Материал: искусственный интеллект
suai.ru/our-contacts |
quantum machine learning |
Representing Words in Vector Space and Beyond |
93 |
Fig. 10 Hierarchical recurrent neural network [64]
Text Representation
Text |
Representation |
Classification task |
|
Sequential labelling |
|||
|
|
Interaction |
Matching task |
Text Representation
Text representation
Fig. 11 The Þgure shows that the main difference between a sentence-pair task and a sentencebased task is that there is one extra interaction for the matching task
suai.ru/our-contacts |
quantum machine learning |
94 |
B. Wang et al. |
Fig. 12 A demo of SQuAD dataset [85]
Question Answering Differently from expert systems with structured knowledge, question answering in IR is more about retrieval and ranking tasks in limited unstructured document candidates. In some literature, reading comprehension is also considered a question answering task like SQuAD QA. Generally speaking, reading comprehension is a question answering task in a speciÞc context like a long document with some internal phrases or sentences as answers, as shown in Fig. 12. Table 1 reports current popular QA datasets.
In order to compare the neural matching model and non-neural models, we focus on TREC (answer selection), which has limited answer candidates, instead of an unstructured document as context in reading comprehension. Some matching methods are shown in Table 2, which mainly refers to the ACL wiki page.7
3.4 Seq2seq Application
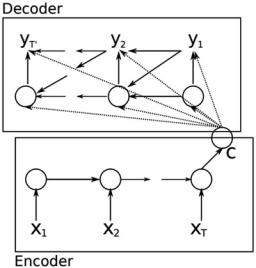
Seq2seq is a kind of task with both input and output as sequential objects, like a machine translation task. It mainly uses an encoderÐdecoder architecture [19, 100] and further attention mechanisms [3], as shown in Fig. 13. Both the encoder and decoder can be implemented as RNN [19], CNN [34], or only attention mechanisms (i.e., Transformer [111]).
7https://aclweb.org/aclwiki/Question_Answering_(State_of_the_art).
suai.ru/our-contacts |
quantum machine learning |
Representing Words in Vector Space and Beyond |
|
95 |
|
Table 1 Popular QA dataset |
|
|
|
|
|
|
|
Dataset |
Characteristics |
Main institution |
Venue |
TREC QA [119]a |
Open-domain question answering |
CMU |
EMNLP |
|
|
|
2007 |
Insurance QA [32] |
Question answering for insurance |
IBM Watson |
ASRU 2015 |
Wiki QA [123] |
Open-domain question answering |
MS |
EMNLP |
|
|
|
2015 |
Narrative QA [53] |
Reading Comprehension |
DeepMind |
TACL 2018 |
SQuAD 1.0 [85] |
Questions for machine comprehension |
Standford |
EMNLP |
|
|
|
2016 |
MS Marco [76] |
Human-generated machine reading |
MS. |
NIPS 2016 |
NewsQA [107, 108] |
Reading comprehension |
Maluuba |
RepL4NLP |
|
|
|
2017 |
|
|
|
|
TriviaQA [48] |
Reading comprehension distantly |
Allen AI |
ACL 2017 |
|
supervised labels |
|
|
|
|
|
|
SQA [47] |
Sequential question answering |
U. of Maryland |
ACL 2017 |
|
|
& MS. |
|
CQA [102] |
QA with knowledge base of web |
Tel-Aviv |
NAACL |
|
|
university |
2018 |
CSQA [92] |
Complex sequential QA |
IBM |
AAAI 2018 |
QUAC [20]b |
Question answering in context |
Allen AI |
EMNLP |
|
|
|
2018 |
SQuAD 2.0 [84] |
SQuAD with unanswered questions |
Standford |
ACL 2018 |
CoQA [87]c |
Conversational question answering |
Standford |
Aug. 2018 |
Natural questions [57] |
Natural questions in Google search |
TACL 2019 |
|
The frequent publishing of QA datasets demonstrates that the academic community is paying more and more attention to this task. Almost all the researchers in this community tend to use word embedding-based neural networks for this task
ahttp://cs.stanford.edu/people/mengqiu/data/qg-emnlp07-data.tgz
bhttp://quac.ai/
chttps://stanfordnlp.github.io/coqa/
3.5 Evaluation
The basic evaluations of word embedding techniques are based on the above applications [94], e.g., word-level evaluation and downstream NLP tasks like those mentioned in the last section, as shown in [58]. Especially for a downstream task, there are two common ways to use word embedding, namely as Þxed features or by treating it only as initial weights and Þne-tuning it. We mainly divide it into two part of evaluations, i.e., context-free word properties and embedding-based downstream NLP tasks, while the latter may involve the context and the embedding can be Þnetuned.
