Материал: Не пример курсовой 2021
МИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ
УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ. М.А. БОНЧ-БРУЕВИЧА»
(СПбГУТ)
Факультет Инфокоммуникационных сетей и систем
Кафедра Защищенных систем связи
Дисциплина Безопасность беспроводных локальных сетей
КУРСОВОЙ ПРОЕКТ
Направление/специальность подготовки:
10.03.01 Информационная безопасность
(код и наименование направления/специальности)
Студенты:
%username%
(Ф.И.О., № группы) (подпись)
Преподаватель:
к.т.н., доцент, Ковцур М. М.
(уч. степень, уч. звание, Ф.И.О.) (подпись)
Содержание
Введение 3
Задание 4
Модель сети 5
1. Центральный офис - Санкт-Петербург. 7
2. Филиал - Москва 8
3. Филиал - Нефтеюганск 9
STP Toolkit 10
Состояния портов 10
Роли портов 11
Отказоустойчивость на уровне распределения 14
Порты доступа 18
Протокол OSPF 20
Распределение подсети в филиалах 23
VLAN СПБ 23
VLAN Москва 27
27
VLAN Нефтеюганск 30
Покрытие сетью Wi-Fi. Пример расчёта дизайна беспроводной сети 33
1. Центральный офис - Санкт-Петербург. 33
2. Филиал - Москва 39
3. Филиал - Нефтеюганск 40
1. Радио обследование беспроводной сети 42
Заключение 46
Введение
Беспроводные технологии — подкласс информационных технологий, служат для передачи информации на расстояние между двумя и более точками, не требуя связи их проводами. Для передачи информации может использоваться инфракрасное излучение, радиоволны, оптическое или лазерное излучение.
В курсовом проекте рассматривается проектирование сети необходимого для предприятия с главным офисом и двумя филиалами. В ходе разработки дизайна сети, должное время уделяется аспекту защиты информации от несанкционированного доступа в системе предприятия с использованием программно-аппаратных средств защиты информации.
Курсовой проект содержит классификацию сети фирмы, используемое оборудование, его характеристики. Значимость данного курсового проекта состоит в том, что результаты разработки плана сети предприятия могут стать базой для реального проекта информатизации.
Задание
Компания «SUT LLC» решила открыть офисы в РФ в СПб, Москве, Нефтеюганске, определив СПб местом для размещения головного офиса. Первоначальные данные, полученные от департаментов развития и HR, выглядят следующим образом:
Разработать дизайн корпоративной сети центрального офиса и филиалов:
A. Изобразить структурную схему корпоративной сети головного офиса и филиалов;
B. Пояснить назначение всех функциональных узлов сети;
C. Рассчитать количество точек доступа (ТД) для центрального офиса и каждого филиала;
D. Провести все необходимые настройки в соответствии с ограничениями, представленными IT-департаментом;
Модель сети
Для дизайна сети будем использовать 3 уровневую модель с серверной фермой в Санкт-Петербурге.
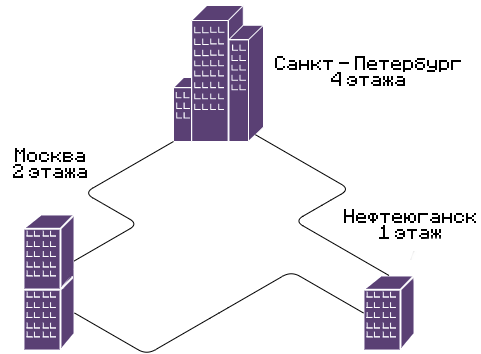
Рисунок 1 Структурная схема расположения зданий
Для дизайна сети используется стандартная трехуровневая модель (рис.2), которая включает в себя 3 уровня: доступ, распределение, ядро. Уровень доступа управляет подключением пользователей и рабочих групп к ресурсам сети. Уровень распределения является связующим звеном между уровнями доступа и ядра. Уровень ядра является основным звеном в данной топологии и отвечает за надежную и быструю передачу больших объемов данных. В случае типичных площадок (филиалов) из-за небольшого числа пользователей в качества ядра используется уровень распределения.
