Материал: Программа для поддержки процессов выявления проблемных запросов в СУБД Oracle
Программа для поддержки процессов выявления проблемных запросов в СУБД Oracle
ВВЕДЕНИЕ
запрос программный авторизация
Нельзя не учитывать значимость эффективных SQL-запросов в основанных на использовании СУБД Oracle программах. Всего один индекс или плохо написанный запрос могут застопорить работу всей системы.
В настоящее время не существует программных средств для наглядного обучения анализу SQL-запросов, просмотру планов запросов и поиску проблемных мест.
Актуальность работы заключается в том, что БД является неотъемлемой частью практически любой автоматизированной системы, а эффективно написанный запрос позволяет не только увеличить производительность приложения, но и снизить сетевой трафик. Поэтому как студенты, изучающие курс «Базы данных», так и разработчики автоматизированных систем должны понимать работу оптимизатора запросов и существующие возможности настройки, которая может сделать запросы более эффективными и менее рискованными.
Целью настоящего исследования является упрощение процесса выявления проблемных запросов в СУБД Oracle.
Для достижения поставленной цели необходимо решить следующие задачи:
Изучить существующие методы диагностики работы баз данных, включающие в себя анализ планов запросов, работу со служебными представлениями Oracle.
Изучить возможные способы реализации программного средства, недостатки и достоинства каждого из подходов.
На основании полученной теоретической базы спроектировать и разработать программное средство, решающее поставленную задачу.
Практическая значимость данной работы
заключается в возможности использования результатов исследования, а именно
разработанного программного средства, во время процесса обучения студентов в
высших учебных заведениях.
1.АНАЛИТИЧЕСКИЙ ОБЗОР
.1 Общее представление о процессе исполнения
SQL-запросов
На рисунке 1.1 показан порядок обработки
SQL-запроса на сервере.
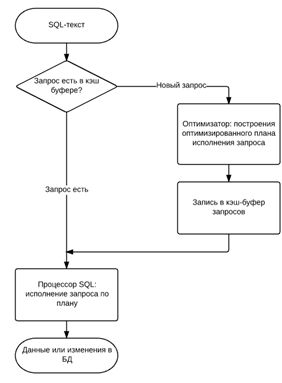
Рисунок 1.1 - Порядок обработки SQL-запроса
.2 Медленные запросы
Бывает ситуации, когда серверу БД не получается ответить на запрос данных в течение короткого времени. Запрос принято считать медленным, если его обработка занимает более 10 секунд.
Для каждого такого запроса будут зафиксированы следующие параметры:
время выполнения запроса - количество времени, которое сервер БД затратил на исполнение запроса;
время блокировок - время, потраченное сервером БД на исполнение запроса, при этом сервер БД бездействовал, так как ожидалось завершение предыдущих либо конфликтующих операций или готовность других объектов;
количество просмотренных строк таблицы - количество строк, которое пришлось прочитать с диска в процессе обработки SQL-запроса;
количество просмотренных строк - количество просмотренных и созданных строк вспомогательных и временных таблиц, которыми пришлось воспользоваться.
При использовании индексов значительно уменьшается количество просмотренных строк таблицы, при наличии нужного индекса для поиска информации сами строки можно не просматривать вообще.
Использование индекса крайне эффективно -
запрос, использующий индексы, исполняется достаточно быстро и без использования
каких-либо ресурсов.
.3 Случайные медленные запросы
Иногда из-за причин случайного характера запрос может выполняться медленно.
запросы INSERT, UPDATE могут выполниться медленно из-за ожидания окончания обработки других запросов или из-за занятости дисковой системы сервера в момент выполнения запроса;
запрос SELECT может случайно выполниться медленно также из-за мгновенной нагрузки на сервере. Признаком такой случайности является однократное повторение явления и небольшое количество строк таблицы.
Поэтому стоит учесть, что случайные медленные
запросы не являются проблемами со стороны скриптов или структуры БД.
1.4 Проблемные запросы
Если была получена информация о том, что исполняющийся запрос, вызывает проблему, значит, медленное выполнение запроса носит системный характер. Медленная скорость исполнения такого запроса объясняется не случайным стечением обстоятельств, а тем, что для выполнения запроса требуется большое количество процессорных или дисковых ресурсов сервера БД.
Проблемным запросом является запрос, выполняющийся долго, потребляя при этом значительные ресурсы дисков и памяти.
Выполнение такого запроса вызывает ощутимое замедление при работе сервера базы данных или других клиентов.
Медленные запросы данного типа можно классифицировать на следующие случаи:
запрос вида - WHERE column=[value], WHERE column>[value], WHERE column<[value], проблема - большое количество просмотренных строк (от 10 до 100 тысяч и более). Это означает, что отсутствует необходимый индекс для поиска по полю или в качестве ответа на запрос возвращается большое количество строк;
запрос вида - WHERE column LIKE ‘%...%’, большое количество просмотренных строк. В процессе исполнения запроса LIKE невозможно использовать индексы, происходит полный перебор данных.
