Материал: Программная реализация модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
Программная реализация модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
СОДЕРЖАНИЕ
плагиат поиск программирование
ВВЕДЕНИЕ
Актуальность магистерской диссертации
Понятие плагиата
Специфика понятия «плагиат» в программировании: окончательный вывод о заимствовании делает человек
Постановка задачи
.1 Необходимость дополнительной проверки на основе структурного анализа кодов
.2 Общая схема работы модулей инструментальной системы поиска плагиата
Теоретические основы поиска плагиата в исходных кодах программ
.1 Классификация методов поиска плагиата в программировании
.2 Атрибутные методы поиска плагиата
.3 Структурные методы поиска плагиата
.3.1 Строковое выравнивание
.3.2 Метод поиска на XML-представлении
.3.3 Использование приближения Колмогоровской сложности
.3.4 Метод идентификационных меток
.3.5 Нейросетевые методы обнаружения плагиата
.4 Другие методы
Методы поиска плагиата в произвольных текстах
.1 Локальные методы
.1.1 LongSent
.1.2 Методы на основе меры TF
.1.3 Методы, использующие понятия шинглов
.1.4 Методы, использующие семантические сети
.2 Глобальные методы
.2.1 Методы на основе меры TF-IDF
.2.2 I-Match метод
.2.3 Метод «опорных» слов
.3 Метод шинглов
.3.1 Канонизация текстов
.3.2 Разбиение на шинглы
.3.3 Вычисление хешей шинглов
.4 Дистанция (расстояние) Левенштейна
.4.1 Алгоритм Вагнера - Фишера
.5. Наибольшая общая последовательность (longest common subsequence, LCS) 3.6 Вычисление хеш-функции
.6.1 Параметры вычисление хеш-функции: полином-генератор, разрядность и стартовое слово
.6.2 Популярные и стандартизованные полиномы
.7 Виды представления исходного кода
.8 Представление исходного кода в виде токенов
Обзор инструментальных средств и сервисов анализа плагиата в программах и произвольных текстах
.1 Обзор программ поиска плагиата в программировании
.2 Обзор сервисов поиска плагиата
.3 Обзор программ поиска плагиата в произвольных текстах
Описание используемых методов поиска плагиата в исходных кодах и произвольных текстах
.1 Общая схема поиска
.1.1 Cхема поиска для исходных кодов
.1.2 Основной структурный метод для анализа исходных кодов
.1.2.1 Достоинства и недостатки
.1.3 Дополнительный атрибутный метод для исходных текстов
.1.3.1 Достоинства и недостатки
.2.1 Cхема поиска для произвольных текстов (в том числе и программ)
Программная реализация модуля поиска плагиата методами анализа исходных кодов программ
.1 Интерфейс модуля поиска плагиата в исходных кодах программ
.1.1 Главное окно модуля поиска плагиата методами анализа исходных кодов
.1.2 Окно групповых режимов анализа
.2 Взаимодействие модуля поиска плагиата методами анализа исходных кодов
.2.1 Взаимодействие модуля с архивом работ и базой языков (добавление файла в базу)
.2.2 Взаимодействие модуля с архивом работ и базой языков (частотный анализ, автоматический частотный анализ)
.2.3 Взаимодействие модуля с архивом работ и базой языков (автоматический анализ последовательностей операторов)
.2.4. Взаимодействие модуля с архивом работ и базой языков (анализ последовательностей операторов, просчет всех пиков)
.2.5 Взаимодействие модуля с архивом работ и базой языков (удаление файла/языка из базы)
.2.6 Взаимодействие модуля с базой языков (добавление языка в базу)
.2.7 Пакетный режим анализа (1->n)
.2.8 Полный анализ (n->n)
.2.9 Поиск первоисточника и списка первоисточников
.2.10 Некоторые особенности модуля
.3 Описание отчетов по анализу плагиата
.3.1 Критерии автоматического заключения о наличии плагиата при пакетном и полном анализе
.3.2 Алгоритм поиска первоисточника для файла или списка первоисточников при полном анализе
.3.3 Сводный отчет
.3.4 Итоговый отчет
.3.5 Экспорт итогового протокола в Excel
.3.5.1 Исследование итогового протокола по полученным диаграммам Excel
.3.6 Экспорт списка первоисточников в Excel
.3.6.1 Исследование списка первоисточников в Excel
.4 Пример работы модуля
.4.1 Пример 1 анализа последовательности операторов
.4.2 Пример 2 автоматического анализа частот появления операторов
Программная реализация модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
.1 Интерфейс модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
.1.1 Главное окно модуля PlagiatSearch поиска плагиата методами сравнения произвольных текстов
.1.2 Меню «Анализ» и его возможности для поиска плагиата в произвольных текстах
.1.3 Информационное окно модуля PlagiatSearch поиска плагиата в произвольных текстах с результатами вычисления дистанции Левенштейна
.1.4 Представление результатов нахождения наибольшей общей подпоследовательности (longest common subsequence, LCS)
.1.5 Представление метода шинглов для сравнения произвольных текстов
.1.6 Применение метода шинглов для сравнения исходных кодов
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ (БИБЛИОГРАФИЧЕСКИЙ СПИСОК)
ПРИЛОЖЕНИЕ
Доработанная блок-схема алгоритма анализа последовательности операторов (с показом наиболее длинного совпадающего фрагмента кода)
ВВЕДЕНИЕ
Актуальность магистерской диссертации
В учебных заведениях многие курсовые и лабораторные работы студентов состоят из описательной (текстовой) и программной части. Поэтому актуально создание приложений, позволяющих обнаружить списывание и текста и программного кода. В диссертации сделан акцент не столько на развитии конкретного метода поиска плагиата в исходных кодах программ студентов ([1-2]) или на развитии средств автоматизации такого поиска при большом объеме базы данных студентов (как это сделано в работе автора на степень бакалавра), сколько на реализации методов более глубокого анализа материала разными взаимно дополняющими методами (дистанция Левенштейна, Дамерау, метод шинглов, LCS). Это весьма важно, так как показал опыт применения только автоматизированных методов, без наличия дополнительных инструментов трудно сделать правильный вывод о наличии заимствований. Такой пример неполного анализа будет приведен в диссертации ниже в разделе 2.1.