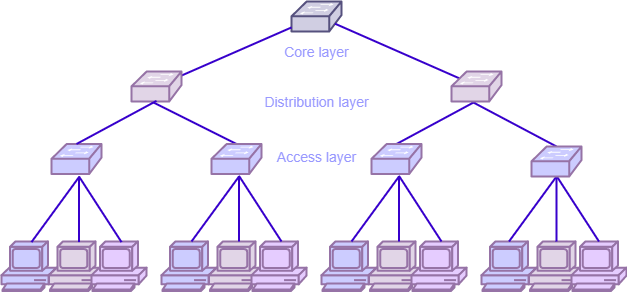
Рисунок 2 Модель сети
Для простоты расчётов итоговую площадь одного этажа берём X м2, тогда площадь всего здания (1 этаж) – X м2.
Согласно стандартам, ILO на одно рабочее место приходится Y м2, таким образом в данном здании будут работать X/ Y = Z человек.
Заданная плотность устройств на человека – D, таким образом всего в здании будут находиться Z * D = N устройства.
Проводные устройства: Z * D[ округляем в меньшую сторону ](компьютер + IP телефон) = 30 устройств +5 принтеров = 35 проводных устройств
Центральный офис - Санкт-Петербург.
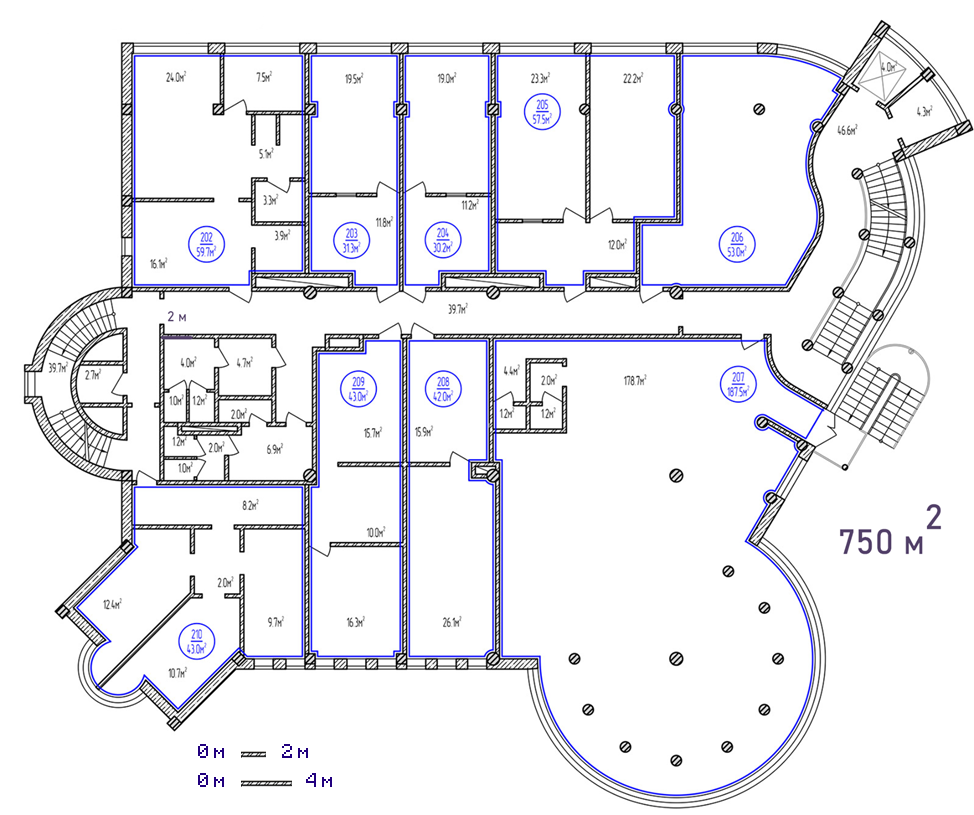
Рисунок 3 Схема офиса в Санкт-Петербурге
Площадь одного этажа =
Филиал - Москва
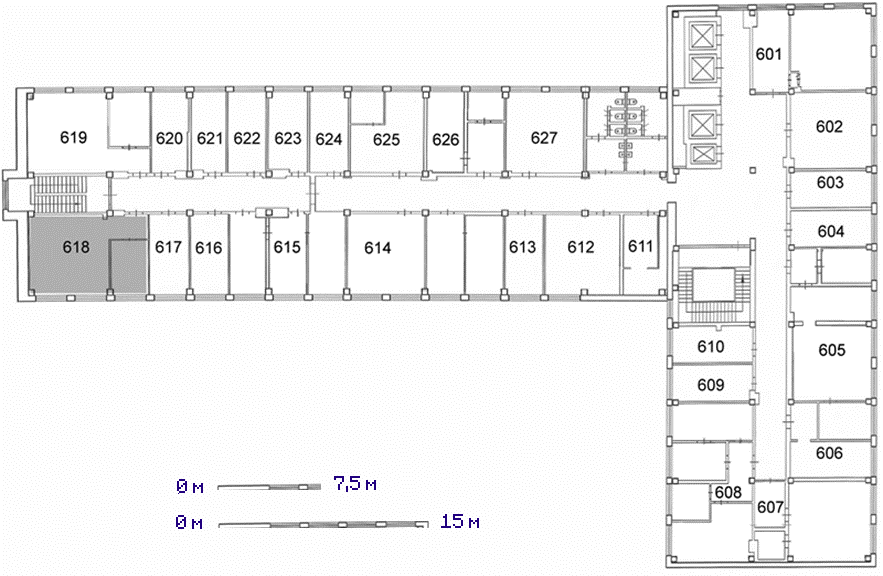
Рисунок 4 Схема офиса в Москве
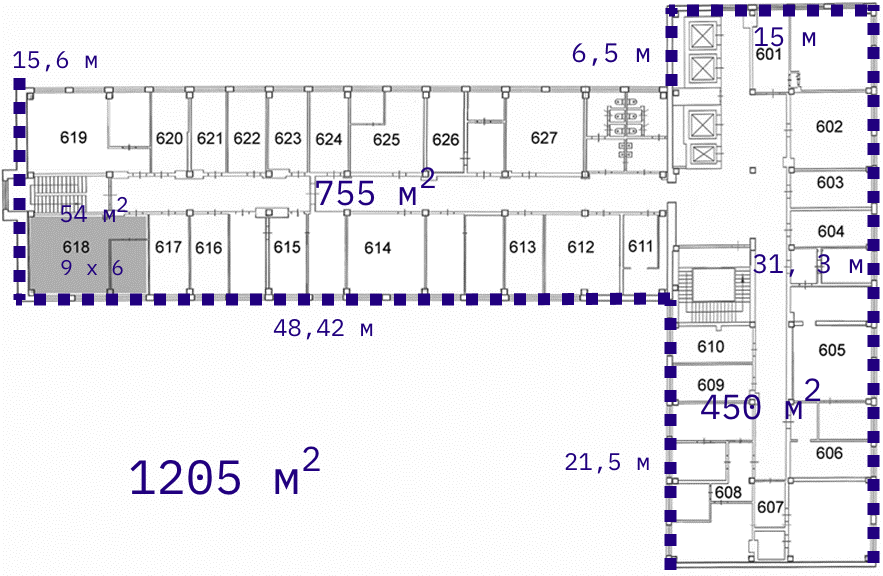
Рисунок 5 Схема офиса в Москве с учётом площади помещений.