Сложный запрос с использованием нескольких таблиц, огромное количество просмотренных строк (от десяти тысяч и до миллионов). Также в процессе исполнения подобного запроса невозможно использовать индексы или оптимизатор не смог применить индекс для ускорения, поэтому сервер создал временную таблицу с указанным количеством строк.
Также возможны другие разнообразные случаи, которые сложно описать.
Сходство всех описанных выше случаев заключается в том, что для ответа на такие запросы серверу необходимо использовать обращение к диску, общим количеством сравнимое с количеством просмотренных строк и общим объемом сравнимым с количеством данных в таблицах, с которыми ведется работа.
Десятки тысяч обращений к диску и десятки мегабайт считанной информации - это большая нагрузка на сервер, которая неприемлема во многих случаях.
Причины неэффективности SQL-запросов в Oracle
Причины ресурсоемкости запроса могут быть следующие:
плохая статистика по индексам и таблицам запроса;
отсутствие и проблемы с индексами;
проблемы с подсказками в запросе;
проблемы с построением запроса;
некорректно настроенные параметры инициализации БД, отвечающие за производительность.
Существует много различных причин неэффективности запроса, вот некоторые из них:
неэффективное соединение таблиц в запросе;
использование конструкций NOT и NOT IN в WHERE;
блокировка индекса из-за использования некорректных функций к столбцу, по которому был построен индекс;
большая длина или вложенность запроса;
большое количество выбираемых данных, которые требуют подключения в работу дисков, в том числе для выполнения агрегатных функций;
неэффективные хранимые функции или процедуры, используемые в запросе.
План исполнения запроса
При работе с SQL-запросами часто требуется выяснить каким образом выполняется запрос, какие методы доступа применяются оптимизатором запроса Oracle при исполнении SQL-запроса, какие индексы используются и используются ли они вообще.
Для того, чтобы узнать это необходимо построить план исполнения запроса. Посмотрев полученный план исполнения можно понять, что SQL запрос выполняется оптимально или принять меры по настройке SQL-запроса - можно изменить текст самого запроса, создать индексы или выполнить другие действия для настройки SQL-запроса или БД.
Прежде всего в БД должна быть создана специальная таблица PLAN_TABLE, при этом нужно дать привилегии на эту таблицу тому пользователю, который будет просматривать и анализировать планы исполнения SQL-запросов.
Заполнить таблицу PLAN_TABLE можно с помощью команды explain plan for.
Таблица PLAN_TABLE хранит информацию о плане исполнения SQL-запроса. Каждый раз при выполнении команды explain plan for все данные таблицы стираются и формируются новые.
Пример анализа SQL-запроса:PLAN FOR*
FROM T1;
После выполнения команды можно посмотреть результат анализа плана исполнения SQL-запроса. Сделать это можно при помощи простой выборки из таблицы PLAN_TABLE, однако это малоинформативно и достаточно неудобно.
Однако команда EXPLAIN PLAN FOR не учитывает значения связываемых переменных, поэтому если в запросе используются такие переменные, то PLAN_TABLE будет содержать план исполнения, который на самом деле не используется при выполнении запроса.
Существует множество различных инструментов для анализа информации PLAN_TABLE, такие инструменты встроены в Toad, PL/SQL Developer, SQL Navigator и другие, но проблема в том, что эти программы не всегда могут оказаться под рукой, поэтому нужно уметь просматривать результат команды explain plan for в SQL Plus. Для этого существует пакет Oracle dbms_xplan. Для того, чтобы получить форматированный отчет результата команды explain plan for можно выполнить следующий запрос:
SELECT * FROM TABLE(dbms_xplan.display(NULL, NULL, ‘basic’));
Анализ плана исполнения запроса
Основные правила плана выполнения запроса:
план имеет корень - ветвь, которая не имеет родителя;
у потомка может быть только одна родительская ветка, это правило справедливо и для нескольких уровней вложенности.
При просмотре плана исполнения запроса необходимо обратить внимание на следующие показатели, влияющие на эффективность запроса:
сost - стоимость выполнения запроса;сost - процессорная стоимость выполнения;сost - стоимость операций ввода-вывода;space - показатель использования запросом временного пространства.
Чем большее значение имеет первые три показателя, тем менее эффективен запрос.
Ненулевые значения в показателе Temp Space говорят об использовании запросом временного пространства (например, для сортировок или группировок), при этом с большой вероятностью такой запрос неэффективен, следует начинать искать проблемы с анализа строк, в которых стоит Temp Space.