Word Property Examples of the context-free word properties include word polarity classiÞcation, word similarity, word analogy, and recognition of synonyms and antonyms. In particular, one of the typical tasks is called an analogy task [70], which
suai.ru/our-contacts |
quantum machine learning |
96 |
B. Wang et al. |
Table 2 State-of-the-art methods for sentence selection, where the evaluation relies on the TREC QA dataset
Algorithm |
Reference |
MAP |
MRR |
Mapping dependencies trees [82] |
AI and math |
0.419 |
0.494 |
|
Symposium 2004 |
|
|
Dependency relation [22] |
SIGIR 2005 |
0.427 |
0.526 |
Quasi-synchronous grammar [119] |
EMNLP 2007 |
0.603 |
0.685 |
Tree edit models [42] |
NAACL 2010 |
0.609 |
0.692 |
Probabilistic tree edit models [118] |
COLING 2010 |
0.595 |
0.695 |
Tree edit distance [124] |
NAACL 2013 |
0.631 |
0.748 |
Question classiÞer, NER, and tree kernels [95] |
EMNLP 2013 |
0.678 |
0.736 |
Enhanced lexical semantic models [126] |
ACL 2013 |
0.709 |
0.770 |
DL with bigram+count [128] |
NIPS 2014 DL |
0.711 |
0.785 |
|
workshop |
|
|
LSTMÑthree-layer BLSTM+BM25 [116] |
ACL 2015 |
0.713 |
0.791 |
Architecture-II [32, 45] |
NIPS 2014 |
0.711 |
0.800 |
L2R + CNN + overlap [96] |
SIGIR 2015 |
0.746 |
0.808 |
aNMM: [122] attention-based neural matching model |
CIKM 2016 |
0.750 |
0.811 |
|
|
|
|
Holographic dual LSTM architecture [104] |
SIGIR 2017 |
0.750 |
0.815 |
|
|
|
|
Pairwise word interaction modeling [40] |
NAACL 2016 |
0.758 |
0.822 |
|
|
|
|
Multi-perspective CNN [39] |
EMNLP 2015 |
0.762 |
0.830 |
|
|
|
|
HyperQA (hyperbolic embeddings) [103] |
WSDM 2018 |
0.770 |
0.825 |
|
|
|
|
PairwiseRank + multi-perspective CNN [86] |
CIKM 2016 |
0.780 |
0.834 |
|
|
|
|
BiMPM [120] |
IJCAI 2017 |
0.802 |
0.875 |
|
|
|
|
Compare-aggregate [8] |
CIKM 2017 |
0.821 |
0.899 |
|
|
|
|
IWAN [97] |
EMNLP 2017 |
0.822 |
0.889 |
IWAN + sCARNN [106] |
NAACL 2018 |
0.829 |
0.875 |
NNQLM [131] |
AAAI 2018 |
0.759 |
0.825 |
Multi-cast attention networks (MCAN) [105] |
KDD 2018 |
0.838 |
0.904 |
Recent papers about TREC QA used embedding-based neural network approaches, while previous ones were based on some traditional methods like IR approaches and edit distance
mainly targets both the syntactic and semantic analogies. For instance, Òman is to womanÓ is semantically similar to Òking is to queen,Ó while Òpredict is to predictingÓ is syntactically similar to Òdance is to dancing.Ó Word Embedding methods achieve good performance in the above word-level tasks, which demonstrates that the word embedding can capture the basic semantic and syntactic properties of the word.
Downstream Task If word embedding is used in a context, which means we consider each word in a phrase or sentence for a speciÞc target, we can train the word embedding by using the labels of the speciÞc task, e.g., sequential labeling, text classiÞcation, text matching, and machine translation. These tasks are divided by the pattern of input and output, shown in Table 3.
suai.ru/our-contacts |
quantum machine learning |
Representing Words in Vector Space and Beyond |
97 |
Fig. 13 An illustration of the proposed Seq2seq (RNN EncoderÐDecoder)
Table 3 The difference of the downstream tasks
Algorithm |
Input |
Output |
Typical tasks |
Typical models |
|
|
|
|
|
Text classiÞcation |
S |
R |
Sentiment analysis, topic |
Fastext/CNN/RNN |
|
|
|
classiÞcation |
|
Text matching |
(S1, S2) |
R |
QA, reading comprehension |
aNMM,DSSM |
Sequential labeling |
S |
R|S| |
POS, word segmentation, |
LSTM-CRF |
|
|
|
NER |
|
Seq2Seq |
S1 |
S2 |
machine translation, |
LSTM/Transformer |
|
|
|
abstraction |
encoderÐdecoder |
Generally speaking, the tasks for the word properties can partially reßect the quality of the word embedding. However, the Þnal performance in the downstream tasks may vary. It is more reasonable to directly assess it in the real-world downstream tasks as shown in Table 3.
4 Reconsidering Word Embedding
Some limitations and trends of word embedding are introduced in Sects. 4.1 and 4.2. We also try to discuss the connections between word embedding and topic models in Sect. 4.3. In Sect. 4.4, the dynamic properties of word embedding are discussed in detail.