Материал: Программная реализация модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
Обычно с программой сопоставляют исходный код и исполняемый код, а также объектный код, как промежуточный этап. Материалом для анализа, может являться программа в каком-то из ее представлений. В частности, существенно разные подходы используются при анализе исходного и исполняемого кода программы. Исходный код программы анализировать легче, поскольку в нем сохраняется больше характеристик свойственных конкретному автору (в основном это касается стилистических особенностей автора, которые при компиляции в основном утрачиваются). Тем не менее, и по исполняемому коду тоже можно искать, много индивидуальной информации хранится и там (используемые алгоритмы, специфические ошибки, способ организации данных).
Принято выделять два основных подхода к оценке близости программ (и соответственно разработке алгоритмов поиска плагиата): атрибутный (attribute-counting) и структурный. Впрочем, такое деление несколько условно. Существуют также методы, сочетающие в себе оба подхода [11].
2.2 Атрибутные
методы поиска плагиата
Исторически первыми появились атрибутные методы. Смысл их заключался в численном выражении каких-то признаков (атрибутов) программы и сравнении полученных чисел для разных программ. Программы с близкими численными характеристиками атрибутов (attribute counts) потенциально похожи. В простейшем случае можно использовать, например, размер программы или количество переменных.
Можно комбинировать несколько признаков, так чтобы программа была представлена не одним числом, а некоторым набором. Две программы могут считаться похожими, если соответствующие числа из их наборов совпадают или близки. В разное время для описания программ были предложены такие атрибуты, как количество операторов и операндов и другие. Таким образом, оценка близости программ сводится к сравнению чисел или векторов, которые получаются путем несложного анализа непосредственно исходного кода. Основным недостатком атрибутных техник является то, что несвязанные между собой параметры программы плохо описывают ее в целом, и при таком подходе разные программы получают близкие характеристики. Атрибутные методы активно развивались в 80-х годах XX столетия, но постепенно отошли на второй план.
.3 Структурные
методы поиска плагиата
Другой, более современный и перспективный подход состоит в сравнении программ с учетом их структуры. Эта процедура более сложная, чем сравнение численных выражений отдельных свойств программы. Структурные методы исследуют свойства программы не изолированно, а как бы в контексте, устанавливают взаимосвязь различных характеристик, их совместное поведение.
Чтобы отбросить лишнюю информацию и выделить нужные зависимости, программу предварительно переводят в более компактное представление. Как правило, сами по себе атрибутные методы малоэффективны, структурные методы превосходят их по качеству. Недостатком структурных методов является их сложность и вычислительная трудоемкость. Классическим примером структурного подхода является построение дерева программы с последующим сравнением деревьев для разных программ. Трудоемкость такого метода кубическая, что не даёт возможности сколько-нибудь эффективно его применять для большого числа достаточно длинных программ. Кроме того, структурные методы обычно опираются на синтаксис конкретного языка программирования. Адаптация метода для другого языка требует значительных усилий. Сложность реализации алгоритмов, сравнивающих структуру программ, является платой за их точность.
.3.1 Строковое выравнивание
Пусть есть две программы, представим их в виде строк токенов a и b соответственно (возможно различной длины). Теперь можно воспользоваться методом локального выравнивания строк. Выравнивание двух строк получается с помощью вставки в них пробелов таким образом, чтобы их длины стали одинаковыми. Для этого меньшую последовательность необходимо разбить на блоки и произвести оптимальное выравнивание (то есть такое, при котором будет максимальное количество совпадений при сравнении выравненных строк a и b). Алгоритм очень зависим от токенизации кода программы, что делает его зависимым от языка программирования.
.3.2 Метод поиска на XML-представлении
Представление программы в виде дерева (рисунок
3) отражает ее полезные для поиска плагиата свойства (такие как логика
управления), и не учитывает бесполезные (например, порядок следования
независимых операторов). Метод поиска плагиата основан на представлении
программы в виде дерева, описание которого хранится в формате XML.
Использование стандартных инструментов для работы с XML
значительно упрощает архитектуру детектора плагиата. Программы, написанные на
процедурных языках, таких как Pascal
и С, хорошо структурированы, поэтому получить их XML-представление
легко. Для оценки близости двух программ используются числовые матрицы,
построенные на основе XML
описаний.
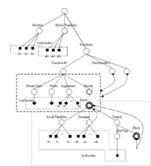
Рисунок 3 Представление программы в виде дерева
.3.3 Использование приближения Колмогоровской сложности
В алгоритме используется расстояние между
последовательностями, основанное на теории информации (an
information
based
sequence
distance):
![]()
где К(х) - Колмогоровская сложность последовательности х. Она показывает сколько информации содержит последовательность х. По определению, К(х) - длина самой короткой программы, которая на пустой ввод печатает х, К(х|у) - количество информации, полученной х от у, если пусто, то оно равно К(х); (К(х) - К(х|у)) - сколько у "знает" о х. По определению, К(х|у) - это длина самой короткой программы, которая на ввод у печатает х.
