Материал: Лекция 6
Лекция 5 помехоустойчивые коды и границы вероятности ошибочного декодирования
5.1 Принципы обнаружения и исправления ошибок
5.2 Классификация помехоустойчивых кодов
5.3 Основные характеристики помехоустойчивых кодов
5.4 Границы вероятности ошибочного декодирования
5.1 Принципы обнаружения и исправления ошибок
В реальных условиях прием двоичных символов всегда происходит с ошибками, когда вместо символа 1 принимается символ 0 и наоборот. Ошибки могут возникать из-за помех, действующих в канале связи (особенно помех импульсного характера), изменения за время передачи характеристик канала (например, замирания), снижения уровня передачи, нестабильности амплитудно- и фазочастотных характеристик канала и т. п.
Общепринятым
критерием оценки качества передачи в
дискретных каналах является нормированная
на знак или символ допустимая вероятность
ошибки для данного вида сообщений. Так,
допустимая вероятность ошибки при
телеграфной связи может составлять
![]() (на знак), а при передаче данных — не
более
(на знак), а при передаче данных — не
более
![]() (на символ). Для обеспечения таких
значений вероятностей одного улучшения
только качественных показателей канала
связи может оказаться недостаточным.
Поэтому основной мерой является
применение специальных методов повышения
качества приема передаваемой информации.
Эти методы можно разбить на две группы.
(на символ). Для обеспечения таких
значений вероятностей одного улучшения
только качественных показателей канала
связи может оказаться недостаточным.
Поэтому основной мерой является
применение специальных методов повышения
качества приема передаваемой информации.
Эти методы можно разбить на две группы.
К первой группе относятся методы увеличения помехоустойчивости приема единичных элементов (символов) дискретной информации, связанные с выбором уровня сигнала, отношения сигнал/помеха (энергетические характеристики), ширины полосы канала, методов приема и т. д.
Ко второй группе относятся методы обнаружения и исправления ошибок, основанные на искусственном введении избыточности в передаваемое сообщение. Наиболее эффективно избыточность используется при применении помехоустойчивых (корректирующих) кодов.
При передаче данных осуществляется объединение отдельных единичных элементов в кодовые комбинации, по которым определяется принятое сообщение. У обычного (не помехоустойчивого) кода для каждой кодовой комбинации во всей совокупности есть другая комбинация, отличающаяся от первой лишь одним разрядом. При искажении одного из разрядов кодовая комбинация превратится в другую, и поэтому принятое сообщение будет выдано с ошибкой.
Помехоустойчивое, или избыточное, кодирование применяется для обнаружения и (или) исправления ошибок, возникающих при передаче по дискретному каналу. Отличительное свойство помехоустойчивого кодирования состоит в том, что избыточность источника, образованного выходом кодера, больше, чем избыточность источника на входе кодера. Помехоустойчивое кодирование используется в различных системах связи, при хранении и передаче данных в сетях ЭВМ, в бытовой и профессиональной аудио- и видеотехнике, основанной на цифровой записи.
При использовании помехоустойчивого кода передаются в канал не все кодовые комбинации, которые можно сформировать из имеющегося числа разрядов, а лишь обладающие определенным свойством, и называемые разрешенными. Другие неиспользованные комбинации называются запрещенными. Введение дополнительных отличных признаков в переданные комбинации позволяет существенно повысить правильность приема. Помехоустойчивые коды подразделяются на коды, которые обнаруживают ошибки, и коды, которые исправляют ошибки.
Для двоичного кода все множество кодовых комбинаций равно N=2n . При использовании кодов, обнаруживающих ошибки, все множество n-разрядных комбинаций разбивается на два непересекающихся подмножества. Одно подмножество называется разрешенной, а другое запрещенной (рис 5.1 а). Эти подмножества известны как на передающей, так и на приемной сторонах. Если в результате искажений передаваемых кодов комбинация перейдет в подмножество запрещенных комбинаций, то ошибка будет обнаружена. Такие коды позволяют только определить наличие ошибок, но не указывающие номер искаженных разрядов.
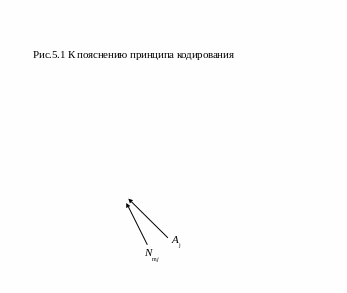
Передаются только разрешенные кодовые комбинации, которые имеют определенное свойство. Если принятая кодовая комбинация относится к разрешенным, то считается, что ошибки нет.
При необходимости исправления некоторых возникающих искажений поступают следующим образом. Все множество кодовых комбинаций N разбивают на Nm<N непересекающихся подмножеств. Каждое из этих подмножеств, приписывается к одной из Nm разрешенных комбинаций (рис 5.1 б). В каждом подмножестве существует одна разрешенная комбинация. Если принятая комбинация Аj входит в подмножество Nmj (AjNoj), то принимается решение, что передана комбинация Aj. То есть, если принятая кодовая комбинация осталась в том же подмножестве, что и передаваемая, то прием будет без ошибки. Если кодовая комбинация в результате искажений переходит в другое подмножество, то прием будет с ошибкой.
