Материал: Корреляционные зависимости в физическом эксперименте
Корреляционные зависимости в физическом эксперименте
Реферат
Корреляционные
зависимости в физическом эксперименте
Введение
математический статистика корреляционный
Современные научные исследования и производственная практика требуют широкого применения математической статистики для анализа закономерностей массовых явлений во всех отраслях промышленности.
Предметом настоящей реферативной работы является относительно простой и, тем не менее, достаточно эффективный метод, известный как корреляционный анализ. В настоящее время наряду с другими элементами статистического анализа физических процессов он успешно используется для решения задач исследования закономерностей процессов в широких интервалах изменения параметров, поиска оптимальных технологических режимов и конструктивных элементов оборудования, а также различных задач оптимального автоматического управления и регулирования.
В связи со стремительным развитием электронно-вычислительной техники и соответствующего программного обеспечения инструментарий анализа корреляций становится ещё более простым в использовании и доступным для исследователя.
В данной реферативной работе
· приводятся основные теоретические выкладки корреляционного анализа
· рассматривается применение его
инструментария в контексте металлургической промышленности с использованием
программного средства Statistica
6.
1. Постановка задачи
При анализе физических процессов часто
приходится решать задачи о степени связи, а также выражать в математической
форме зависимость между двумя или более переменными.
.1 Эмпирические данные
Величины, между которыми устанавливается связь, (количественные характеристики изучаемого явления) являются результатами наблюдений (регистрации) и называются эмпирическими данными.
Эмпирические данные содержат ошибки и случайные колебания, обусловленные множеством неучтённых факторов, которые чаще всего входят аддитивно (добавляются к истинным значениям или вычитаются из них). Так или иначе данные можно рассматривать как сумму регулярной (детерминированной) и случайной составляющих, которые явно не выделены.
. Регулярная составляющая эмпирических данных является его закономерной частью, которая отражает сущность изучаемого явления (его истинную величину).
Регулярная составляющая однозначно определяется учитываемыми причинно-следственными связями с другими величинами, и остаётся неизменной при независимых повторных измерениях эмпирического значения.
В связи с этим методика наблюдений часто предусматривает независимые многократные измерения. При этом в используемом среднем значении уменьшается доля случайного, возрастает доля и надёжность регулярной части.
. Случайная составляющая эмпирических данных складывается из случайных отклонений от регулярной составляющей. Случайные отклонения порождаются множеством неучтённых связей и погрешностями измерений эмпирического значения. Отклонение от истинного значения происходит с определённой вероятностью, то есть данная составляющая является статистически устойчивой и, соответственно, подчиняется некоторому закону распределения. Наиболее часто значения случайной составляющей подчиняются нормальному закону с нулевым математическим ожиданием.
. Эмпирические данные в целом - случайные
величины. Закон их статистического распределения в целом определяется случайной
составляющей - чаще всего нормальный, но с математическим ожиданием, равным
среднему значению регулярной составляющей, и дисперсией, складывающейся из
дисперсий регулярной и случайной составляющих.
.2 Стохастическая эмпирическая зависимость
Зависимость между случайными величинами называется стохастической зависимостью. Она проявляется в изменении закона распределения одной из них (зависимой переменной) при изменении других (аргументов).
Графически стохастическая эмпирическая зависимость, в системе координат зависимая переменная - аргументы, представляет собой множество случайно расположенных точек, которое отражает общую тенденцию поведения зависимой переменной при изменении аргументов.
Стохастическая эмпирическая зависимость от
одного аргумента называется парной зависимостью, если аргументов более одного -
многомерной зависимостью. Пример парной линейной зависимости приведён на рис.
1.([3])
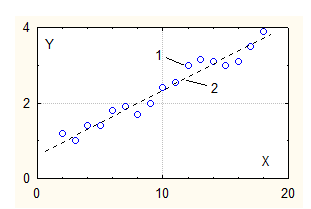
Рис. 1. (1- случайные значения зависимой
переменной, 2 - тенденция поведения зависимой переменной при изменении
аргумента)
В отличие от обычной функциональной зависимости,
в которой изменениям значения аргумента (или нескольких аргументов) отвечает
изменение детерминированной зависимой переменной, в стохастической зависимости
при этом происходит изменение статистического распределения случайной зависимой
переменной, в частности, математического ожидания.
.3 Задача математического моделирования
(аппроксимации)
Построение стохастической зависимости иначе называется математическим моделированием (аппроксимацией) или приближением и состоит в нахождении её математического выражения (формулы).
Эмпирически установленная формула (функция), которая отражает не всегда известную, но объективно существующую истинную зависимость и отвечает основному, устойчивому, повторяющемуся отношению между предметами, явлениями или их свойствами, рассматривается как математическая модель.
Устойчивое отношение вещей и их истинная зависимость. моделируется она или нет, существует объективно, имеет математическое выражение, и рассматривается как закон или его следствие.
