Материал: Отчет №1
Министерство науки и высшего образования РФ
Федеральное государственное бюджетное образовательное
учреждение высшего образования
«Уфимский государственный авиационный технический университет»
Факультет информатики и робототехники
Кафедра вычислительной математики и кибернетики
Отчет по лабораторной работе №1
«Генерирование случайных переменных»
по дисциплине
«Компьютерное моделирование»
Выполнил:
студент группы МО-317
Ишпахтин А. А.
Проверила:
Валеева А. Ф.
Уфа 2021
Оглавление
Заключение 9
Задание:
Выбрать для программирования одну непрерывную случайную переменную и одну дискретную. Проверить по критерию согласия К. Пирсона принадлежность исследуемой случайной переменной закону распределения.
Теоретические сведения:
Критерий согласия хи-квадрат К. Пирсона – это статистический критерий о том, что генеральная совокупность имеет распределение предполагаемого типа; позволяет оценить значимость различий между фактическим (выявленным в результате исследования) количеством исходов или качественных характеристик выборки, попадающих в каждую категорию, и теоретическим количеством, которое можно ожидать в изучаемых группах при справедливости
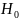 гипотезы.
гипотезы.Метод программирования «сверху вниз» (или «нисходящее» программирование) – это один из двух основных подходов создания программ и алгоритмов, при которой разработка начинается с определения целей решения проблемы, после чего идет последовательная детализация, заканчивающаяся детальной программой. Является противоположной методике программирования «снизу вверх». При нисходящем проектировании задача анализируется с целью определения возможности разбиения ее на ряд подзадач. Затем каждая из полученных подзадач также анализируется для возможного разбиения на подзадачи. Процесс заканчивается, когда подзадачу невозможно или нецелесообразно далее разбивать на подзадачи. В данном случае программа конструируется иерархически - сверху вниз: от главной программы к подпрограммам самого нижнего уровня, причем на каждом уровне используются только простые последовательности инструкций, циклы и условные разветвления.
Ход работы:
Генерирование непрерывной переменной
Выбираем непрерывную случайную величину. Сгенерировать экспоненциальную случайную переменную
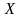 с параметром
с параметром
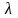 и функцией распределения
и функцией распределения
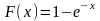 .
Если
.
Если
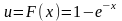 ,
,
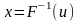 ,
логарифмируя, получим:
,
логарифмируя, получим:
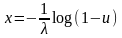
1. Генерировать U ~ Uniform [0, 1]
2. Возвратить
Выдвигаем (нулевую) гипотезу: выбранная случайная переменная X распределена по показательному закону.
Алгоритм (символом ‘#’ обозначим комментарии кода):
Вход: lambd # параметр, вещественное n # количество данных, целое m # количество проводимых опытов, целое
Выход:
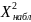 (< ? >)
(< ? >)
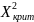
Шаг 1. Ввести входные данные.
Шаг 2. Выполнить m опытов: for i = 0 to m u = random(0, 1) x = -math.log(1 - u) / lambd xs.append(x)
Шаг 3. Вычислить длину интервала:
b = int(max(xs)) + 1 # конец отрезка
step = b / n # вещественное
Шаг 4. Найти вероятность попадания Х в частичные интервалы:
for x in xs:
index = int(x / step)
F[index] += 1
Шаг 5. Вычислить теоретические частоты:
T = [m * P[i] for i in range(n)]
Шаг 6. Считать значение Chi_Square: Chi_Square = 0 # инициализируем, вещественное for i = 1 to n Chi_Square = Chi_Square +
 / T[i]
/ T[i]Шаг 7. Сравнить полученное значение с табличным при вероятности ошибки 0.05 и степенью свободы n – 2: critical_value = (0.05, n – 2) if (Chi_Square < critical_value) output(‘Гипотеза принимается’) else output(‘Гипотеза НЕ принимается’)

import math import random table_values = [0.05, 3.841, 5.991, 7.815, 9.488, 11.070, 12.592, 14.067, 15.507, 16.919, 18.307, 19.675, 21.026, 22.362, 23.685, 24.996] n = 10 # количество данных, целое m = 1000 # количество проводимых опытов, целое lambd = 0.5 # параметр xs = [] # список сгенерированных значений print('Лямбда-параметр:', lambd) for i in range(m): u = random.random() x = -math.log(1 - u) / lambd xs.append(x) b = int(max(xs)) + 1 # конец отрезка step = b / n # длина каждого интервала print('Конец отрезка: ') print(b) print('Длина отрезка: ') print(step) F = [0 for _ in range(n)] # список счетчиков каждого интервала for x in xs: index = int(x / step) # вычисляем индекс интервала F[index] += 1 # увеличиваем счетчик интервала M = [(step * (i + 1) - step / 2) for i in range(n)] _x = sum([M[i] * F[i] for i in range(n)]) / m print('Параметр предпологаемого показательного распределения: ', 1 / _x) P = [math.exp(-lambd * step * i) - math.exp(-lambd * step * (i + 1)) for i in range(n)] T = [m * P[i] for i in range(n)] print('Фактические частоты: ') print(F) print('Теоретические частоты:') print(T) Chi_Square = sum([(F[i] - T[i]) ** 2 / T[i] for i in range(n)]) # хи-квадрат (наблюдаемое значение) critical_value = table_values[n - 2] # табличное критическое значение print(Chi_Square) print(critical_value) print(Chi_Square < critical_value)
Код программы на языке программирования python
Пример работы программы

