Материал: Исследование методов сортировки выбором
Исследование методов сортировки выбором
Реферат
Программа для сортировки данных методами выбора.
Ключевые слова: СОРТИРОВКА, МЕТОДЫ СОРТИРОВКИ, ВЫБОРКА, ПИРАМИДАЛЬНЫЙ, ПЛАВНЫЙ, МАССИВЫ.
Цель работы: Проектирование и разработка программы для осуществления сортировки данных методами «Выбора» с использованием языка C# и Visual Studio 2012.
Объект исследования: Методы сортировки Выбором.
Предмет исследования: Программа на языке С#.
Содержание
Содержание
Введение
. ОПИСАНИЕ ПРЕДМЕТНОЙ ОБЛАСТИ
.1 Сортировка выбором
.2 Пирамидальная сортировка
.3 Плавный метод сортировки
.4 Постановка задачи
. ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРИЛОЖЕНИЯ
.1 Алгоритм решения
.2 Макет приложения
.3 Описание программы
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ПРИЛОЖЕНИЕ-ЛИСТИНГ ПРОГРАММЫ
Введение
В современном мире мы часто сталкиваемся с большими объемами нужной нам информации. Ее так много, что можно запутаться, что же делать? Действительно, нередко среди огромного потока информации могут затеряться необходимые данные. Чтобы избежать этого, а также ускорить поиск нужной информации используют методы сортировок. Существует два вида сортировки данных: внешний и внутренний.
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступ к любой ячейке. Этот вид сортировки характерен тем, что данные сортируются на том же месте, без дополнительных затрат.
В свою очередь методы внутренней сортировки делятся на прямые и улучшенные:
Прямые методы:
· Вставкой (включением)
· Выбором (выделением)
· Обменом («пузырьковая»)
Улучшенные методы:
· Быстрая
· Шелла
Внешняя сортировка - сортировка данных, расположенных на периферийных устройствах и не вмещающихся в оперативную память, то есть когда применить одну из внутренних сортировок невозможно.
Стоит отметить, что внутренняя сортировка значительно эффективней внешней, так как на обращение к оперативной памяти затрачивается намного меньше времени, чем к магнитным дискам, лентам и т. п.
Рассматриваемый в данной курсовой работе вид сортировки «Выбор» имеет три варианта реализации: простая выборка, пирамидальная, плавная.
В соответствии с поставленной целью были сформулированы следующие задачи:
· Провести предметный анализ в области
· Разработать необходимую программу
· Провести тестирование приложения
· Определить эффективность разработанной программы
1.ОПИСАНИЕ ПРЕДМЕТНОЙ ОБЛАСТИ
1.1 Сортировка выбором
Сортировка выбором (от англ. Selection sort)
- алгоритм сортировки. Может быть как устойчивый, так и неустойчивый. На
массиве из n элементов имеет время выполнения в
худшем, среднем и лучшем случае Θ(![]() ), предполагая, что сравнения
делаются за постоянное время.
), предполагая, что сравнения
делаются за постоянное время.
Идея метода состоит в том, чтобы создавать отсортированную
последовательность путем присоединения к ней одного элемента за другим в
правильном порядке. Будем строить готовую последовательность, начиная с левого
конца массива. Алгоритм состоит из n последовательных шагов, начиная от нулевого и заканчивая (n-1)-м. На i-м шаге выбираем наименьший из элементов a[i]…a[n] и меняем его местами с a[i]. Последовательность шагов при n=5 изображена на рис.1
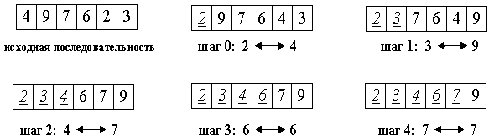
Рисунок1. Демонстрация последовательных шагов при n=5
Вне зависимости от номера текущего шага i, последовательность a[0]…a[i] является упорядоченной. Таким образом, на (n-1)-м шаге вся последовательность, кроме a[n] оказывается отсортированной, а a[n] стоит на последнем месте по праву: все меньшие элементы уже ушли влево.
Для нахождения наименьшего элемента из n+1 рассматриваемых алгоритм совершает n сравнений. С учетом того, что количество рассматриваемых на очередном шаге элементов уменьшается на единицу, общее количество операций:
n+ (n-1)+(n-2)+(n-3)+…1=1/2*(![]() +n) = Theta(
+n) = Theta(![]() ).
).
Таким образом, так как число обменов всегда будет меньше числа сравнений,
время сортировки растет квадратично относительно количества элементов.