Если подходящие закон или следствие из него
известны, то их естественно рассматривать в качестве искомой аналитической
зависимости. Например, эмпирическая зависимость силы тока I
в цепи от напряжения U
и
сопротивления нагрузки R
следует
из закона Ома:
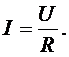 (1.1)
(1.1)
К сожалению, истинная зависимость переменных в подавляющем большинстве случаев априорно неизвестна, поэтому возникает необходимость её обнаружения, исходя из общих соображений и теоретических представлений, то есть построения математической модели рассматриваемой закономерности. При этом учитывается, что заданные переменные и их приращения на фоне случайных колебаний отражают математические свойства искомой истинной зависимости(поведение касательных, экстремумы, корни, асимптоты и т.п.)
Подбираемая, так или иначе, аппроксимирующая функция сглаживает (усредняет) случайные колебания исходных эмпирических значений зависимой переменной и, подавляя тем самым случайную составляющую, является приближением к регулярной составляющей и, стало быть, к искомой истинной зависимости.
Математическая модель эмпирической зависимости имеет теоретическое и практическое значение:
· позволяет установить адекватность экспериментальных данных тому или иному известному закону и выявить новые закономерности;
· решает для зависимой переменной задачи интерполяции внутри заданного интервала значений аргумента и прогнозирования (экстраполяции) за пределами интервала.
Однако, несмотря на большой теоретический
интерес нахождения математической формулы для зависимости величин, на практике
часто достаточно лишь определить, есть ли между ними связь и какова её сила.
.4 Задача корреляционного анализа
Методом изучения взаимосвязи между изменяющимися величинами является корреляционный анализ.
Ключевым понятием корреляционного анализа, описывающим связь между переменными является корреляция (от английского correlation - согласование, связь, взаимосвязь, соотношение, взаимозависимость).
Корреляционный анализ используется для обнаружения стохастической зависимости и оценки её силы (значимости) по величине коэффициентов корреляции и корреляционного отношения.
Если связь между переменными обнаружена, то говорят, что корреляция присутствует или что переменные коррелированны.
Показатели тесноты связи (коэффициент корреляции, корреляционное отношение) по модулю изменяются от 0(при отсутствии связи) до 1(при вырождении стохастической зависимости в функциональную).
Стохастическая связь полагается значимой (реальной), если абсолютная оценка коэффициента корреляции (корреляционного отношения) значима, то есть в 2-3 превышает стандартное отклонение оценки коэффициента.
Отметим, что в некоторых случаях связь может быть обнаружена между явлениями, не находящимися в очевидных причинно-следственных отношениях.
Например, для некоторых сельских районов выявлена прямая стохастическая связь между числом гнездящихся аистов и рождающихся детей. Весенний подсчёт аистов позволяет предсказывать, сколько в этом году родится детей, но зависимость, конечно, не доказывает известное поверье, и объясняется параллельными процессами:
· рождению детей обычно предшествует образование и обустройство новых семей с обзаведением сельскими домами и подворьями;
· расширение возможностей гнездования привлекает птиц и увеличивает их количество.
Подобная корреляция между признаками называется
ложной(мнимой) корреляцией, хотя она может иметь прикладное значение.
2. Общее понятие об оценке реальности связи и её
тесноты
Рассмотрим общий анализ связи на примере
линейной зависимости двух переменных x
и
y.
.1 Случайное рассеяние и неопределённость связи
Причиной случайного рассеяния эмпирических данных является влияние множества неучитываемых факторов и ошибок измерений.
Случайное рассеяние при линейной зависимости проявляется в том, что каждое допустимое значение аргумента x обуславливает не определённую величину зависимой переменной y(x) а множество её случайных значений (точек в системе координат x0y).
Подмножество случайных значений y(x) для каждого x образует статистическое распределение, а для последовательности x - семейство распределений.
Неопределённость стохастической связи в математической статистике понимается как показатель рассеяния (разброса) случайных величин, отсутствия у них общей тенденции.
Графически, в системе декартовых
координат, рассеяние случайных величин отображается множеством точек с общим
центром![]() . Чем
хаотичнее разброс множества точек, чем менее оно подчинено общей тенденции, тем
неопределеннее связь и, соответственно слабее корреляция. По смыслу
неопределённость противоположна понятиям реальности связи и её силы, как
поясняется на рис 2.([3])
. Чем
хаотичнее разброс множества точек, чем менее оно подчинено общей тенденции, тем
неопределеннее связь и, соответственно слабее корреляция. По смыслу
неопределённость противоположна понятиям реальности связи и её силы, как
поясняется на рис 2.([3])
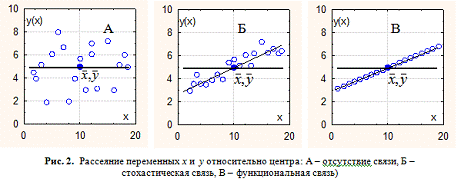
Рис. 2А отвечает рассеянию
переменных x и y
относительно центра ![]() при
отсутствии общей тенденции группирования точек. Здесь нельзя указать линию,
проходящую через центр
при
отсутствии общей тенденции группирования точек. Здесь нельзя указать линию,
проходящую через центр ![]() , которая
отвечает тенденции упорядочения точек, поэтому неопределённость рассеяния
максимальна, корреляция отсутствует, а также задача линейной аппроксимации не
имеет решения.
