of all of the problems). Suppose that the relations among three variables are investigated, labeled A,B,C. For example, these variables could represent ratings about the Adeptness (yes, no), Brilliance (low, medium, high), and Confidence (1,2,3,4) of a political candidate reported on various large social media sources. Suppose that six contingency tables, shown together in Table 1, are collected from various sources. The table labeled p(C = ck) is a 1−way table containing the relative frequency of ratings for 4 increasing levels of Confidence obtained from one source. For example, the relative frequency of the second level of confidence equals p(C = c2) = .2788. Table p(A = ai, B = bj) is a 2 × 3 contingency table containing the relative frequencies of responses to Adeptness (yes,no) and then Brilliance (low, medium, high) obtained from another source. Table p(A = ai, C = ck) is a 2×4 contingency table containing the relative frequencies of responses to Adeptness and then Confidence presented in the AC order. For example, the relative frequency of saying yes to Adeptness and then choosing Confidence level 2 equals p(A = a1, C = c2) = .0312. Table p(C = ck, A = ai) is a table produced when the attributes (Confidence, Adeptness) were asked in the CA order. For example, the relative frequency of choosing Confidence level 2 and then saying yes to Adeptness equals p(C = c2, A = a1) = .0297. (The CA table is arranged in the same format as the AC table so that they can be directly compared). The table p(B = bj, C = ck) is a 3 × 4 contingency table containing the relative frequencies of responses to Brilliance and then Confidence in the BC order; and the table p(C = ck, B = bj) is a table produced by the opposite CB order. (Again it is displayed in the same format to facilitate comparison). Each of the six tables forms a context for judgments.
2.1. Does a joint distribution exist?
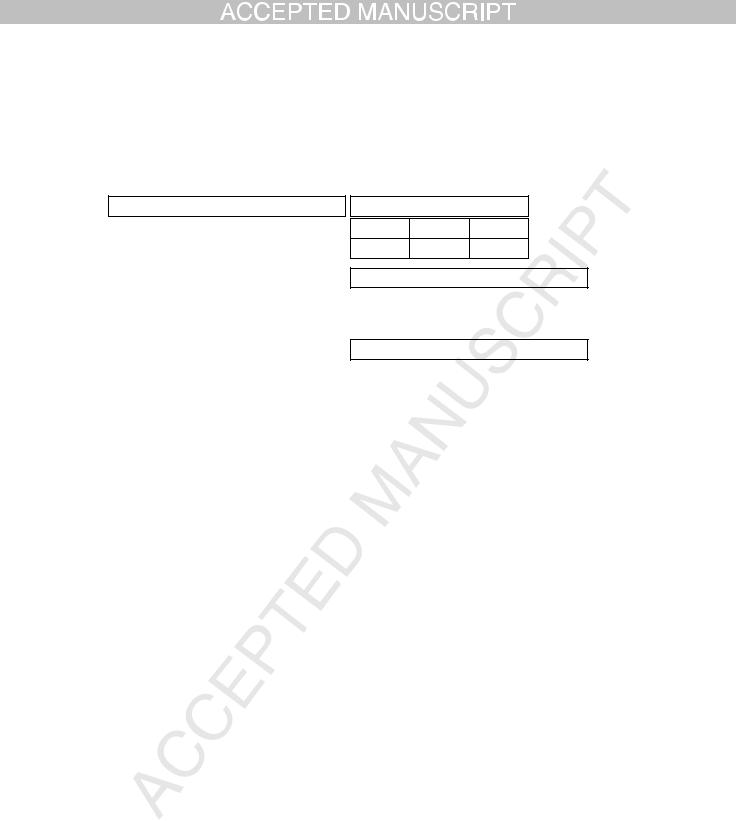
The following question can be asked about Table 1: Does a single 3 − way joint probability distribution of the observed variables exist that can reproduce Table 1? The 3 − way joint probability distribution is defined by 3 discrete random variables, A with 2 values, B with 3 values, and C with 4 values, that generate 2 · 3 · 4 = 24 latent joint probabilities that sum to one: π(A = ai ∩B = bj ∩C = ck), where, for example, A is a random variable with values a1 for yes and a2 for no, and similar definitions hold for the other three random variables. For example, the relative frequency of (A = a2, C = c4) in the table p(A = ai, C = ck) is predicted by the marginal π(A = a2, C =
is |
|
|
∩B = bj ∩C = c4), and the relative frequency of (C = c4) |
c4) = |
j π(A = a2 |
|
|
|
i,j |
|
∩ |
|
∩ |
|
|
predicted by the marginal p(C = c4) = |
π(A = ai |
|
B = bj |
|
C = c4). |



 p
p
 p
p