1.2 Пирамидальная сортировка
Пирамидальная сортировка является методом, быстродействие которого
оценивается как О(n log n). В качестве некоторой прелюдии к основному методу,
рассмотрим перевернутую сортировку выбором. Во время прохода, вместо вставки
наименьшего элемента в левый конец массива, будем выбирать наибольший элемент,
а готовую последовательность строить в правом конце.
55 12 42 94 18 06 67 исходный массив
55 12 42 67 18 06 |94 94 <-> 67
55 12 42 06 18 |67 94 67 <-> 06
18 12 42 06 |55 67 94 55 <-> 18
18 12 42 |44 55 67 94 44 <-> 06
18 12 |42 44 55 67 94 42 <-> 42
12 |18 42 44 55 67 94 18 <-> 12
|12 18 42 44 55 67 94 12 <-> 12
Рисунок 2. Пример действия массива а[0]…a[7]
Вертикальной чертой отмечена левая граница уже отсортированной (правой)
части массива. Рассмотрим оценку количества операций подробнее. Всего
выполняется n шагов, каждый из которых состоит в
выборе наибольшего элемента из последовательности a[0]…a[i] и последующем обмене. Выбор
происходит последовательным перебором элементов последовательности поэтому
необходимое на него время: O(n). Итак, n шагов по О(n)
каждый - это О![]() ).
).
Произведем усовершенствование: построим структуру данных, позволяющих выбирать максимальный элемент последовательности не за O(n), а за O(logn) времени. Тогда общее быстродействие сортировки будет n*O(logn) = O(n log n).
Эта структура также должна позволять быстро вставлять новые элементы( чтобы быстро ее построить из исходного массива) и удалять максимальный элемент(он будет помещаться в уже отсортированную часть массива - его правый конец).
Итак назовем пирамидой бинарное дерево высоты k, в котором:
· все узлы имеют глубину k или k-1 - дерево сбалансированное.
· при этом уровень полностью заполнен, а уровень k заполнен слева направо.
· выполняется свойство пирамиды: каждый элемент меньше, либо
равен родителю.
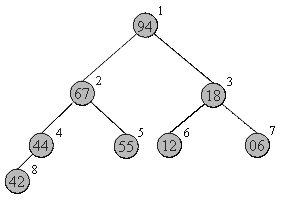
Соответствие между геометрической структурой пирамиды как дерева и массивом устанавливается по следующей схеме на рисунке 3.
· в а[0] хранится корень дерева
· левый и правый сыновья элемента a[i] хранятся, соответственно, в a[2i+1 и a[2i+2]
Таким образом, для массива, хранящего в себе пирамиду, выполняется следующее характеристическое свойство: a[i]>=a[2i+1] и a[i]>=a[2i+2]
Плюсы такого хранения пирамиды очевидны:
· никаких дополнительных переменных, нужно лишь понимать схему
· узлы одного уровня хранятся в массиве слева направо
Запишем в виде массива пирамиду, изображенную выше. Слева-направо, сверху-вниз: 94 67 18 44 55 12 06 42. На рисунке 3 место элемента пирамиды в массиве обозначено цифрой справа-вверху от него.
Восстановить пирамиду из массива как геометрический объект легко - достаточно вспомнить схему хранения и нарисовать, начиная от корня.
Начать построение пирамиды можно с a[k]…a[n], k = [size/2]. Эта часть массива удовлетворяет свойству пирамиды, так как не существует индексов i, j: i=2i+1 ( или j = 2i+2 ). Такие i,j находятся за границей массива.
Далее будем расширять часть массива, обладающую столь полезным свойством, добавляя по одному элементу за шаг. Следующий элемент на каждом шаге добавления - тот, который стоит перед уже готовой частью.
Чтобы при добавлении элемента сохранялась пирамидальность, будем использовать следующую процедуру расширения пирамиды a[i+1]..a[n] на элемент a[i] влево.
Новый элемент будет просеиваться сквозь пирамиду.
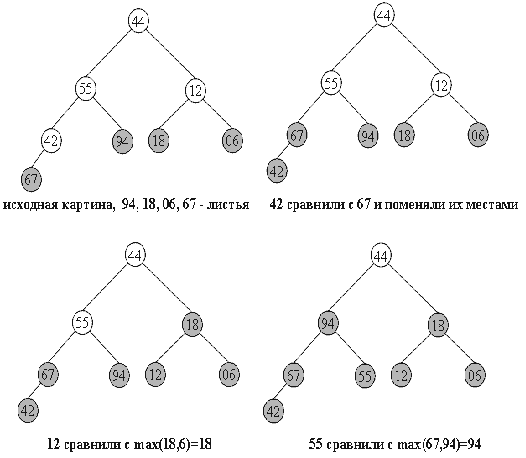
Ниже дана иллюстрация процесса для пирамиды из 8-ми элементов:
55 12 42 // 94 18 06 67
55 12 // 67 94 18 06 42
55 // 18 67 94 12 06 42
// 94 18 67 55 12 06 42
// 94 67 18 44 55 12 06 42
Справа - часть массива, удовлетворяющая свойству пирамиды, остальные элементы добавляются один за другим, справа налево.