, которая
отвечает тенденции упорядочения точек, поэтому неопределённость рассеяния
максимальна, корреляция отсутствует, а также задача линейной аппроксимации не
имеет решения.
Рис. 2В отражает противоположный случай, когда нет рассеяния точек - все они подчиняются общей тенденции (принадлежат одной и той же прямой), то есть стохастическая связь вырождается в функциональную, и неопределённость отсутствует.
Рис. 2Б иллюстрирует общий случай
линейной стохастической связи, когда рассеяние точек есть, но оно имеет общую
тенденцию, и точки группируются в области, вытянутой в некотором направлении,
вдоль прямой, проходящей через центр ![]() и отвечающей линейной
стохастической зависимости.
и отвечающей линейной
стохастической зависимости.
Одной из оценок характера связи является коэффициент неопределённости - это доля рассеяния зависимой переменной y относительно модели в общем рассеянии зависимой переменной у.
Иначе, коэффициент неопределённости
- это отношение сумм квадратов:
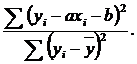 (2.1)
(2.1)
Величину и смысл коэффициента неопределённости можно понять из показанных на рис 2. случаев рассеяния.
При отсутствии связи (рис. 2А)
отсутствует общая тенденция группирования точек. Они оказываются одинаково
рассеянными относительно любой линии, проходящей через центр![]() , в том
числе линии средних значений
, в том
числе линии средних значений ![]() , поэтому коэффициент
неопределённости достигает максимально возможного значения - 1, переменные не
коррелированны.
, поэтому коэффициент
неопределённости достигает максимально возможного значения - 1, переменные не
коррелированны.
Если точки группируются в области,
вытянутой в некотором направлении, вдоль прямой, проходящей через центр ![]() и
отвечающей линейной стохастической зависимости, то рассеяние y
относительно неё меньше, чем относительно среднего значения
и
отвечающей линейной стохастической зависимости, то рассеяние y
относительно неё меньше, чем относительно среднего значения ![]() (рис. 2Б),
и коэффициент неопределённости меньше 1, переменные коррелированны.
(рис. 2Б),
и коэффициент неопределённости меньше 1, переменные коррелированны.
При полном отсутствии
неопределённости (рис. 2В) стохастическая связь вырождается в функциональную
зависимость, поэтому все точки принадлежат модели ![]() , то есть
относительно неё рассеяния y нет, и коэффициент
неопределённости равен 0.
, то есть
относительно неё рассеяния y нет, и коэффициент
неопределённости равен 0.
В качестве показателя тесноты
стохастической связи при решённой, либо решаемой задаче аппроксимации,
используется величина, противоположная коэффициенту неопределённости:
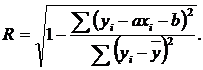 (2.2)
(2.2)
Такая величина называется корреляционным отношением. Она является приближенной оценкой тесноты связи, поскольку, как и коэффициент неопределённости, не учитывает числа степеней свободы у используемых сумм квадратов разностей. Первая из них (в числителе) имеет n - 2 степеней свободы, так как линейная зависимость накладывает две связи, отвечающие двум параметрам a и b. Вторая сумма имеет n - 1 степень свободы, поскольку накладывается одна связь, определяемая средним. В итоге данная оценка оказывается смещённой (несколько завышенной), чем обычно пренебрегают, особенно при большом объёме выборки. Отметим, что программные средства обычно выводят не R, а R2 и её несмещённую величину (Adjusted R2).
Корреляционное отношение R равно 0 при отсутствии связи (рис. 2А), когда коэффициент неопределённости равен 1. При функциональной связи корреляционное отношение максимально и достигает 1. В общем случае корреляционное отношение удовлетворяет неравенству 0 < R < 1.
Отметим возможность применения данной величины
для многомерной и нелинейной зависимости, например, в случае
![]()
выражение для корреляционного
отношения примет вид:
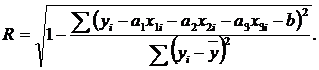 (2.3)
(2.3)
К недостаткам оценки силы связи с помощью корелляционного отношения R следует отнести необходимость предварительного построения модели для определения постоянных, входящих в формулу его вычисления.
В современных пакетах программ,
ориентированных на статистический анализ данных, в том числе Statistica 6, уже
встроена линейная, параболическая, логарифмическая и другие виды аппроксимации,
что позволяет активно использовать корреляционное отношение в качестве оценки
силы связи как при наличии одного, так и нескольких аргументов.
.3 Коэффициент детерминации