Проверка работы программы
шаг: 14 / 10 = 1.4
таблица 1(полученное эмпирическое распределение):Интервал
Фактическая частота
0 – 1.4
484
1.4 – 2.8
264
2.8 – 4.2
122
4.2 – 5.6
63
5.6 – 7.0
39
7.0 – 8.4
14
8.4 – 9.8
7
9.8 – 11.2
3
11.2 – 12.6
2
12.6 – 14
2
таблица 2(эмпирическое распределение равноотстоящих вариант):
-
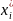
0.7
2.1
3.5
4.9
6.3
7.7
9.1
10.5
11.9
13.3
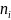
484
264
122
63
39
14
7
3
2
2
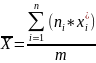 =
|m = 1000, n = 10| = 2.128
=
|m = 1000, n = 10| = 2.128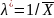 =
0.469924812
=
0.469924812таблица 3 (вычисление )
-
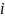
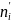
K =
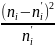
0
484
503.4146962
0.748747367
1
264
249.9883398
0.785343115
2
122
124.1405356
0.036908916
3
63
61.6463656
0.029723181
4
39
30.6126792
2.297974305
5
14
15.2018066
0.095011017
6
7
7.5489937
0.039925067
7
3
3.7487193
0.149539228
8
2
1.8615589
0.010295639
9
2
0.9244228
1.251447188
= 5.444915023
Вывод: = 5.444915023; (0,05; 8) = 15.507; Следовательно, т. к. < – гипотезу принимаем.
Генерирование дискретной переменной
Выбираем дискретную случайную величину

Выдвигаем (нулевую) гипотезу: выбранная случайная переменная X распределена по закону Пуассона.
Алгоритм(символом ‘#’ обозначим комментарии кода):
Вход: lambd(
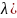 # параметр, вещественное от 0 до 1
n
# количество данных, целое
m
# количество проводимых опытов, целое
# параметр, вещественное от 0 до 1
n
# количество данных, целое
m
# количество проводимых опытов, целоеВыход: (< ? >)
Шаг 1. Ввести входные данные.
Шаг 2. Инициализируем список частот F (список целых чисел): for i = 1 to n F[i] = 0
Шаг 3. Выполнить m опытов: for i = 0 to m u = random(0, 1) i = 0 p =
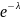 R = p
while (U > R)
p =
p *
R = p
while (U > R)
p =
p *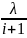 R = R + p
i = i + 1
F[i] = F[i] + 1
R = R + p
i = i + 1
F[i] = F[i] + 1Шаг 4. Задать список теоретических частот Т: for i = 0 to n P[i] =
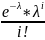 T[i]
= P[i]
* m
T[i]
= P[i]
* mШаг 5. Считать значение Chi_Square: Chi_Square = 0 # инициализируем, вещественное for i = 1 to n Chi_Square = Chi_Square + / T[i]
Шаг 6. Сравнить полученное значение с табличным при вероятности ошибки 0.05 и степенью свободы n – 2: critical_value =
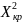 (0.05,
n – 2)
if
(Chi_Square < critical_value)
output(‘Гипотеза
принимается’)
else
output(‘Гипотеза
НЕ принимается’)
(0.05,
n – 2)
if
(Chi_Square < critical_value)
output(‘Гипотеза
принимается’)
else
output(‘Гипотеза
НЕ принимается’)

# генерирование дискретной случайной переменной(Пуассоновский закон) import random import math table_values = [0.05, 3.841, 5.991, 7.815, 9.488, 11.070, 12.592, 14.067, 15.507, 16.919, 18.307, 19.675, 21.026, 22.362, 23.685, 24.996] # 1. ввод входных значений lambd = float(input('Введите лямбду-параметр(0..1): ')) n = int(input('Введите количество данных: ')) m = int(input('Введите количество опытов: ')) # 2. проведение m опытов и подсчет количества полученных значений F = [0 for _ in range(n)] # список счетчиков for _ in range(m): U = random.random() # генерируем случайное число от 0 до 1 i = 0 p = math.exp(-lambd) R = p while(U > R): p *= lambd / (i + 1) R += p i += 1 F[i] += 1 # 3. вычисление теоретических частот P = [math.exp(-lambd) * (lambd ** i) / math.factorial(i) for i in range(n)] # список вероятностей по Пуассону T = [m * P[i] for i in range(n)] # список теоретических частот # 4. проверка по критерию Пирсона Chi_Square = sum([(F[i] - T[i]) ** 2 / T[i] for i in range(n)]) critical_value = table_values[n - 2] # 5. вывод (выходные значения) print(F) print(T) print(Chi_Square) print(critical_value) print(Chi_Square < critical_value)
Код программы на языке программирования pythonПример работы программы

Проверка работы программы