Площадь одного этажа =
Филиал - Нефтеюганск
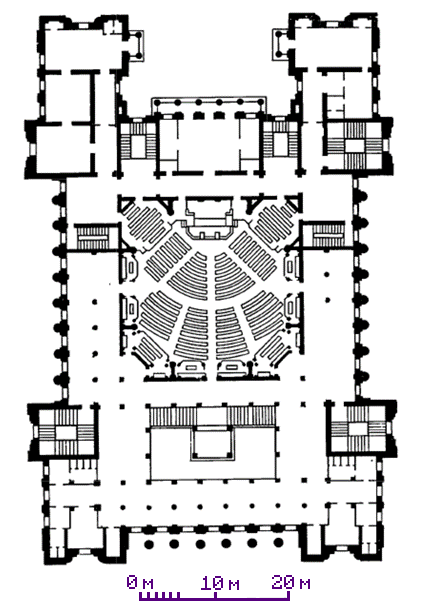
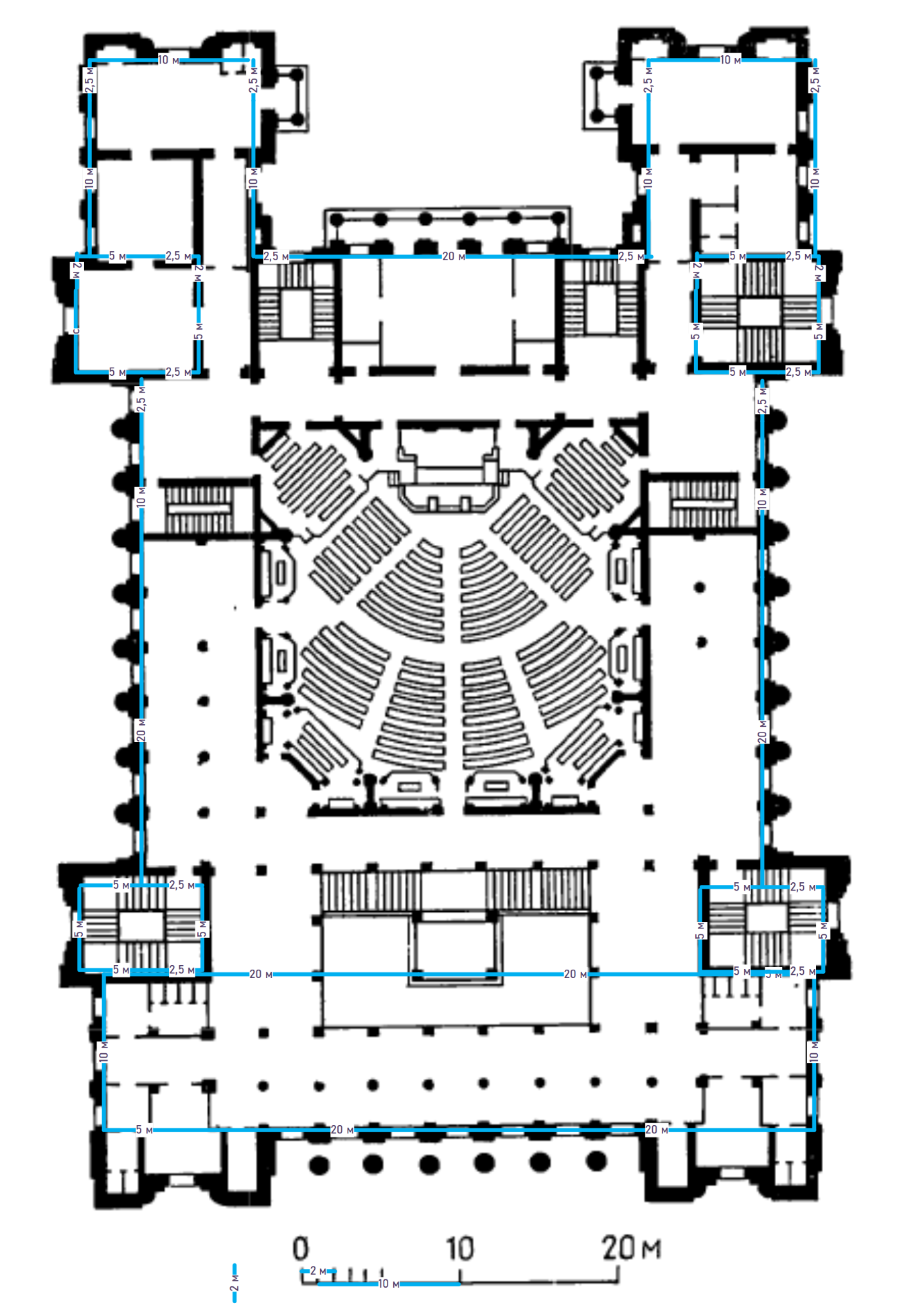
Рисунок 6 Схемы офиса в Нефтеюганске без/с учётом площади помещений.
Площадь этажа =
STP Toolkit
На всех коммутаторах доступа используется STP Toolkit. Требуется выбрать один из протоколов, аргументировать выбор, описать основные настройки и принцип действия.