В геометрической интерпретации ключи из начального отрезка a[size/2]…a[n] являются листьями в бинарном дереве, как изображено ниже. Один за другим остальные элементы продвигаются на свои места, и так - пока не будет построена вся пирамида.
Неготовая часть пирамиды (начало массива) окрашена в белый цвет,
удовлетворяющий свойству пирамиды конец массива - в темный.
Рисунок 4. Процесс построения пирамиды
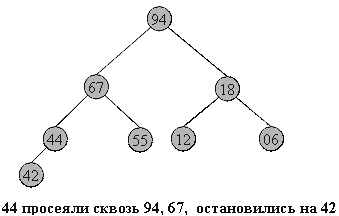
Итак, задача построения пирамиды из массива успешно решена. Как видно из свойств пирамиды, в корне всегда находится максимальный элемент. Отсюда вытекает алгоритм фазы 2:
· Берем верхний элемент пирамиды a[0]…a[n] (первый в массиве) и меняем с последним местами. Теперь «забываем» об этом элементе и далее рассматриваем массив a[0]…a[n-1]. Для превращения его в пирамиду достаточно просеять лишь новый первый элемент.
· Повторяем шаг 1, пока обрабатываемая часть массива не
уменьшится до одного элемента.
Рисунок 5. Просеивание элементов массива
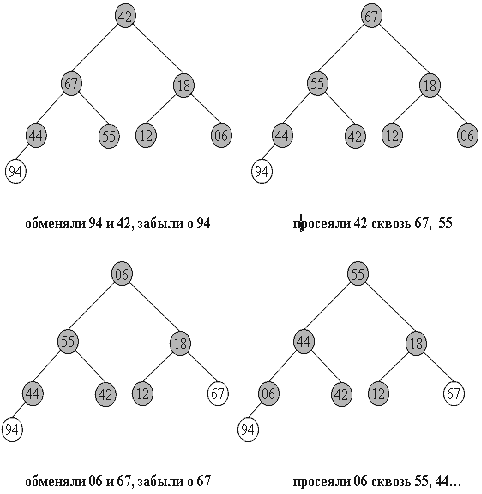
Очевидно, что в конец массива каждый раз попадает максимальный элемент из
текущей пирамиды, поэтому в правой части постепенно возникает упорядоченная
последовательность.
Рисунок 6. Иллюстрация 2-й фазы сортировки во внутреннем представлении пирамиды.
67 18 44 55 12 06 42 //
55 44 06 42 18 12 // 94
42 44 06 12 18 // 67 94
42 18 06 12 // 55 67 94
12 18 06 // 44 55 67 94
12 06 // 42 44 55 67 94
06 // 18 42 44 55 67 94
// 12 18 42 44 55 67 94
Построение пирамиды занимает О(n log n) операций, причем более точная оценка дает даже О(n) за счет того, что реальное время выполнения зависит от высоты уже созданной части пирамиды.
Вторая фаза занимает O(n log n) времени: O(n) раз берется максимум и происходит просеивание бывшего последнего элемента. Плюсом является стабильность метода: среднее число пересылок (n log n)/2, и отклонения от этого значения сравнительно малы.
Пирамидальная сортировка не использует дополнительной памяти. Метод не
является устойчивым: по ходу работы массив так «перетряхивается», что исходный
порядок элементов может измениться случайным образом, частичная упорядоченность
массива никак не учитывается.
1.3 Плавный метод сортировки
Плавная сортировка - алгоритм сортировки выбором, разновидность пирамидальной сортировки, разработанная Э. Дейкстрой в 1981 году. Как и пирамидальная сортировка, имеет сложность в худшем случае равную O(n log n). Преимущество плавной сортировки в том, что её сложность приближается к O(n), если входные данные частично отсортированы, в то время как у пирамидальной сортировки сложность всегда одна, независимо от состояния входных данных.
Как и в пирамидальной сортировке, в массив накапливается куча из данных, которые затем сортируются путём непрерывного удаления максимума из кучи. В отличие от пирамидальной сортировки, здесь используется не двоичная куча, а специальная, полученная с помощью чисел Леонардо. Куча состоит из последовательности куч, размеры которых равны одному из чисел Леонардо, а корни хранятся в порядке возрастания. Преимущества таких специальных куч перед двоичными состоят в том, что если последовательность отсортирована, её создание и разрушение займёт O(n) времени, что будет быстрее. Разбить входные данные на кучи просто: крайние слева узлы массива составят самую большую кучу, а оставшиеся будут разделены подобным образом:
· Массив любой длины может быть также разбит на части размера L(x).