Коды, которые не только обнаруживают ошибку, но и указывают номер искаженной позиции, называются кодами с исправлением ошибок.
Как было сказано выше при использовании помехоустойчивого кода в канале связи передаются только разрешенные кодовые комбинации. Если бы не было помех, то для передачи этих кодовых комбинаций потребовалось бы меньшее число разрядов m:
![]() (5.1)
(5.1)
Таким образом, обнаружение и исправление возникающих в каналах связи ошибок достигается за счет введения в передаваемые кодовые комбинации избыточных разрядов.
Рассмотрим возможность обнаружения и исправления ошибок на простейшем примере. Предположим, что информация передается одноразрядным двоичным кодом. То есть передается информация 0 или 1. Число возможных кодовых комбинаций
![]() ,
где
,
где
![]() ,
,![]() .
.
В каждой кодовой комбинации добавим еще один разряд:
![]() .
.
Число кодовых комбинаций
![]() .
.
Эти комбинации составляют множество, состоящее из:
00, 01, 10, 11.
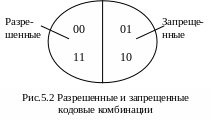
Это множество разделим на два подмножества разрешенных и запрещенных комбинаций. К числу разрешенных отнесем те комбинации, у которых сумма единиц или нулей всегда четная – это комбинации:
00 и 11.
При таком выделении разрешенных комбинаций любая одиночная (или нечетная) ошибка будет изменять число единиц на нечетное. Принятая кодовая комбинация в этом случае переходит в подмножество запрещенных и ошибка будет обнаружена (рис. 5.2).
5.2 Классификация помехоустойчивых кодов
Первые работы по помехоустойчивым кодам принадлежат Хэммингу. В настоящее время разработано большое количество помехоустойчивых кодов. Все эти коды подразделяются на блочные и непрерывные (рис. 5.5).
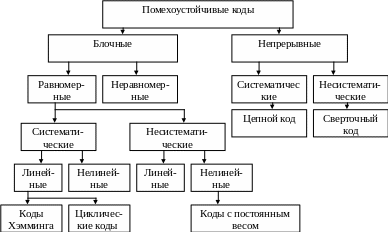
Рис.5.5 Классификация помехоустойчивых кодов
К блочным, относятся коды, в которых каждому сообщению относится в однозначное соответствие блок из n символов. Непрерывные коды представляют непрерывную последовательность информационных и проверочных разрядов. Блочные коды разделяются на равномерные и неравномерные. Равномерные коды имеют постоянную длину кодовой комбинации. Блочные и непрерывные коды разделяются на систематические и несистематические. Под систематическим понимают код, в котором разряды могут быть разделены на проверочные и информационные. При этом их места в кодовой комбинации точно определены. Обычно в систематическом коде каждое кодовое слово начинается с информационных символов и заканчивается проверочными символами. Несистематические коды этим свойством не обладают.
Кроме того, коды разделяются на линейные и нелинейные.
Линейными кодами являются такие, в которых сумма по модулю 2 двух разрешенных комбинаций дает разрешенную комбинацию того же кода. Нелинейные коды отмеченным свойством не обладают. Для линейного кода применяется обозначение (n, m) код, где n – число всех разрядов в кодовой комбинации; m – число информационных разрядов.
Большинство кодов, применяемых на практике, относится к линейным.
5.3 Основные характеристики помехоустойчивых кодов
В настоящее время наибольшее внимание с точки зрения технических приложений уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов цифровая информация передается в виде отдельных кодовых комбинаций (блоков) одинаковой длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым (систематическим) кодам, кодовые комбинации которых состоят из двух частей: информационной и проверочной. При общем числе п символов в блоке число информационных символов равно т, а число проверочных символов
![]() .
(5.3)
.
(5.3)
К основным характеристикам корректирующих кодов относятся:
число разрешенных и запрещенных кодовых комбинаций;
избыточность кода;
минимальное кодовое расстояние;
число обнаруживаемых или исправляемых ошибок;
корректирующие возможности кодов.
Число разрешенных и запрещенных кодовых комбинаций
Для блочных двоичных
кодов, с количеством символов в блоках,
равным
![]() ,
общее число
возможных кодовых комбинаций
определяется
значением
,
общее число
возможных кодовых комбинаций
определяется
значением
![]() .
(5.4)
.
(5.4)
Если в кодовую комбинацию ввести количество дополнительных разрядов, то можно не только обнаруживать, но и исправлять ошибки. Если разрешенные комбинации определить таким образом, что любые из них отличаются друг от друга не менее чем тремя разрядами, то одиночная ошибка может быть исправлена. Возможность исправления одиночной ошибки в этом случае связана с тем, что ошибочная комбинация будет отличаться от истинной только одним разрядом, и останется в области, относящейся к передаваемой разрешенной комбинации.
