Материал: Моделирование процесса функционирования вычислительной системы
Концептуальная модель системы разрабатывается для облегчения дальнейшего создания программы имитации её работы, а также для определения целей моделирования.
Входные переменные:
T1 - Время выполнения задачи станком первого типа(30 мин.; экспоненциальное распределение)
T2 - Время выполнения задачи станком второго типа(20 мин.; экспоненциальное распределение)
T3 - Время выполнения задачи станком третьего типа (25мин.; нормальное распределение)
Выходные переменные:
N- кол-во забракованных деталей
K1, K2, K3, K4, K5 - коэффициенты использования станков
P - прибыль цеха
M (назв. очереди) - максимальная длина очереди
A
(назв. очереди) - среднее время пребывания в очереди
4. Разработка структурной схемы модели системы

Рисунок 1 - Q-схема системы
Система включает в себя 4 станка 2-х типов, которые обрабатывают поступающие детали. После первичной обработки деталей, они поступают сначала на накопитель, а затем уже на вторичную обработку 2-мя дополнительными станками.
концептуальный модель массовый обслуживание

Рисунок 2. Блок-схема алгоритма работы системы
5. Разработка программы имитации работы системы
Программа написана с помощью языка GPSS.
generate 40,10
split 2,tt
tt assign 1,2
queue sum_obr
; ищем самую маленькую очередь
t0 test le q$ss11,q$ss12,t1
test le q$ss21,q$ss22,t2
test le q$ss11,q$ss21,next21 ; ss11-минимальная очередь
t4 transfer ,next11
t1 test le q$ss21,q$ss22,t3
test le q$ss12,q$ss21,next21 ; ss12 - минимальная очередь
transfer ,next12
t2 test le q$ss22,q$ss11,t4
t5 transfer ,next22 ; ss22 - минимальная очередь
t3 test le q$ss12,q$ss22,t5
transfer ,next12 ; ss12 - минимальная очередь
;обработка первым станком первого типа
next11 queue ss11
seize stan11
depart ss11
advance(exponential(1,0,30))
release stan11
queue count11
transfer .08,to_nakop,reobr11
;обработка вторым станком первого типа
next12 queue ss12
seize stan12
depart ss12
advance(exponential(2,0,30))
release stan12
queue count12
transfer .08,to_nakop,reobr12
;обработка первым станком второго типа
next21 queue ss21
seize stan21
depart ss21
advance(exponential(1,0,20))
release stan21
queue count21
transfer .1,to_nakop,reobr21
;обработка вторым станком второго типа
next22 queue ss22
seize stan22
advance(exponential(2,0,20))
release stan22
queue count22
transfer .1,to_nakop,reobr22
; цикл для повторной обработки детали
reobr11 loop 1,next11
queue brak
terminate 1
reobr12 loop 1,next12
queue brak
terminate 1
reobr21 loop 1,next21
queue brak
terminate 1
reobr22 loop 1,next22
queue brak
terminate 1
;накопитель
to_nakop queue nakop
;если очередь на выполнение больше 3, обработка выполняется вторым
станком
test le q$nakop,3,met1
;обработка 1м станком
next31 seize stan31
depart nakop
advance(normal(1,25,2))
release stan31
queue count31
transfer ,end1
met1 transfer both next31,next32
;обработка 2м станком
next32 seize stan32
depart nakop
advance(normal(1,25,2))
release stan32
queue count32
transfer ,end1
end1 depart sum_obr
queue obr
terminate 1
start 3000
6. Анализ и оценка результатов моделирования
6.1 Значения требуемых характеристик
Результаты, полученные в процессе моделирования приведены в табл. 1.