Принцип работы данного протокола построен на том, что все избыточные каналы между коммутаторами логически блокируются и трафик через них не передается. Для построения топологии без избыточных каналов строится дерево (математический граф). Чтобы построить такое дерево вначале необходимо определить корень дерева, из которого и будет строиться граф. Поэтому первым шагом протокола STP является определение корневого коммутатора (Root Switch). Для определения Root Switch-a, коммутаторы обмениваются сообщениями BPDU. В общем, протокол STP использует два типа сообщений:
BPDU — содержит информацию о коммутаторах;
TCN — уведомляет о изменении топологии.
Для определения корневого коммутатора используется индентификатор коммутатора — Bridge ID. Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768) и MAC-адреса устройства. Корневым коммутатором выбирается коммутатор с самым низким приоритетом, если приоритеты равны, то сравниваются MAC-адреса (посимвольно, тот который меньше, тот побеждает).
Состояния портов
В STP существуют следующие состояния портов:
Blocking — блокирование. В данном состоянии через порт не передаются никакие фреймы. Используются для избежания избыточности топологии.
Listening — прослушивание, до того, пока еще не выбран корневой коммутатор, порты находятся в специальном состоянии, где передаются только BPDU, фреймы с данными не передаются и не принимаются в этом случае. Состояние Listening не переходит в следующее даже, если Root Bridge определен. Данное состояние порта длится в течении Forward delay timer, который, по умолчанию, равен 15. Почему всегда надо ждать 15 секунд? Это вызвано осторожностью протокола STP, чтоб случайно не был выбран некорректный Root Bridge. По истечению данного периода, порт переходит в следующее состояние — Learning.
Learning — обучение. В данном состояние порт слушает и отправляет BPDU, но информацию с данными не отправляет. Отличие данного состояния от Listening в том, что фреймы с данными, который приходят на порт изучаются и информация о MAC-адресах заносится в таблицу MAC-адресов коммутатора. Переход в следующее состояние также занимает Forward delay timer.
Forwarding — пересылка. Это обычное состояние порта, в котором отправляются и пакеты BPDU, и фреймы с обычными данными.
Роли портов
Помимо состояний портов, также в STP нужны определить портам их роли. Это делается для того, чтоб на каком порте должен ожидаться BPDU от корневого коммутатора, а через какие порты передавать копии BPDU, полученных от корневого коммутатора. Роли портов следующие:
Root Port — корневой порт коммутатора. При выборе корневого коммутатора также и определяется корневой порт. Это порт через который подключен корневой коммутатор. Для определения корневого порта в STP используется метрика, которая указывает в поле BPDU — Root Path Cost (стоимость маршрута до корневого свича). Данная стоимость определяется по скорости канала.
Designated Port — назначенный порт сегмента. Для каждого сегмента сети должен быть порт, который отвечает за подключение данного сегмента к сети. Условно говоря, под сегментом сети может подразумеваться кабель, который осуществляет подключение данного сегмента. Также, например, порты на Root Bridge не могут быть заблокированы и все являются назначенными портами сегмента.
Designated Port (назначенный) — некорневой порт моста между сегментами сети, принимающий трафик из соответствующего сегмента. В каждом сегменте сети может быть только один назначенный порт. У корневого коммутатора все порты — назначенные.
Nondesignated Port — неназначенный порт сегмента. Non-designated Port (неназначенный) — порт, не являющийся корневым, или назначенным. Передача фреймов данных через такой порт запрещена. В нашем примере, порт Gi1/0 является неназначенным.
Disabled Port — порт который находится в выключенном состоянии.
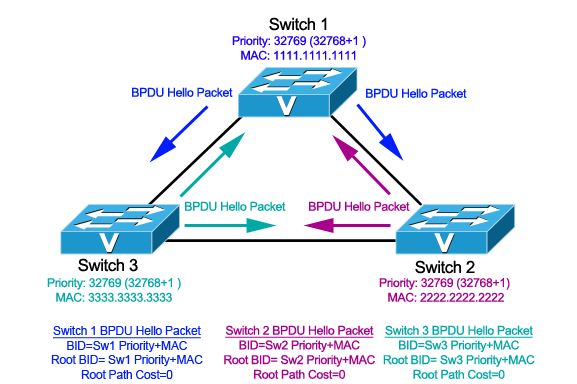
Рисунок 7 Spanning Tree Toolkit
Компания “Cisco Systems” имеет свою проприетарную реализацию протокола STP - PVST (Per-Vlan Spanning Tree) - которая предназначена для работы в сети с несколькими VLAN.