· Не должно быть двух куч одинакового размера, потому что в этом случае последовательность превратится в строго убывающую по размерам.
· Не должно быть двух куч, размеры которых равны двум последовательным числам Леонардо, за исключением массива длины 2.
Эти положения могут быть доказаны:
Каждая куча размера L(x) состоит, слева направо, из подкучи размера L(x − 1), подкучи размера L(x − 2) и корня, за исключением куч размера L(1) и L(0), которые состоят только из корня. Для каждой кучи выполняется следующее свойство: значение корня должно быть не меньше значений корней его куч-потомков (и, как следствие, не меньше значений всех узлов его куч-потомков). Для последовательности куч в свою очередь выполняется следующее свойство: значение корня каждой кучи должно быть не меньше значения корня кучи слева. Следствие этого - крайний правый узел в последовательности будет иметь наибольшее значение, и, что важно, частично отсортированный массив не будет нуждаться в перестановке элементов, для того чтобы стать правильной последовательностью куч. Это является источником приспособляемости алгоритма. Алгоритм прост. Сначала происходит разделение неотсортированного массива на кучу с одним элементом и неотсортированную часть. Куча с одним элементом, очевидно, представляет собой правильную последовательность куч. Последовательность начинает расти путём добавления по одному элементу справа за раз (если нужно, элементы меняются местами, чтобы выполнялось свойство кучи и свойство последовательности), пока не достигнет размера изначального массива. И с этого момента крайний правый элемент в последовательности куч будет самым большим для любой кучи, а, следовательно, будет находиться на верной, конечной позиции. Затем последовательность куч уменьшается до кучи с одним элементом при помощи удаления крайнего правого узла и изменения позиций элементов для восстановления состояния кучи. Как только останется куча с одним элементом, массив будет отсортирован.
Необходимы две операции: увеличение последовательности куч путём добавления элемента справа и уменьшение путём удаления крайнего правого элемента (корня последней кучи), с сохранением состояния кучи и последовательности куч.
Увеличение последовательности куч путем добавления элемента справа достигается при следующих условиях:
· Если две последние кучи имеют размеры L(x + 1) и L(x) (двух последовательных чисел Леонардо), новый элемент становится корнем кучи большего размера, равного L(x+2). Для неё свойство кучи необязательно.
· Если размеры двух последних куч не равны двум последовательным числам Леонардо, новый элемент образует новую кучу размером 1. Этот размер полагается равным L(1), кроме случая, когда крайняя правая куча уже имеет размер L(1), тогда размер новой одноэлементной кучи полагают равным L(0).
После этого должно быть восстановлено выполнение свойств кучи и последовательности куч, что, как правило, достигается при помощи разновидности сортировки вставками:
· Крайняя правая куча (сформированная последней) считается «текущей» кучей.
· Пока слева от неё есть куча и значение её корня больше значения текущего корня и обоих корней куч-потомков:
· Выполняется «просеивание», чтобы выполнялось свойство кучи:
Операция просеивания значительно упрощена благодаря использованию чисел Леонардо, так как каждая куча либо будет одноэлементной, либо будет иметь двух потомков. Нет нужды беспокоиться об отсутствии одной из куч-потомков.
Уменьшение последовательности куч путем удаления элемента справа достигается при следующих условиях:
Если размер крайней правой кучи равен 1 (то есть L(1)
или L(0)), эта куча просто удаляется. В противном случае корень этой кучи
удаляется, кучи-потомки считаются элементами последовательности куч, после чего
проверяется выполнение свойства кучи, сначала для левой кучи, затем - для
правой.
1.4 Постановка задачи
Название приложения: Программа сортировки методами выбора
Назначение разработки: Исходя из введенных пользователем данных отсортировать тремя методами сортировки: выборкой, пирамидально, плавной.
Входные данные вводятся пользователем в специальные поля. После обработки и выполнения сортировки программа выводит результат в соответствующее поле вывода.
Для корректной работы программы требуется заполнить все необходимые поля. Для реализации данной программы мы используем язык программирования C#, на платформе Visual Studio.
Системные требования к ПК:
) Операционная система Windows 7 или выше.
) Свободное место на жестко диске: 10Мб и более.
) Наличие Net.Framework 4.0 или выше.
) Оперативная память 512Мб и выше.
) Клавиатура и мышь.
2. ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРИЛОЖЕНИЯ
2.1 Алгоритм решения
В самом начале выполнения программы появляется форма, где пользователю предлагается заполнить соответствующие поля необходимыми для расчета данными.