Таблица 1
Значения характеристик системы
|
Характеристика |
Значение |
|
Коэффициенты использования станков |
0,124;0,353;0,65;0,749;0,996;0,847 |
|
Количество забракованных деталей |
17 |
|
Среднее время пребывания в очереди ss11, максимальная длина |
14,181 2 |
|
Среднее время пребывания в очереди ss12, максимальная длина |
10,869 2 |
|
Среднее время пребывания в очереди ss21, максимальная длина |
9,190 2 |
|
Среднее время пребывания в очереди ss22, максимальная длина |
12,622 2 |
|
Прибыль цеха |
594311 |
6.2 Исследование характеристик системы
Характеристика «Среднее время нахождения заявки в системе»
Таблица 2

Таблица 3

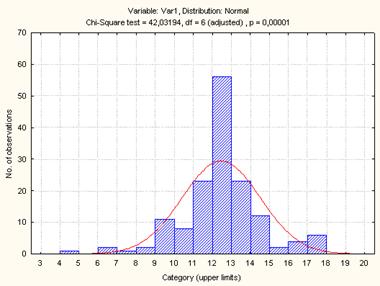
Рисунок 3. Гистограмма распределения среднего времени нахождения заявки в системе
Выдвинутая
гипотеза о том, что закон распределения времени обработки заявок первым станком
является нормальным, отвергается при уровне значимости ![]() , так как p=0,00001<a=0.05.
, так как p=0,00001<a=0.05.
Характеристика «Среднее время обработки запроса станком третьего типа»
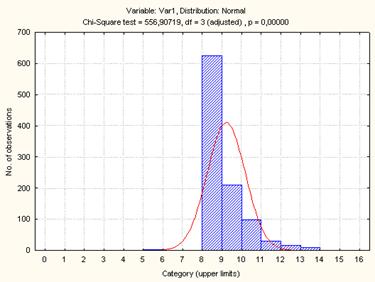
Рисунок 4. Гистограмма распределения среднего времени обработки запроса станком 3-го типа
Выдвинутая
гипотеза о том, что закон распределения времени обработки заявок третьим
станком является нормальным, отвергается при уровне значимости ![]() , так как p=0,00001<a=0.05
, так как p=0,00001<a=0.05
6.3 Анализ эффективности работы системы
Построив имитационную модель системы и проанализировав её работу, можно прийти к следующим выводам.
Система работает не так эффективно, как хотелось бы. Время нахождения заданий в очереди довольно велико. Но сама система для обработки поступающих задач имеет большой потенциал и можно увеличить их интенсивность и частоту в несколько раз, и в целом система может работать и при большей нагрузке.
Оптимизируем существующую систему. В качестве параметра для оптимизации выберем - среднее время пребывания деталей в накопителе
Уровни факторов будут изменяться согласно данным, приведенным в таблице
4.
В табл. 5 приведена матрица планирования для проведения полного факторного эксперимента. Полный факторий эксперимент дает возможность определить коэффициенты регрессии, соответствующие не только линейным эффектам, но и всем эффектам взаимодействий. При проведении эксперимента используют либо исходные значения факторов, либо стандартизованные значения (для удобства). Для перехода к стандартизованным значениям применяют преобразование:
