Материал: Кэширование данных
Такой кэш имеет самую простую аппаратную реализацию и применяется во вторичном кэше большинства системных плат. Однако ему присущ серьезный недостаток, вполне очевидный при рассмотрении рис. 2. Если в процессе выполнения программы процессору поочередно будут требоваться блоки памяти, смещенные относительно друг друга на величину, кратную размеру страницы (на рисунке это будут блоки, расположенные на одной горизонтали в разных страницах), то кэш будет работать интенсивно, но вхолостую (cache trashing). Очередное обращение будет замещать данные, считанные в предыдущем и потребующиеся в последующем обращении, - то есть будет сплошная череда кэш-промахов. Переключение страниц в многозадачных ОС также снижает количество кэш-попаданий, что отражается на производительности системы. Увеличение размера кэша при сохранении архитектуры прямого отображения даст не очень существенный эффект, поскольку разные задачи будут претендовать на одни и те же строки кэша. Не увеличивая объема, можно повысить эффективность кэширования изменением структуры кэша, о чем пойдет речь далее.
Объем кэшируемой памяти (MCACHED) при архитектуре прямого отображения определяется объемом кэш-памяти (VCACHE) и разрядностью памяти тегов (N):CACHED = VCACHE x 2N, в нашем случае MCACHED = 256 Кбайт х 28 = 64 Мбайт.
Иногда в описании кэша прямого отображения фигурирует понятие набор (set), что может сбить с толку. Оно применяется вместо термина строка (line) в секторированном кэше прямого отображения, а сектор тогда называют строкой.
С набором (как и строкой несекторированного
кэша) связана информация о теге, относящаяся ко всем элементам набора (строкам
или секторам). Кроме того, каждый элемент набора (строка или сектор) имеет
собственный бит действительности в кэш-каталоге (рис. 3).
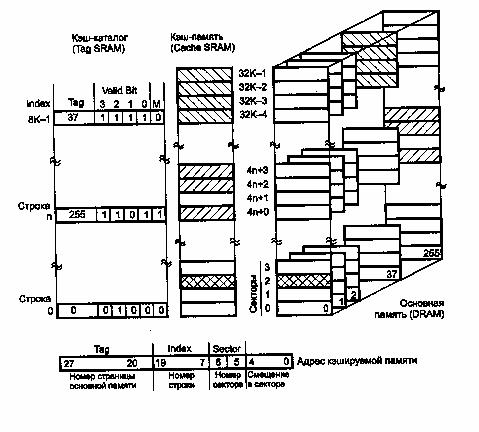
Рис. 3. Секторированный кэш прямого отображения.
2.2 Наборно-ассоциативный кэш
Наборно-ассоциативная архитектура кэша позволяет каждому блоку кэшируемой памяти претендовать на одну из нескольких строк кэша, объединенных в набор (set).
Можно считать, что в этой архитектуре есть несколько параллельно и согласованно работающих каналов прямого отображения, где контроллеру кэша приходится принимать решение о том, в какую из строк набора помещать очередной блок данных.
В простейшем случае каждый блок памяти может
помещаться в одну из двух строк (Two Way SetAssociative Cache). Такой кэш
должен содержать два банка памяти и тегов (рис. 4).
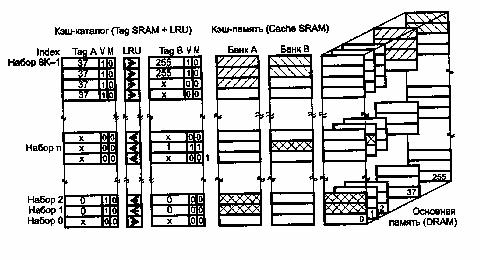
Рис. 4. Двухканальный наборно-ассоциативный кэш.
Номер набора (индекс), в котором может отображаться затребованный блок данных, однозначно определяется средней частью адреса (как номер строки в кэше прямого отображения). Строка набора, отображающая требуемый блок, определяется сравнением тегов (как и в ассоциативном кэше), параллельно выполняемым для всех каналов кэша. Кроме того, с каждым набором должен быть связан признак, определяющий строку набора, подлежащую замещению новым блоком данных в случае кэш-промаха (на рис. 4 в ее сторону указывает стрелка). Кандидатом на замещение обычно выбирается строка, к которой дольше всего не обращались (алгоритм LRU - Least Recently Used). При относительно большом количестве каналов (строк в наборе) прибегают к некоторому упрощению - алгоритм PseudoLRU для четырех строк (Four Way Set Associative Cache) позволяет принимать решения, используя всего 3 бита. Возможно также применение алгоритма замещения FIFO (первым вошел - первым и вышел) или даже случайного (random) замещения, что проще, но менее эффективно.