2.3.4 Метод идентификационных меток
При поиске плагиата требуется находить копии и частичные копии файла в тестовой базе большого объема. В этом случае непосредственное сравнение файлов не эффективно. Для файлов в базе вычисляются наборы меток. Строится общий указатель, где каждой метке сопоставлен файл и место, где она встречается. Сверив метки проверяемого файла с указателем, выбираем файлы, с которыми обнаружено наибольшее число совпадений. Информацию о них выдаем. Трудоемкость (количество сравнений) зависит от заданного пользователем уровня точности.
.3.5 Нейросетевые методы обнаружения плагиата
Поиск плагиата можно свести к задаче классификации. Как известно, нейронные сети - это один из лучших инструментов для решения задачи аппроксимации функций, и в частности, классификации.
Нейронную сеть (рисунок 4) можно представить как
черный ящик, на вход которому подается известная информация, а на выходе
выдается информация, которую хотелось бы узнать.
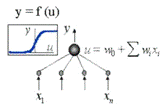
Рисунок 4 Нейронная сеть
.4 Другие методы
Идея состоит в совмещении двух описанных подходов для поиска плагиата в большой базе программ. Для этого на первом этапе с помощью достаточно аккуратного атрибутного метода можно отсеивать заведомо "непохожие" программы. В качестве такого метода можно выбрать сравнение наборов ключевых слов программ.
На следующем этапе будет производиться более детальное сравнение оставшихся программ структурным методом. Здесь, например, возможно применение какого-нибудь уже существующего детектора. Таким образом, за счет предварительного несложного анализа сокращается количество попарных сравнений при поиске плагиата в большой базе программ, а, следовательно, растет эффективность.
3
МЕТОДЫ ПОИСКА ПЛАГИАТА В ПРОИЗВОЛЬНЫХ ТЕКСТАХ
Если говорить о методах выявления плагиата в произвольных текстах, то часто вместо слова «плагиат» используют термин «нечеткий дубликат». Эти методы можно разделить на два больших класса. Алгоритмы, которые используют определенные знания о всей рассматриваемой коллекции документов, называют глобальными, в противном случае - локальными.
.1 Локальные методы
Рассмотрим, для начала, локальные алгоритмы. Основная идея таких методов сводится к синтаксическому анализу документа. На основе этого анализа документу ставится в соответствие определенное количество сигнатур.
.1.1 LongSent
Простейшим примером может служить алгоритм, который вычисляет хеш-функцию (MD5, SHA-2, CRC32) от конкантенации двух самых длинных предложений в документе. Это и будет являться его сигнатурой. Точность такого алгоритма достаточно большая, но он обладает существенным изъяном в безопасности. Такой алгоритм легко обмануть. Достаточно откорректировать всего лишь два самых длинных предложения.
.1.2 Методы на основе меры TF
Более эффективным способом нахождения нечетких дубликатов может стать метод, основанный на понятии TF (term frequency - частота слова). TF - это отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом оценивается важность слова в пределах отдельного документа. Для каждого слова в документе вычисляется его вес, равный отношению числа вхождения этого слова к общему количеству слов документа. Далее сцепляются n упорядоченных слов с наибольшим значением веса и вычисляется хеш-функция. Такой подход позволяет улучшить ситуацию, но для решения реальных задач этот способ не подходит.
.1.3 Методы, использующие понятия шинглов
Один из первых методов, который был применен на практике (компанией AltaVista), основывался на понятие шинглов. Данный подход был предложен A. Broder [40]. Этот метод детально будет рассмотрен в разделе 4.3.
.1.4 Методы, использующие семантические сети
Также интересным подходом является использование семантической сети. Задача определения факта заимствования сводится к сравнению моделей, отражающих смысловую нагрузку текстов. Анализ ведется с использованием алгоритмов на графах, модифицированных и оптимизированных для применения в рамках данной задачи. Использование схем анализа данных в этом методе может позволить выявлять факт заимствования, даже если оригинал был определенным образом модифицирован (выполнен перевод, слова были заменены на синонимы, текст был изложен с использованием другой лексики и т.д.).
.2 Глобальные методы
.2.1 Методы на основе меры TF-IDF
Дальнейшее развитие метода,
использующего меру TF,
стал алгоритм, анализирующий документы всей коллекции. В нем используются мера TF-IDF.
IDF (inverse document frequency - обратная частота документа) - инверсия
частоты, с которой некоторое слово встречается в документах коллекции.
![]()
где |d|
- количество документов в коллекции; ![]()
![]() - количество документов, в которых
встречается терм tt.
- количество документов, в которых
встречается терм tt.
Вес широкоупотребительных слов можно сократить при учете IDF, то есть мера TF-IDF состоит из произведения TF и IDF. В мере TF-IDF больший вес будет у тех слов, которые часто использовались в одном документе и реже - в другом. Соответственно, при вычислении веса для каждого терма, алгоритм использует формулу TF * IDF. После этого в строку в алфавитном порядке сортируются 6 слов, которые имеют наибольшее значение веса. Контрольная сумма CRC32 полученной строки вычисляется в качестве сигнатуры документа.
Существуют различные
модификации формулы вычисления веса слова. В поисковых системах широко известно
семейство функций BM25.