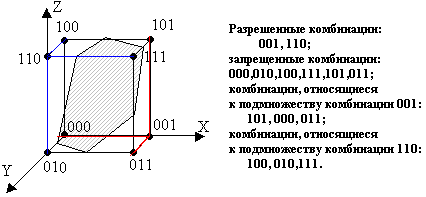
Рис. 5.3. Геометрическая модель помехоустойчивого кода
Рассмотрим сказанное на геометрической модели трехразрядного двоичного кода, при помощи которого можно получить 23=8 комбинаций. А именно: 000, 001, 010, 011, 100, 101, 110, 111. Каждую новую комбинацию можно представить точкой в трехмерном пространстве (рис. 5.3).
Для исправления одиночной ошибки разобьем все множества комбинаций на две области, и будем передавать только две кодовые комбинации 110 и 001. Эти комбинации отличаются друг от друга тремя разрядами. Любая одиночная ошибка оставляет кодовую комбинацию в области, относящейся к передаваемой комбинации. Так, при искажении одного разряда в комбинации 001 она превратится в 000, или в 100, или в 101. Все эти комбинации находятся в той же области, что и комбинация 001.
Рассмотренные примеры показывают, что для обнаружения одиночных ошибок кодовые комбинации должны различаться не менее чем двумя разрядами. Для исправления одиночной ошибки кодовые комбинации должны различаться не менее чем тремя разрядами.
Э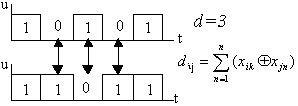 то
различие именуют кодовым
(Хэминговым) расстоянием.
Под кодовым
расстоянием
понимают
минимальное
число позиций, на которых символы данной
кодовой комбинации отличаются от
символов другой кодовой комбинации.
Например, для показанных на рисунке
5.4, кодовое расстояние d
равно 3.
то
различие именуют кодовым
(Хэминговым) расстоянием.
Под кодовым
расстоянием
понимают
минимальное
число позиций, на которых символы данной
кодовой комбинации отличаются от
символов другой кодовой комбинации.
Например, для показанных на рисунке
5.4, кодовое расстояние d
равно 3.
Рис. 5.4. Кодовое расстояние между двумя кодовыми комбинациями
Поэтому можно сказать, что возможности по обнаружению или исправлению ошибок определяются числом позиций, на которых отличаются разрешенные кодовые комбинации, то есть кодовым расстоянием.
Кодовое расстояние
между i-ю
и j-ю
кодовыми комбинациями
![]() определяется по формуле
определяется по формуле
![]() ,
(5.2)
,
(5.2)
где
![]() - значение символов
- значение символов
![]() -й
позиции j-й и i-й
кодовых комбинаций, знак
означает суммирование по модулю 2
(правила сложения по модулю 2: (1+1=0;
1+0=0+1=1; 0+0=0).
-й
позиции j-й и i-й
кодовых комбинаций, знак
означает суммирование по модулю 2
(правила сложения по модулю 2: (1+1=0;
1+0=0+1=1; 0+0=0).
Число разрешенных кодовых комбинаций при наличии т информационных разрядов в первичном коде равно
![]() . (5.5)
. (5.5)
Очевидно, что число запрещенных кодовых комбинаций равно
![]() ,
(23.6)
,
(23.6)
а с учетом (5.3) отношение составит
![]() ,
(5.7)
,
(5.7)
где
![]() — число избыточных (проверочных)
разрядов в блочном коде.
— число избыточных (проверочных)
разрядов в блочном коде.
Избыточность корректирующего кода
Избыточностью корректирующего кода называют величину
![]() ,
(5.8)
,
(5.8)
откуда следует
![]() .
(5.9)
.
(5.9)
Эта величина
показывает, какую часть общего числа
символов кодовой комбинации составляют
информационные символы. В теории
кодирования величину
![]() называют
относительной
скоростью кода.
Если
производительность источника
информации равна
называют
относительной
скоростью кода.
Если
производительность источника
информации равна
![]() символов в
секунду, то скорость передачи информации
после кодирования будет составлять
символов в
секунду, то скорость передачи информации
после кодирования будет составлять
![]() (5.10)
(5.10)
поскольку в
закодированной последовательности из
каждых
символов только
![]() являются
информационными.
являются
информационными.
Если в системе связи используются двоичные сигналы (сигналы типа "1" и "0") и каждый единичный элемент несет не более одного бита информации, то между скоростью передачи информации и скоростью модуляции существует соотношение
![]() ,
,
где
![]() - скорость передачи информации, бит/с;
B
- скорость модуляции, Бод.
- скорость передачи информации, бит/с;
B
- скорость модуляции, Бод.
C точки зрения внесения постоянной избыточности в кодовую комбинацию выгодно выбирать длинные кодовые комбинации, так как с увеличением n относительная пропускная способность
![]() .
.