Наборно-ассоциативная архитектура широко
применяется для первичного кэша современных процессоров. Объем кэшируемой
памяти определяется так же, как и в предыдущем варианте, но здесь будет
фигурировать объем одного банка (а не всего кэша) и разрядность относящихся к
нему ячеек тега.
2.3 Ассоциативный кэш
В отличие от предыдущих у полностью ассоциативного кэша любая его строка может отображать любой блок памяти, что существенно повышает эффективность использования его ограниченного объема. При этом все биты адреса кэшированного блока, за вычетом бит, определяющих положение (смещение) данных в строке, хранятся в памяти тегов. В такой архитектуре для определения наличия затребованных данных в кэш-памяти требуется сравнение со старшей частью адреса тегов всех строк, а не одной или нескольких, как при прямом отображении или наборно-ассоциативной архитектуре. Естественно, последовательный перебор ячеек памяти тегов отпадает - на это может уйти слишком много времени. Остается параллельный анализ всех ячеек, что является сложной аппаратной задачей, которая пока решена только для небольших объемов первичного кэша в некоторых процессорах. Применение полностью ассоциативной архитектуры во вторичном кэше пока не предвидится.
3. Алгоритмы и принцип действия
.1 Алгоритмы замещения данных
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило, для замещения блоков применяются две основных стратегии: случайная (Random) и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным. В таблице показаны различия в долях промахов при использовании алгоритма замещения LRU и случайного алгоритма.
Таблица. Сравнение долей промахов для алгоритма
LRU и случайного алгоритма замещения при нескольких размерах кэша и разных
ассоциативностях при размере блока 16 байт
Размер
кэш-памяти
LRU
Random
LRU
Random Random
16
KB
5.18%
5.69%
4.67%
5.29%
4.39%
4.96%
64
KB
1.88%
2.01%
1.54%
1.66%
1.39%
1.53%
256
KB
1.15%
1.17%
1.13%
1.13%
1.12%
1.12%
3.2 Алгоритмы псевдо-LRU
Алгоритм псевдо-LRU
действует следующим образом. Когда в цикле считывания происходит промах и в
кэш-память необходимо передать из памяти новую строку, приходится выбирать для
заполнения одну из четырех строк множества. Если в множестве есть недостоверная
строка (ее бит достоверности содержит 0), то для заполнения выбирается именно
эта строка. Когда же все строки в множестве достоверны (все 4 бита
достоверности содержат 1), заменяемая строка выбирается с привлечением бит из
блока LRU.
Обозначим строки в множестве через L0,
L1, L2
и L3. Каждому
множеству в блоке LRU
соответствуют три бита В0, В1 и В2, которые модифицируются при каждом попадании
и заполнении следующим образом:
если последнее обращение в паре L0-L1
было к строке L0, то бит В1
устанавливается в состояние 1, а при обращении к строке L1
бит В1 сбрасывается в 0;
если последнее обращение в паре L2-L3
было к строке L2, то бит В2
устанавливается в состояние 1, а при обращении к строке L3
бит В2 сбрасывается в 0. Выбор заменяемой строки (когда все строки в множестве
достоверны) определяет содержимое бит В0, В1 и В2:
Таблица
В0
В1
В2
0
0
X
заменяется
строка L0
0
1
X
заменяется
строка L1
1
X
0
заменяется
строка L2
1
X
1
заменяется
строка L3
Строки кэш-памяти можно по отдельности объявить
недостоверными, задавая операцию недостоверности кэш-памяти на шине процессора.
При инициировании такой операции кэш-память сравнивает объявляемый
недостоверным адрес с тэгами строк, находящихся в кэш-памяти, и сбрасывает бит
достоверности при обнаружении соответствия (равенства). Предусмотрена также
операция очистки кэш-памяти, которая превращает в недостоверное все содержимое
кэш-памяти.
4. Недостатки работы устройства при
кэшировании
вычислительный машина
кэширование
Недостатки рассмотрим на примере трех видов
процессоров: Intel, AMD,
IBM. Большинство
недостатков процессора P-4 являются следствием нововведений, направленных на
достижение высокой производительности - повышенной тактовой частоты и
увеличенной длины конвейера, а также спекулятивного характера многих действий и
оптимизации выполнения «типичных» операций в ущерб «нетипичным». Основными
недостатками являются:
· острая проблема алиасинга при
выборке данных из L1-кэша и, как следствие, значительные потери на реплей (в
первоначальном процессоре P-4);
· половинная частота запуска скалярных
операций SSE;
· неэффективная реализация некоторых
операций сдвига (всех сдвигов в процессоре P-4, сдвигов вправо и циклических в
64-битном режиме в процессоре P-4E);
· высокая латентность инструкций,
работающих с флагом переноса CF (ADC, SBB);
· большая длина конвейера
непредсказанного перехода;
· недостаточная эффективность Т-кэша
для плохо структурированных кодов;
· малый размер L1-кэша и высокая
латентность доступа к L2-кэшу.