Одна из распространенных форм этой функции приведена ниже.
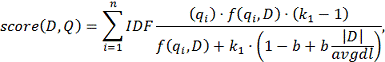
где f(qi , D) - это частота слова qi в документе D, |D| - это длина документа (количество слов в нём), а avgdl - средняя длина документа в коллекции. k1 и b - свободные коэффициенты, обычно их выбирают как k1 = 2.0 и b = 0.75. IDF(qi) - обратная документная частота слова qi .
3.2.2 I-Match метод
Еще один сигнатурный метод в 2002 году предложил A. Chowdhury [42]. Идея подхода тоже заключалась на знании всей коллекции документов. Предложенную методику автор усовершенствовал в 2004 году [43,44]. Ключевая идея данного метода основывалась на вычислении дактилограммы I-Match для демонстрации содержания документов. Изначально для исходной коллекции документов строился словарь L, который включает слова со средними значениями IDF. Именно они позволяли добиться наиболее точных показателей при выявлении нечетких дубликатов. Отбрасывались при этом те слова, которые имели большие и маленькие значения IDF. После этого для каждого документа создавалось множество U различных слов, состоящих в нем, и высчитывалось пересечение U и словаря L. Экспериментальным методом вычислялся минимальный порог и если размер пересечения превышал его, то список входящих в пересечение слов упорядочивался. Далее нужно посчитать I-Match сигнатуру (хеш-функция SHA1).
Следовательно, здесь мы видим следующую ситуацию: два документа будут считаться одинаковыми, если у них совпадут I-Match сигнатуры. В отличие от алгоритма, предложенного A. Broder., данный метод имеет больший потенциал. Он демонстрирует значительно улучшенную вычислительную способность. Опять же, если сравнивать с алгоритмом A. Broder, еще одним достоинством в пользу этого алгоритма становится то, что он значительно эффективнее проявляет себя при сравнении небольших по объему документов.
К сожалению, у данного алгоритма есть и свой недостаток - при небольшом изменении содержания он показывает свою неустойчивость. Чтобы исключить данный недостаток, авторы решили подвергнуть алгоритм изменению и усовершенствовать его. Была предложена новая техника многократного случайного перемешивания основного словаря. Суть модификаций заключается в следующем: к основному словарю L создаются K различных словарей L1-LK, которые образуются методом случайного удаления из исходного словаря определенной закрепленной части p слов. Эта небольшая группа p слов составляет приблизительно 30%-35% от исходного объема L. Для каждого документа вместо одной, вычисляется (K+1) I-Match сигнатур по алгоритму, который описан выше. Получается, что документ демонстрируется как вектор размерности (K+1). В таком случае два документа между собой будут считаться одинаковыми, если одна из координат у них совпадает. На практике, в качестве самых оптимальных значений параметров хорошо зарекомендовали себя такие показатели: p = 0.33 и K = 10.
Данный алгоритм продемонстрировал эффективную способность фильтрации спама при использовании в приложениях веб-поиска.
.2.3 Метод «опорных» слов
Существует еще один способ выявления почти дубликатов, основанный на сигнатурном подходе. Данный метод тоже заключается в использовании лексических принципов, то есть на основе словаря. Метод был предложен С. Ильинским и др. [46] и получил название - метод «опорных» слов. Рассмотрим более детально принцип данного алгоритма.
Изначально из индекса по правилу, описанному ниже, мы выбираем множество из N слов, называемых «опорными». В данном случае, N определяется экспериментально. В дальнейшем, каждый документ выглядит N-мерным двоичным вектором, в котором i-я координата равна 1, если i-е «опорное» слово имеет в документе относительную частоту выше определенного порога (устанавливаемого отдельно для каждого «опорного» слова) и равна 0 в противном случае. Этот двоичный вектор и является сигнатурой документа. Соответственно, два документа считаются идентичными при совпадении сигнатур. При построении множества «опорных» слов используются следующие соображения:
. Множество слов должно охватывать максимально возможное число документов.
. Число слов в наборе должно быть минимальным.
. При этом «качество» слова должно быть максимально высоким. Рассмотрим принцип построения множества алгоритма и выбор пороговых частиц. Допустим «частота» - это нормированная внутридокументная частота слова в документе TF, которая находится в диапазоне 0...1, единица в данном случае будет соответствовать наиболее частому слову в документе TF. Распределение документов по данной внутридокументной «частоте» строится для каждого слова однократно. Рассмотрим несколько этапов, каждый из которых состоит из двух фаз. В первой фазе увеличивается покрытие документов в индексе при фиксированной (ограниченной снизу) точности. Во второй фазе уже увеличивается точность при фиксированном покрытии. В данном случае точность будет максимально высокой, если повторение слова в дельта-окрестности значения относительной частоты минимально. Частота, которая имеет наибольшую точность, получила название пороговой. Поэтапно сортируются самые неподходящие слова, а когда наступает последняя стадия, то остаются только группы слов, которых достаточно для обеспечения качественного покрытия. Получается, что благодаря этому алгоритму, можно отфильтровать несколько тысяч слов и оставить только 3-5 тысяч.