Таблица 4
|
Факторы (обозначение) |
Содержательная интерпретация факторов |
Уровни факторов |
Интервал варьирования, единицы измерения |
||
|
|
|
-1 |
0 |
+1 |
|
|
|
20 |
30 |
40 |
10 |
|
|
|
20 |
25 |
30 |
5 |
|
|
|
25 |
30 |
35 |
5 |
|
Таблица 5
|
№ |
x1 |
x2 |
x3 |
x1*x2 |
x1*x3 |
x2*x3 |
x1*x2*х3 |
y |
|
1 |
20 |
20 |
25 |
400 |
500 |
500 |
10000 |
39,702 |
|
2 |
20 |
20 |
35 |
400 |
700 |
700 |
1400 |
6025.022 |
|
3 |
20 |
30 |
25 |
600 |
500 |
750 |
15000 |
45.040 |
|
4 |
20 |
30 |
35 |
600 |
700 |
1050 |
21000 |
|
|
5 |
40 |
20 |
25 |
800 |
1000 |
500 |
20000 |
47.877 |
|
6 |
40 |
20 |
35 |
800 |
1400 |
700 |
28000 |
5963.850 |
|
7 |
40 |
30 |
25 |
1200 |
1000 |
750 |
30000 |
52.075 |
|
8 |
40 |
30 |
35 |
1200 |
1400 |
1050 |
42000 |
6193.367 |
Рисунок 5. Диаграмма рассеяния для линейной модели (Y(X1)
Рисунок 6. Диаграмма рассеяния для линейной модели (Y(X2)
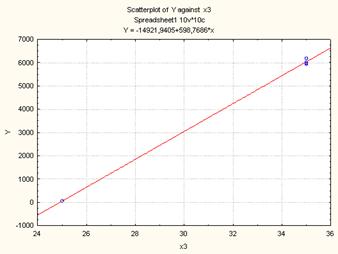
Рисунок 7. Диаграмма рассеяния для линейной модели (Y(X3)
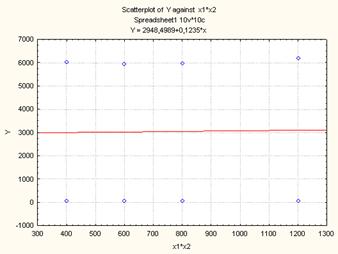
Рисунок 8. Диаграмма рассеяния для линейной модели (Y(X12)
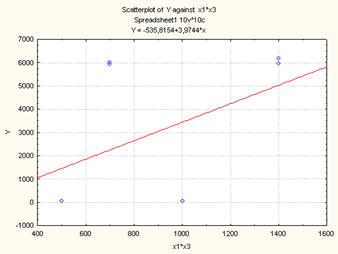
Рисунок 9. Диаграмма рассеяния для линейной модели (Y(X13)
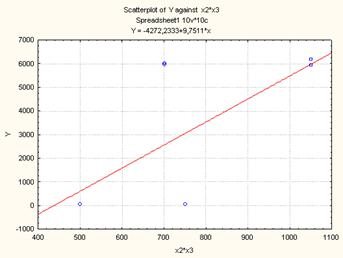
Рисунок 10. Диаграмма рассеяния для линейной модели (Y(X23)
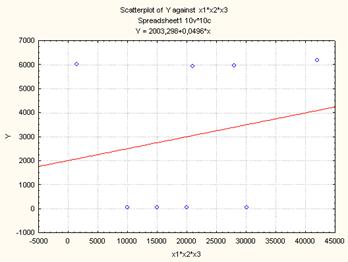
Рисунок 11. Диаграмма рассеяния для линейной модели (Y(Х123)
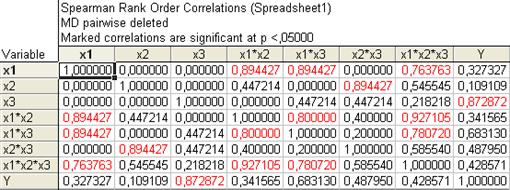
Рисунок 12 . Выборочная корреляционная матрица
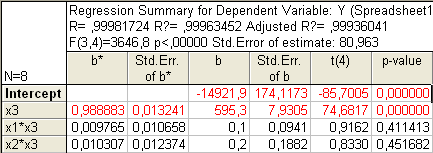
Рисунок 13. Множественная регрессия от х3,x1*x3, x2*x3
Параметрическая идентификация структурной модели зависимости на основе
метода наименьших квадратов (МНК) средствами Statistica.
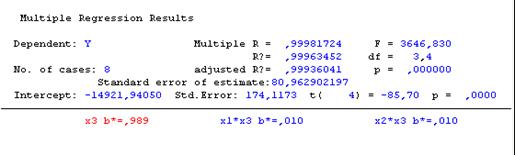
Так как p-значения свободного члена и х3 меньше уровня значимости α=0,05, следовательно, коэффициенты при этих факторах не равны нулю и учитываются при расчете окончательного варианта функционирования. Так как р- значения х13 и х23 больше уровня значимости α=0,05, то коэффициент при этом факторе равен нулю и статистически не учитывается.