Архитектуре процессора K8 (AMD)
имеется и ряд недостатков, часть из которых обусловлена базовыми ограничениями
микроархитектуры:
· статическое разбиение потока МОПов
на группы по 3 элемента с привязкой очередей и функциональных устройств ALU/AGU
к позициям этих элементов;
· слабая система предсказания
переходов, использующая устаревшие алгоритмы;
· недостаточно совершенная аппаратная
предвыборка из памяти;
· отсутствие механизмов
переупорядочения обращений к памяти;
· взаимно эксклюзивная организация
кэшей, ограничивающая скорость выборки из L2-кэша и увеличивающая время
доступа;
· недостаточная ассоциативность
L1-кэшей, снижающая их эффективность.
В микроархитектуре PPC970 к основным
ограничениям и недостаткам можно отнести:
· статическое разбиение потока МОПов
на группы по 4-5 элементов с привязкой очередей и функциональных устройств к
позициям этих элементов;
· наличие множества ограничительных
условий, снижающих число МОПов в формируемой группе (на выходе из декодера);
· недостаточно эффективная реализация
L1-кэшей, имеющих низкий уровень ассоциативности и слишком большой размер
блока;
· завышенное время выполнения
предсказанного перехода (3 такта против 2 тактов у других процессоров); · недостаточная пропускная способность
памяти из-за ограниченной скорости шины.
5. Предложения по повышению
эффективности доступа к данным
В современных процессорах имеются различные
средства, позволяющие повысить эффективность доступа к данным в памяти и
снизить потери на ожидание их прихода, а также прочие задержки и затраты на
организацию этого доступа. Наиболее важными из этих средств являются механизмы
предвыборки из памяти. В каждом из рассматриваемых процессоров реализовано два
таких механизма - программная предвыборка (software prefetch), и автоматическая
аппаратная предвыборка (hardware prefetch).
Наличие машинных инструкций программной
предвыборки позволяет организовать пересылку данных из оперативной памяти в
кэши процессора заблаговременно, с таких расчётом, чтобы ко времени
использования этих данных они уже оказались бы в кэшах. Особенность операции
предвыборки состоит в том, что она лишь инициирует считывание данных из памяти,
после чего считается завершённой. В отличие от обычной операции доступа к
памяти, операция предвыборки не должна ожидать прихода данных в конкретный
регистр, поэтому она не блокирует другие операции в буфере переупорядочения ROB
и может быть отправлена в отставку немедленно. Использование же операции
фиктивной загрузки данных в регистр (с целью ускорения их прихода в кэш)
привело бы к такому блокированию - несмотря на то, что значение, считанное в регистр,
не понадобилось бы никакой другой операции.
Существуют различные варианты инструкций
предвыборки - считывание из памяти в L2-кэш, считывание из памяти или из
L2-кэша в L1-кэш, считывание блока для его последующей модификации, либо для
одноразового использования. В процессоре P-4 реализована предвыборка только в
L2-кэш.
Автоматическая аппаратная предвыборка
представляет собой механизм, который распознаёт последовательные (или иные
регулярные) обращения в память и пытается производить опережающую подкачку
данных. В некоторых процессорах этот механизм умеет работать как в прямом, так
и в обратном направлении (то есть как по возрастанию, так и по убыванию адресов
в памяти) и может распознавать несколько независимых последовательностей
адресов, обеспечивая тем самым предвыборку нескольких потоков данных.
Наиболее совершенные механизмы программной и
аппаратной предвыборки реализованы в новом процессоре P8 (Intel Core).
Ещё один механизм работы с памятью связан с
особенностями загрузки и выгрузки в условиях внеочередного исполнения. В связи
с тем, что операция может считаться корректно выполненной только к моменту
ухода в отставку и не ранее, чем будет отставлены все предшествующие операции,
физическая запись в кэши или в память не может быть произведена до этого
момента. По этой причине все результаты выгрузки (записи) в память
накапливаются в специальном буфере упорядочения обращений к памяти MOB (Memory
Order Buffer). Физическая запись данных из этого буфера в кэш производится
только в момент отставки соответствующей инструкции. Если операция загрузки
(чтения) из памяти адресует элемент данных, который оказался в этом буфере, то
он считывается непосредственно из буфера.
В условиях внеочередного исполнения может
получиться, что операция загрузки окажется готовой к выполнению раньше, чем
выполнится операция выгрузки, записывающая данные в память по тому же адресу.
Также может оказаться, что адрес данных в какой-либо операции выгрузки ещё не
вычислен, и есть риск, что рассматриваемая операция загрузки могла бы обратиться
как раз к этим данным по этому адресу. Чтобы избежать проблем такого рода, в
процессорах обычно реализуют консервативные схемы управления операциями
обращения в память, с запретом на выполнение любых рискованных операций,
которые могли бы привести к чтению некорректных данных. Однако такие
консервативные схемы могут помешать внеочередному исполнению «безопасных»
операций и привести к снижению производительности.
На практике вероятность конфликтов по адресам
такого рода обычно невелика. Поэтому при наличии в процессоре механизма
восстановления в случае выполнения некорректной операции обращения в память
можно было бы отказаться от запрета на выполнение рискованных операций. В
процессоре P8 (Intel Core) такой механизм реализован - он идентичен механизму
восстановления после неправильно предсказанного перехода, когда в момент
отставки инструкции перехода производится окончательная проверка правильности
предсказания.
Помимо механизма восстановления, в процессоре P8
имеется также дополнительный «предсказатель», назначение которого состоит в
снижении вероятности исполнения рискованной операции загрузки из памяти. Если
такой загрузке предшествует операция выгрузки с не вычисленным (на данный
момент) адресом памяти, производится предсказание конфликта по адресам на
основе информации о предыдущем поведении этой операции загрузки. Если
предсказывается отсутствие конфликта, операция загрузки запускается на
выполнение. Если в момент отставки этой инструкции выяснится, что предсказание
было неверным, и произошёл конфликт по адресам с операцией выгрузки, то
операция загрузки будет отменена вместе со всеми последующими операциями, и
будет произведено её повторное выполнение. Описанный механизм получил название
«устранение неоднозначностей в памяти» (Memory Disambiguation).
В заключение рассмотрим ещё один
микроархитектурный механизм, который связан с вычислением адресов для обращений
в память - работу с аппаратным стеком. Адрес вершины аппаратного стека хранится
в регистре ESP. Изменение этого регистра может происходить как неявно, при
помещении или удалении данных из стека (инструкции PUSH и POP) либо при входе
или выходе в подпрограмму (инструкции CALL и RET), так и явно, в обычной
целочисленной инструкции. Традиционно инструкции, использующие регистр ESP и
неявно изменяющие его, преобразовывались декодером в два МОПа, один из которых
производил содержательное действие, а другой - выполнял операцию сложения или
вычитания для регистра ESP.
В процессорах P-M, P-M2 и P8 введён специальный
механизм под названием «Dedicated Stack Engine». Этот механизм отслеживает (на
этапе декодирования инструкций) текущее положение вершины стека и заменяет в
порождаемых МОПах адресацию данных по «меняющемуся» регистру ESP на сумму
некоторого «постоянного» базового адреса стека и отслеживаемого смещения. Таким
образом, отпадает необходимость постоянно модифицировать регистр ESP - теперь
его нужно вычислять только в случае явного использования в качестве операнда
или индекса. Благодаря этому исчезают ненужные зависимости между операциями по этому
регистру, снижается число МОПов в указанных инструкциях (с двух до одного),
повышается эффективность работы декодера и увеличивается общая
производительность процессора.
Список используемой
литературы
вычислительный машина
кэширование
1.
Гук
М., Аппаратные средства IBM PC, Энциклопедия - СПб: ПитерКом, 1999. - 816с.:
ил.
2.
Э.Танненбаум,Современные
операционные системы, СПб: Питер, 2002. - 1024 с.
3.
Григорьев
В.А., Микропроцессор i486.
Архитектура и программирование (в 4-х книгах). Книга 2. Внутрення архитектура
М., Гранал, 1993. - с. 382, ил. 54.
4.
Марголис
А., Поиск и устранение неисправностей в персональных компьютерах. - К.:
«Диалектика», 1994. - 368с., ил.
5.
Конспект
лекций.
6.
Петровский
И.И., Прибыльский А.В., Логические ИС КР1533, КР1554. Справочник. Часть 2.
«Бином», 1993.
7.
Шульгин
О.А. и др., Справочник по цифровым логическим микросхемам, Часть 1 и 2, М.:
ИДДК, 1998.