и средства разработки программного обеспечения
Операционная
система
Средства,
расширяющие возможности операционной системы
Apache
HTTP-сервер
OpenSSH-сервер
Система
управления базами данных MySQL
Apache
Tomcat
Java
Virtual Machine
5.5 Описание
алгоритма (проектной процедуры)
Алгоритм
онтологической обработки поискового запроса
Название
и характеристика
Назначение
алгоритма
Обозначение
документа "Описание постановки задач"
Сведения
о процессе (объекте), при управлении которым используется алгоритм
Ограничения
на возможность и условия применения алгоритма
Общие
требования к входным и выходным данным
Используемая
информация

Массивы
информации, сформированные из входных сообщений
Результаты
решения
Массивы
информации и (или) сигналы, формируемые для выдачи выходных сообщений

Массивы
информации, сохраняемой для решения данной и других задач АС
Математическое
описание
Алгоритм
решения
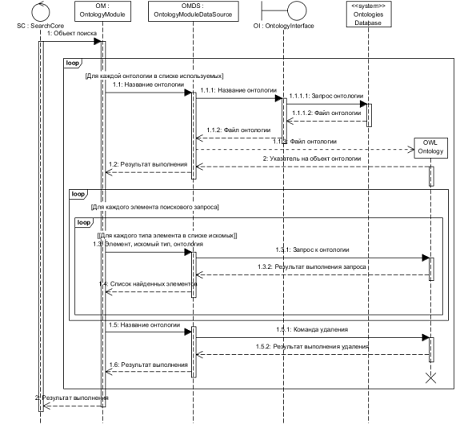
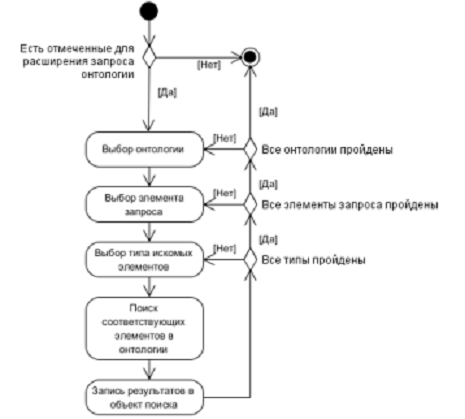
Описание
логики алгоритма
Соотношения,
необходимые для контроля достоверности вычислений
Описание
связей между частями и операциями алгоритма
6. Рабочая
документация
6.1
Руководство пользователя
Введение
Область
применения
Краткое
описание возможностей
Уровень
подготовки пользователя
Перечень
эксплуатационной документации
Назначение
и условия применения
Программные
и аппаратные требования к ссистеме
Подготовка
к работе
Состав
дистрибутива
Запуск
системы
Контрольный
пример
Заключение
Список
используемой литературы
Приложения