Актуальность изучаемой проблемы подтверждается достаточно большим числом публикаций, в которых рассматриваются различные подходы, методы реализации и конкретные инструментальные средства поиска плагиата в работах студентов [18-25]. Новизна работы заключается в том, что в ней объединены в рамках единых инструментальных средств как алгоритмы поиска плагиата в программных кодах, так и в произвольных текстах (не только программах).
В работе рассматриваются в теоретическом и практическом плане следующие вопросы:
· Методы анализа произвольных текстов и исходных кодов программ с точки зрения наличия идентичных фрагментов;
· Разработка набора инструментов анализа исходных кодов программ из двух взаимно дополняющих модулей (рисунок 1): первый анализирует исходный код методами анализа исходных кодов (частотного анализа и анализа токенизированной последовательности операторов) в программных модулях студентов на основе пополняемой текстовой базы данных (БД), а второй позволяет анализировать этот же исходный код методами анализа произвольных текстов;
· Реализация во втором модуле алгоритма поиска заимствованных фрагментов в исходных кодах программ, интегрирующего структурный анализ кодов (на основе исходного либо токенизированного представления), метода шинглов, дистанции Левенштейна и нахождения наибольшей общей подпоследовательности (longest common subsequence, LCS) для произвольных текстов. Если второй модуль рассматривает произвольный текст как исходный код программы (в модуле не установлен флажок «Текст»), то он использует ту же самую пополняемую БД работ студентов, которую формирует первый модуль.
Все это в совокупности позволяет значительно
расширить возможности проверяющего в части визуализации подозрительных
фрагментов кода и более глубокого анализа сравниваемых текстов.
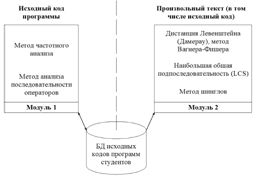
Рисунок 1. Реализованные в инструментальной системе методы
Понятие плагиата
Понятие плагиата достаточно широко и нечетко, более того, многие понимают плагиат по-разному в зависимости от области, в которой они работают. Поэтому сошлемся на определения того, как понимается плагиат в различных предметных областях, приведенные в работе [3].
· Плагиат - буквальное заимствование из чужого литературного произведения без указания источника [4].
· Плагиат (от лат. plagio - похищаю) - вид нарушения прав автора или изобретателя. Состоит в незаконном использовании под своим именем чужого произведения (научного, литературного, музыкального) или изобретения, рационализаторского предложения (полностью или частично) без указания источника заимствования [5].
· Плагиат - присвоение плодов чужого творчества: опубликование чужих произведений под своим именем без указания источника или использование без преобразующих творческих изменений, внесённых заимствователем [6].
· Плагиат - умышленное присвоение авторства на чужое произведение науки, литературы или искусства. Не считается плагиатом заимствование темы или сюжета произведения либо научных идей, составляющих его содержание, без заимствования формы их выражения.
· Плагиат - вид нарушения авторских прав [7], состоит в незаконном использовании под своим именем чужого произведения (научного, литературного, музыкального) или изобретения, рационализаторского предложения (полностью или частично) без указания источника заимствования [8] . Принуждение к соавторству также рассматривается как плагиат [9].
Для того чтобы избежать плагиата при написании текстов, важно соблюдать простые правила:
· ссылаться на источники приводимой информации (фактов, мнений, теорий, статистики, графиков, рисунков), если она не является общеизвестной;
· приводить в кавычках высказывания или отрывки из произведений других авторов;
Специфика понятия «плагиат» в программировании: окончательный вывод о заимствовании делает человек
В программировании понятие плагиата кажется не столь очевидным, учитывая, что для достаточно простых или типовых задач в инструментальных средах имеется достаточно большое число шаблонов, которыми рекомендуется пользоваться. И часто даже профессиональные программисты (а не только студенты) пользуются готовыми шаблонами. В качестве примера сошлемся на огромный набор готовых к использованию шаблонов сайтов, которые выложены в сети по лицензии GPL. Если анализировать чисто программный код таких сайтов, самостоятельно реализованных web-разработчиками с использованием, например, CMS Joomla или WordPress, то можно заподозрить их в плагиате. Хотя на самом деле никакого плагиата здесь нет. А практически вся собственная работа программиста просто вынесена в информацию, хранимую в базе данных. Аналогично состоит дело и при использовании таких инструментов программирования Visual Studio, Delphi или Eclipse.