Анализ планов исполнения запросов имеет определенную последовательность действий:
план исполнения просматривают снизу-вверх, в первую очередь обращают внимание на строки, имеющие большие значения сost и CPU cost;
также следует обратить внимание на наличие в плане исполнения полного сканирования таблиц и индексов: FAST FULL SCAN или FULL SCAN для индексов и FULL для таблиц, также для индексов стоит обратить внимание на значение SKIP SCAN. В плане выполнения, полученном из представления v$sql_plan, для выявления наличия полного сканирования индексов или таблиц нужно смотреть столбец Options (Plan_Options для представления v$sql_plan_monitor);
Кроме того, необходимо посмотреть наличие в плане исполнения значения Hash_Join, так как соединение по Hash_Join приводит к соединению таблиц в памяти и, казалось бы, оно более эффективно, чем вложенные соединения Nested Loops. Однако соединение Hash_Join эффективно при наличии таблиц, хотя бы одна из которых помещается в память БД, или при наличии соединения таблиц с низкоселективными индексами. Минусом такого соединения является то, что при нехватке памяти для таблиц будут задействованы диски, которые сильно затормозят работу запроса (в плане исполнения появится показатель Temp Space). Поэтому при наличии высокоселективных индексов стоит посмотреть, а не улучшит ли план выполнения запроса подсказка оптимизатору Use_NL, приводящая к соединению по вложенным циклам Nested Loops. Если план будет оптимальнее, то нужно оставить эту подсказку. В плане исполнения, полученном из представления v$sql_plan, для выявления Hash_Join следует смотреть столбец Operations;
фразы Merge Join Cartesian также являеется проблемой и означает, что между таблицами нет полной связки. Решением этой проблемы может быть добавление недостающей связки, но иногда помогает использование подсказки Ordered.
Также стоит обращать внимание на детализирующие параметры - CPU_time, Elapsed_time, Buffer Gets, Disk Read и Executions.
СPU_TIME покажет процессорное время выполнения запроса, Elapsed_time - общее время выполнения, Buffer Gets и Disk Read - интенсивность использования памяти и дисков, Executions - количество выполнений запроса;
Значение параметра Disk Reads более 250 тысяч означает частое использование дисков, значение Buffer Gets более 10 миллионов на одно выполнение запроса означает интенсивное использование памяти, то есть в данных случаях в запросе имеются проблемы.
Запрос будет неэффективным если значение Elapsed_time значительно превосходит значение CPU_time (скорей всего это связано с событиями ожидания). Указанные параметры можно получить из служебного представления v$sql или v$sql_monitor по уникальному идентификатору запроса sql_id, а если идентификатор неизвестен, то можно использовать уникальные элементы текста запроса. Для поиска этих параметров в долго работающем запросе стоит использовать представление v$sql_monitor, которое в отличие от представления v$sql имеет столбец sid-сессии, позволяющий выявить запросы, выполняющиеся долго в данной сессии, и их идентификатор sql_id.
В реляционной СУБД оптимальным планом выполнения запроса считается такая последовательность использования операторов реляционной алгебры для применения к исходным и промежуточным отношениям, которая для текущего состояния базы данных (её наполнения и структуры) может быть выполнена с минимальным использованием вычислительных ресурсов.
Широкий спектр информации по всем перечисленным параметрам можно получить из такого мощного средства диагностики эффективности запросов, как AWR.
Служебные представления - v$sql, v$sqlarea
Доступ к этим представлениям по умолчанию запрещен, поэтому администратор БД должен предоставить разработчикам полномочие SELECT ANY DICTIONARY, прежде чем они смогут просматривать эту информацию
Представление v$sqlarea содержит статистку разделяемой области SQL, по одной строке для каждой строки SQL. Оно содержит статистику по операторам SQL, которые находятся в памяти, разобраны и готовы для выполнения.
Когда Oracle выполняет запрос, он помещает его в память. Это позволяет Oracle повторно использовать тот же SQL, если это требуется в сеансе, который выполняется позже по дате или другими пользователями, которым может быть нужен один и тот же оператор SQL. Одним из шагов в Oracle является присвоение уникального SQL_HASH_VALUE и SQL_ADDRESS для каждого SQL-оператора. Таблица 1 содержит краткий список столбцов, которые потребуется для анализа SQL.
Запрос к v$sqlаrea - это очень важный запрос,
который может использоваться для оценки производительности системы. Всего один
запрос или индекс могут значительно снизить эффективность всей системы. И
запрос к v$sqlarea, применяемый для того, чтобы определить число обращений к
диску (disk_reads), выполняемых при работе программы (содержимое столбца
sql_text представления v$sqlarea), покажет, где стоит сфокусировать усилия по
оптимизации. (Если текст запроса превышает лимит в 2000 символов, который
установлен для v$sqlarea, то для того, чтобы увидеть полный текст запроса,
возможно потребуется объединить v$sqlarea с представлением v$sqltext).
Таблица 1- Параметры V$SQLAREA.
|
Столбец |
Описание |
|
SQL_TEXT |
Первая тысяча символов текста SQL текущего курсора. |
|
OPTIMIZER_MODE |
Режим, в котором выполнялся данный оператор SQL. |
|
ADDRESS |
Адрес указателя на родителя данного курсора. |
|
HASH_VALUE |
Хеш-значение родительского оператора в библиотечном кэше. |
|
CPU_TIME |
Количество микросекунд процессорного времени, потраченного на обработку SQL. |
|
ELAPSED_TIME |
Время в мс, затраченное на полный цикл выполнения запроса - от получения команды до завершения передачи результатов пользователю. |