Уравнение корреляции:
L=-14921,9+595,3Х3
![]() min
min
25≤Х3≤35
![]()
Оптимальное решение Lmin=39,4
Оптимальные характеристики, рассчитанные аналитически, совпадают с
оптимальными характеристиками, полученными имитационным методом.
1. Результат работы программы в оптимальных условиях
) Характеристика «Среднее время нахождения заявки в системе»
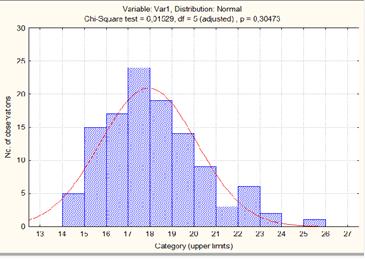
Рисунок 14. Гистограмма распределения времени нахождения заявки в системе
Построив гистограмму по результатам имитационного эксперимента с использованием программных средств Statistica, выдвигаем гипотезу о том, что время нахождения заявки в системе распределяется по нормальному закону. Предполагаем, что эмпирический закон согласуется с теоретическим распределением. Проверим эту гипотезу с помощью статистического критерия согласия Пирсона при заданном уровне значимости α=0,05. p=0,304 > α=0.05 =>гипотеза о согласии теоретического и экспериментального распределения не опровергается при уровне значимости 0,05.
2) Характеристика «Среднее время обработки запроса станком третьего типа»
Рисунок 15. Гистограмма распределения времени обработки заявки станком 3го типа
Выдвигается гипотеза экспоненциальном законе распределения. Проверим эту
гипотезу с помощью статистического критерия согласия Пирсона при заданном уровне
значимости α=0,05.=0,14577 > α=0.05 =>гипотеза о согласии
теоретического и экспериментального распределения не опровергается при уровне
значимости 0,05.
Выводы
В результате проделанной работы было исследовано поведение система массового обслуживания, работающей в реальном времени. Проведя анализ выходных данных, были обнаружены её узкие места, а также была проведена работа по устранению некоторых недостатков. Для этого была проведена процедура по оптимизации модели работы системы, исследованы ее статистические характеристики.
Можно сказать, что данная модель в достаточной мере справляется с выполнением. Но она могла бы функционировать лучше, если станки третьего типа будут обслуживать заявки одновременно, начиная с первых двух поступивших.
2. Верещагин В.В. Учебное пособие по
использованию языка программирования GPSS/PC, 2009.
Приложение А
Листинг программы имитации работы системы на языке моделирования GPSS с исходно заданными
входными переменными и параметрами системы.
generate 40,102,ttassign 1,2sum_obrtest l q$ss11,q$ss12,t1l
q$ss21,q$ss22,t2!l q$ss11,q$ss21,next21transfer ,next11test l q$ss21,q$ss22,t3l
q$ss12,q$ss21,next21,next12test l q$ss22,q$ss11,t4transfer ,next22test l
q$ss12,q$ss22,t5,next12queue
ss11stan11ss11(exponential(1,0,30))Pp1,FR$stan11stan11count11.08,to_nakop,reobr11queue
ss12stan12ss12(exponential(2,0,30))Pp2,FR$stan12stan12count12.08,to_nakop,reobr12queue
ss21stan21ss21(exponential(1,0,20))Pp3,FR$stan21stan21count21.1,to_nakop,reobr21queue
ss22stan22ss22(exponential(2,0,20))Pp4,FR$stan22stan22count22.1,to_nakop,reobr22loop
1,next11brak1loop 1,next12brak1loop 1,next21brak1loop 1,next22brak1_nakop queue
nakople q$nakop,3,met1seize
stan31nakop(normal(1,25,2))Pp5,FR$stan31stan31count31,end1transfer both
next31,next32seize
stan32nakop(normal(1,25,2))Pp6,FR$stan32stan32count32,end1depart
sum_obrobr13000
Приложение Б
Результаты работы программы имитации, соответствующей исходному варианту системы