Поэтому вывод о плагиате в программировании может не быть столь очевидным, даже при большом совпадении исходного кода программ. И требуется детальный (как правило, содержательный) анализ того, как создавался код программы с помощью шаблона (или мастера, генератора программ) или с нуля. Именно, исходя из этого тезиса, в магистерской диссертации были значительно расширены средства визуализации подозрительных фрагментов кода и реализованы новые методы.
1
ПОСТАНОВКА ЗАДАЧИ
В магистерской диссертации рассматривается развитие программной системы, выявляющей заимствованные фрагменты исходного кода в анализируемых программных модулях студентов на основе пополняемой текстовой базы данных исходных текстов программ, а также реализация новых инструментов для анализа произвольных текстов с точки зрения наличия одинаковых фрагментов. Для анализа заимствованных фрагментов в исходных кодах программ предлагается обобщенный подход, совмещающий метод структурного анализа кодов (токены), методы шинглов и дистанции Левенштейна-Дамерау для анализа произвольных текстов.
Целями магистерской диссертации являются:
· Развитие инструментальных средств и методов анализа плагиата в части реализации возможностей дополнительной и более глубокой проверки на основе структурного анализа кодов.
· Усовершенствование инструментальных средств и расширение методов поиска потенциального плагиата с помощью метрик Левенштейна, Дамерау и метода шинглов.
.1 Необходимость
дополнительной проверки на основе анализа структурного анализа кодов
Разработанные ранее (в дипломе на степень
бакалавра) методы автоматического анализа исходных кодов программ иногда не
позволяют выявлять факт частичного заимствования текстов. В качестве
подтверждения этого тезиса покажем это на примере сравнения двух программ из
базы данных работ студентов. Хотя оба метода (частотного анализа текста и
анализа последовательности операторов) показывают, что плагиата нет (рисунок 2,
a),
но, если посмотреть (рисунок 2, b)
на наиболее длинную совпадающую последовательность операторов (рисунок 2, c),
выделенную красным цветом в текстах программ (эта возможность была специально
добавлена в ходе работы над магистерской диссертацией), то хорошо виден факт,
по крайней мере, частичного заимствования кода, вплоть до одинакового порядка
операторов и идентичного обозначения переменных.
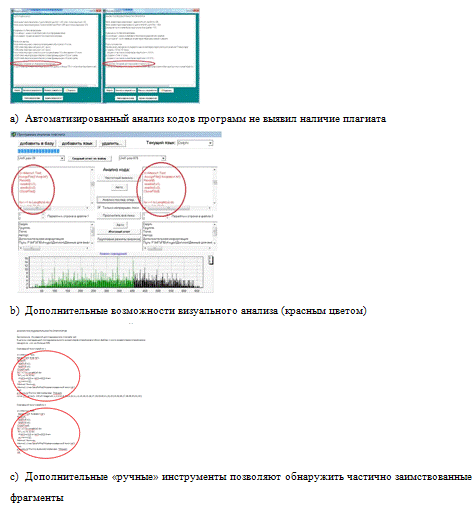
Рисунок 2. Пример явного частичного заимствования исходного кода, не выявленный автоматическими методами
.2 Общая схема
работы модулей инструментальной системы поиска плагиата
Как показано во введении, общая схема работы инструментальной системы поиска плагиата состоит из двух взаимодополняющих модулей. Первый модуль анализирует исходный код методами анализа исходных кодов (частотного анализа и анализа токенизированной последовательности операторов) в программных модулях студентов на основе пополняемой текстовой базы данных (БД), а второй модуль позволяет анализировать этот же исходный код методами анализа произвольных текстов, интегрирующего структурный анализ кодов (на основе исходного либо токенизированного представления), метода шинглов, дистанции Левенштейна и нахождения наибольшей общей подпоследовательности (longest common subsequence, LCS) для произвольных текстов. Если второй модуль рассматривает произвольный текст как исходный код программы (в модуле не установлен флажок «Текст»), то он использует ту же самую пополняемую БД работ студентов, которую формирует первый модуль.
2
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ПОИСКА ПЛАГИАТА В ИСХОДНЫХ КОДАХ ПРОГРАММ
.1 Классификация
методов поиска плагиата в программировании
Для поиска плагиата на практике некоторым образом задаётся функция близости («метрика») и некоторый порог, по которому можно определить насколько вероятно, что часть программного кода была заимствована. Поиск плагиата в программировании может основываться на анализе характеристик кодов программ. Любая программа имеет определенную иерархию структур, которые могут быть выявлены, измерены и использованы в качестве таких характеристик. Применительно к доказательству факта заимствования, эти характеристики должны слабо меняться в случае модификации программы или включения фрагментов одной программы в другую.