Отказоустойчивость на уровне распределения
Для обеспечения отказоустойчивости необходимо выбрать протокол, применяемый в рамках разрабатываемого решения, будем использовать протокол, предлагаемый вендором из коробки:
GLBP (Gateway Load Balancing Protocol) — проприетарный протокол Cisco, предназначенный для увеличения доступности маршрутизаторов выполняющих роль шлюза по умолчанию и балансировки нагрузки между этими маршрутизаторами.
GLBP обеспечивает балансировку трафика одновременно на несколько роутеров, когда HSRP и VRRP работают только один из 2-ух роутеров.
GLBP обеспечивает распределение нагрузки на несколько маршрутизаторов (шлюзов) используя один виртуальный IP-адрес и несколько виртуальных MAC-адресов. Каждый хост сконфигурирован с одинаковым виртуальным IP-адресом и все маршрутизаторы в виртуальной группе участвуют в передаче пакетов.
Принцип работы:
Члены GLBP группы выбирают один шлюз который будет активным виртуальным шлюзом active virtual gateway (AVG) для этой группы. Другие члены группы обеспечивают резервирование для AVG в случае если AVG станет недоступным. AVG назначает виртуальный MAC адрес для каждого члена GLBP группы. Каждый член группы участвует в передаче пакетов, используя виртуальный MAC адрес, выданный AVG. Этих членов группы называют active virtual forwarders (AVFs). AVG ответственен за выдачу ответов по протоколу Address Resolution Protocol (ARP) на запросы к виртуальному IP-адресу. Распределение нагрузки достигается тем что AVG отвечает на ARP запросы используя разные виртуальные MAC-адреса.
GLBP Gateway Priority определяет роль, которую каждый маршрутизатор AVF играет в группе. Т.е. с помощью этого свойства можно определить последовательность выбора нового AVG, если старый AVG станет недоступным. Приоритет можно определить на каждом маршрутизаторе значением от 1 до 255 командой: glbp priority. Маршрутизатор с большим приоритетом становится AVG.
По умолчанию схема выбора AVG только на основе приоритета выключена. Запасной AVF станет AVG только если текущий AVG станет недоступным. Чтобы разрешить выборы AVG на основе приоритета нужно ввести команду: glbp preempt
GLBP обеспечивает распределение нагрузки на несколько маршрутизаторов (шлюзов) используя один виртуальный IP-адрес и несколько виртуальных MAC-адресов. Каждый хост сконфигурирован с одинаковым виртуальным IP-адресом и все маршрутизаторы в виртуальной группе участвуют в передаче пакетов.
Режимы балансировки нагрузки:
None - режим, при котором коммутатор не обеспечивает балансировку нагрузки. На все запросы клиентов он отвечает своим МАК адресом. Второй коммутатор начинает работу только после того как основной коммутатор (AVG) выйдет из строя или станет недоступным.
Weighted load-balancing - балансировка нагрузки производится в соответствии с весом каждого коммутатора. Вес коммутатора назначается инженером на каждом коммутаторе отдельно. Например если в GLBP группе два коммутатора, у AVG вес 70 а у AVF 140, то нагрузка будет распределяться 1:2. Другими словами из трех полученных запросов на MAC-адрес AVG один раз ответит своим MAC-адресом и дважды MAC-адресом AVF коммутатора.
Host-dependent load-balancing - этот режим используется в случае если есть необходимость в реализации трансляции адресов Network Address Translation (NAT), так как этот режим гарантирует возвращение клиенту того же MAC-адреса AVF коммутатора который он использовал ранее и следовательно NAT сессия у клиента не прерывается. Клиенты будут получать те же MAC-адреса AVF до тех пор, пока количество коммутаторов в GLBP группе не изменится.
Round-robin load-balancing -- режим используется по умолчанию. В этом режиме AVG выдает MAC-адреса AVF попеременно.
Основные настройки:
Включение GLBP на интерфейсе:
glbp <group> ip [ip-address [secondary]]
Включение режима preempt для AVG:
dyn1(config-if)# glbp 1 preempt
Включение режима preempt для AVF: