Материал: Картографирование при помощи монокулярной камеры
Ft: Модель перехода состояния.
Ht: Модель наблюдения.
Qt: Ковариация шума процесса.
Rt: Ковариация шума наблюдения.
Фильтр Кальмана предполагает, что фактическое состояние xt развивается в (t-1) с помощью уравнений 2.5:
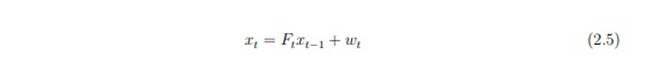
Ft является моделью перехода состояния, который применяется к предыдущему состоянию xt-1 и wt шум процесса с ковариацией Qt.
Кроме
того, предполагается, что ZT-наблюдение в итерации t фактического состояния xt
выполняется в соответствии с формулой 2.6: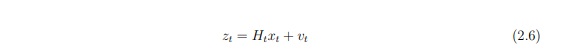
где Ht - модель наблюдения, которая преобразует пространство состояния в пространство наблюдения, в то время как vt представляет шум наблюдения с Ковариацией Rt. KF является рекурсивным оценщиком, то есть используется только для оценки состояния предыдущей итерации и текущего наблюдения, независимо от предыдущего состояния.
Вектор состояния xt следует Гауссовскому распределению Nˆxt с массивом ковариация P. В свою очередь, вектор наблюдения, который имеет ковариационную матрицу S.
Оценка
состояния на каждой итерации выполняется в два этапа: первый шаг известен как
" предсказание” и отвечает за предсказание состояния и его ковариации, в
то время как второй шаг известен как "обновление", где используется
наблюдение для уточнения расчетного состояния.
2.2 Модель Маркова
Модели Маркова являются вероятностными алгоритмами, которые сохраняют дискретное рабочее пространство FDP со всеми возможными решениями. Это стохастический процесс, в котором только следующее состояние XT + 1 зависит от текущего состояния Xt. Это достигается тем, что система не имеет памяти, как это было достигнуто в Xt (формула 2.7):
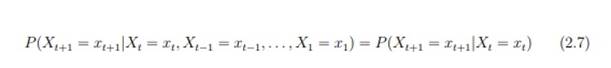
2.1.1 Марковское Местонахождение
Для оценки местоположения робота в среде с использованием моделей Маркова. Он делит мир на сетку с ячейками с каждой из возможных позиций робота, где каждая ячейка(i, j) имеет связанную вероятность P (i, j), представляющую вероятность того, что робот находится в этом положении, а сумма вероятности всех ячеек равны 1 (Рис.2.3).
Если нет априорной информации о местонахождении робота, они инициализируются с помощью равномерного распределения. Чтобы обновить значение каждой ячейки, Марковская локализация использует как информация, предоставляемая датчиками как модель движения робота, полученная через его одометрию.
Основные преимущества Марковской локализации-это то, что она позволяет оснастить систему с априорной информацией, инициализирующей ячейки неравномерно, и наоборот: из того, что происходит с фильтрами Кальмана, система может перестроиться. Однако, самой большой проблемой этих методов является их низкая временная эффективность, так как время выполнение увеличивается пропорционально количеству решений проблемы.
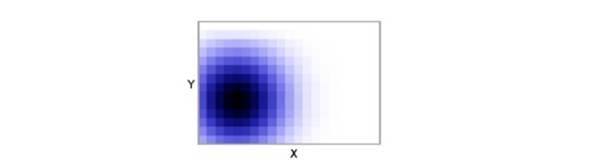
Рис 2.3: двухмерная вероятностная сетка для
оценки положения робота.4
2.2 Метод Монте Карло
Методы Монте-Карло- вероятностные алгоритмы, использующие случайность для поиска оптимального решения эффективно, представляя FDP в режиме выборки. Алгоритмы Монте-Карло работают итеративно и должны иметь два основных механизма:
-Вероятностная модель наблюдения: механизм, используемый для оценки каждой части, что приводит к вероятности от 0 до 1.
-Передискретизация:
процедура, в которой сгенерированы фрагменты следующей итерации учитывая его
вероятность.
2.1.1 Использование метода
Алгоритм используется для определения местонахождения робота. Для того чтобы вычислить количество частей, которые распределяются случайным образом, сначала необходимо вычислить среднюю вероятность нахождения частей, используя уравнивание 2.8:
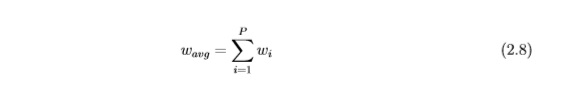
поскольку вероятность каждой части вычисляется с помощью функции стоимости. С помощью значения веса обновляются на каждой итерации. Эти веса изначально стоят 0 и изменяют их значение с помощью уравнений 2.9 и 2.10:
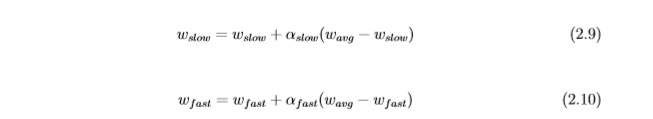
количество PA частей, распределяются случайным образом в итерацию, дается уравнением 2.11:
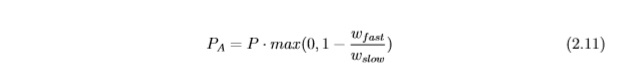
3. Алгоритмы SLAM. Поиск детекторов и дескрипторов
3.1 Поиск детекторов
3.1.1 Алгоритм FAST
FAST, впервые предложенный в 2005 году , был одним из первых эвристических методов поиска особых точек, который завоевал большую популярность из-за своей вычислительной эффективности. В этом методе рассматривается яркость пикселей на окружности с центром в точке С и радиусом 3 (Рис.3.1)[21;5]

Рис. 3.1: Рассматриваемая окрестность точки FAST детектора
Сравнивая яркости пикселей
окружности с яркостью центра C, получаем для каждого три возможных исхода
(светлее, темнее, похоже). Формула (12)
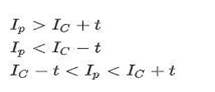
( 12)
Где, I – яркость пикселей, t – некоторый заранее фиксированный порог по яркости.
Точка помечается как особая, если на круге существует подряд n=12 пикселей, которые темнее, или 12 пикселей, которые светлее, чем центр.
Как показала практика, в среднем для принятия решения нужно было проверить около 9 точек. Для того чтобы ускорить процесс, авторы предложили сначала проверить только четыре пикселя под номерами: 1, 5, 9, 13. Если среди них есть 3 пикселя светлее или темнее, то выполняется полная проверка по 16 точкам, иначе – точка сразу помечается как «не особая». Это сильно сокращает время работы, для принятия решения в среднем достаточно опросить всего лишь около 4 точек окружности.
У оригинального FAST есть следующие недостатки:
·
Несколько рядом расположенных пикселей могут быть помечены как
особые точки. Нужна какая-то мера «силы» особенности.
·
Быстрый 4-точечный тест не обобщается для n меньше 12. Так,
например, визуально наилучшие результаты метода достигаются при n=9, а не 12.
3.1.2Детектор
Моравеца
Одним из наиболее распространенных типов особых точек являются углы на изображении, т.к. в отличие от ребер углы на паре изображений можно однозначно сопоставить.
Входом локальных детекторов является черно-белое изображение. На выходе формируется матрица с элементами, значения которых определяют степень правдоподобности нахождения угла в соответствующих пикселях изображения.
Далее выполняется отсечение пикселей со степенью правдоподобности, меньшей некоторого порога. Для оставшихся точек принимается, что они являются особыми.
Детектор Моравеца является самым простым детектором углов. Автор данного детектора предлагает измерять изменение интенсивности пикселя (x;y) посредством смещения небольшого квадратного окна на один пиксель в каждом из восьми принципиальных направлений (2 горизонтальных, 2 вертикальных и 4 диагональных). Размер окна обычно выбирается равным: 3 на 3 , 5 на 5 или 9 на 9 пикселей. Детектор работает в несколько шагов[21;5]:
1. Для
каждого направления смещения (13):
![]()
(13)
вычисляется изменение
интенсивности (14):
![]()
(14)
где
![]() – интенсивность
пикселя с координатами
– интенсивность
пикселя с координатами ![]() в
исходном изображении.
в
исходном изображении.
2.
Строится
карта вероятности нахождения углов в каждом пикселе изображения посредством
вычисления оценочной функции (15)
![]() (15)
(15)
Определяется
направление, которому соответствует наименьшее изменение интенсивности, т.к.
угол должен иметь смежные ребра.
3. Отсекаются пиксели, в которых значения оценочной функции ниже некоторого порогового значения.
4. Удаляются повторяющиеся углы с помощью процедуры NMS (non-maximal suppression). Все полученные ненулевые элементы карты соответствуют углам на изображении.
Основными
недостатками рассматриваемого детектора являются отсутствие инвариантности к
преобразованию "поворот" и возникновение ошибок детектирования при
наличии большого количества диагональных ребер. Очевидно, что детектор Моравеца
обладает свойством анизотропии в 8 принципиальных направлениях смещения окна.
3.1.3 Детектор MSER's
При разработке детектора MSER решается проблема инвариантности особых точек при масштабировании изображения. Детектор выделяет множество различных регионов с экстремальными свойствами функции интенсивности внутри региона и на его внешней границе.
Рассмотрим идею алгоритма для случая черно-белого изображения. Представим все возможные отсечения изображения. В результате получим набор бинарных изображений при разных значениях
порога
![]() (пиксель,
интенсивность которого меньше порога считаем черным, в противном случае,
белым). Таким образом, строится пирамида, у которой на начальном уровне,
соответствующем минимальному значению интенсивности, находится белое
изображение, а на последнем уровне, отвечающем максимальному значению
интенсивности, – черное. Если в некоторый момент происходит движение, то на
белом изображении появляются черные пятна, соответствующие локальным минимумам
интенсивности. С увеличением порога пятна начинают разрастаться и сливаться, в конечном
итоге образуя единое черное изображение. Такая пирамида позволяет построить
множество связных компонент, соответствующих белым областям, – регионов с
максимальным значением интенсивности. Если инвертировать бинарные изображения в
пирамиде, то получим набор регионов с минимальным значением интенсивности.
Схема алгоритма состоит из нескольких этапов:
(пиксель,
интенсивность которого меньше порога считаем черным, в противном случае,
белым). Таким образом, строится пирамида, у которой на начальном уровне,
соответствующем минимальному значению интенсивности, находится белое
изображение, а на последнем уровне, отвечающем максимальному значению
интенсивности, – черное. Если в некоторый момент происходит движение, то на
белом изображении появляются черные пятна, соответствующие локальным минимумам
интенсивности. С увеличением порога пятна начинают разрастаться и сливаться, в конечном
итоге образуя единое черное изображение. Такая пирамида позволяет построить
множество связных компонент, соответствующих белым областям, – регионов с
максимальным значением интенсивности. Если инвертировать бинарные изображения в
пирамиде, то получим набор регионов с минимальным значением интенсивности.
Схема алгоритма состоит из нескольких этапов:
1.
Отсортируем
множество всех пикселей изображения в порядке возрастания/убывания
интенсивности. Отметим, что такая сортировка возможна за время,
пропорциональное количеству пикселей.
2.
Построим
пирамиду связных компонент. Для каждого пикселя отсортированного множества
выполним последовательность действий: обновление списка точек, входящих в
состав компоненты;
обновление
областей следующих компонент, в результате чего пиксели предыдущего уровня
будут подмножеством пикселей следующего уровня.
3.
Выполним
для всех компонент поиск локальных минимумов (находим пиксели, которые
присутствуют в данной компоненте, но не входят в состав предыдущих). Набор
локальных минимумов уровня соответствует экстремальному региону на изображении.
3.2 Дескрипторы
3.2.1 Дескриптор SIFT
Для формирования дескриптора SIFT (Scale Invariant Feature Transform) сначала вычисляются значения магнитуды и ориентации градиента в каждом пикселе, принадлежащем окрестности особой точки размером 16 на 16 пикселей. Магнитуды градиентов при этом учитываются с весами, пропорциональными значению функции плотности нормального распределения с математическим ожиданием в рассматриваемой особой точке и стандартным отклонением, равным половине ширины окрестности (веса Гауссова распределения используются для того, чтобы уменьшить влияние на
итоговый дескриптор градиентов, вычисленных в пикселях, находящихся дальше от особой точки)[21;4].
В
каждом
квадрате размером 4 на 4 пикселя вычисляется гистограмма ориентированных
градиентов путем добавления взвешенного значения магнитуды градиента к одному
из 8 бинов гистограммы. Чтобы уменьшить различные "граничные"
эффекты, связанные с отнесением похожих градиентов к разным квадратам (что
может возникнуть вследствие небольшого сдвига расположения особой точки) используется билинейная
интерполяция: значение магнитуды каждого градиента добавляется не только в
гистограмму, соответствующую квадрату, к которому данный пиксель относится, но
и к гистограммам, соответствующим соседним квадратам. При этом значение
магнитуды добавляется с весом, пропорциональным расстоянию от пикселя, в
котором вычислен данный градиент, до центра соответствующего квадрата.
Полученный дескриптор преобразуется, чтобы уменьшить возможные эффекты от изменения освещенности. Изменение контраста изображения (значение интенсивности каждого пикселя умножается на некоторую константу) приводит к такому же изменению в значениях магнитуд градиентов. Поэтому очевидно, что данный эффект может быть нивелирован путем нормализации дескриптора таким образом, чтобы его длина стала равна единице. Изменения яркости изображения (к значению интенсивности каждого пикселя прибавляется некоторая константа) не влияют на значения магнитуд градиентов. Таким образом, SIFT-дескриптор является инвариантным по отношению к аффинным изменениям освещенности. Однако могут возникать и нелинейные изменения в освещенности вследствие, например, различной ориентации источника света по отношению к поверхностям трехмерного объекта.
Данные эффекты могут вызвать большое изменение в отношении магнитуд некоторых градиентов (при этом оказывают незначительное влияние на ориентацию вектора градиента). Чтобы избежать этого, используют отсечение по некоторому порогу (по результатам экспериментов показано, что оптимальным является значение 0.2), которое применяют к компонентам нормализованного дескриптора. После применения порога дескриптор вновь нормализуется. Таким образом, уменьшается значение больших магнитуд градиентов и увеличивается значение распределения ориентаций данных градиентов в окрестности особой точки.
3.2.2Дескриптор GLOH
Дескриптор
GLOH (Gradient location-orientation histogram) является модификацией
SIFT-дескриптора, который построен с целью повышения надежности. По факту
вычисляется SIFT дескриптор, но используется полярная сетка разбиения
окрестности на бины (рис. 3.2): 3 радиальных блока с радиусами 6, 11 и 15
пикселей и 8 секторов. В результате получается вектор, содержащий 272
компоненты, который проецируется в пространство размерности 128 посредством
использования анализа главных компонент (PCA).[20;2]
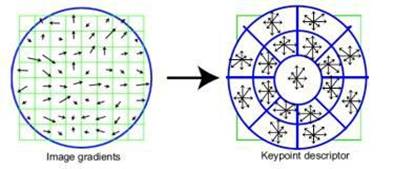
Рис.
3.2:Полярная
сетка разбиения на бины
3.2.3 Дескриптор DAISY
DAISY изначально вводится для решения задачи сопоставления изображений (matching) в случае значительных внешних изменений, т.е. данный дескриптор в отличие от ранее рассмотренных работает на плотном множестве пикселей всего изображения. При этом авторы DAISY в работе показали, что дескриптор работает в 66 раз быстрее, чем SIFT, запущенный на плотном множестве пикселей. В DAISY использованы идеи построения SIFT и GLOH дескрипторов.
Аналогично GLOH выбирается круговая окрестность
особой точки, при этом
бины представляются не частичными секторами, а окружностями (Рис 3.3).[20;1]
Рис.
3.3:
Сетка построения бинов для центрального пикселя
Для каждого такого бина выполняется та же последовательность действий, что и в алгоритме SIFT, но взвешенная сумма магнитуд градиентов заменяется сверткой исходного изображения с производными Гауссова фильтра, взятыми по 8 направлениям. Авторы показали, что построенный дескриптор обладает инвариантностью, как и SIFT, и GLOH, при этом для решения задачи сопоставления (matching) в случае, когда все пиксели считаются особыми, требует меньших вычислительных затрат.