Материал: искусственный интеллект
suai.ru/our-contacts |
quantum machine learning |
42
Fig. 1 Illustration of a collection of contingency data tables
J. Busemeyer and Z. J. Wang
Multiple Contingency Tables
|
3 x 2 |
|
3 x 4 |
|
|
|
2 x 4 |
|
|
|
4 x 5 |
|||||||
|
|
|
|
|
A |
|
|
|
|
B |
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
C |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B |
|
C |
|
|
|
C |
|
|
|
D |
||||||
|
|
3 x 2 x 4 |
|
|
|
3 x 4 x 5 |
|
2 x 4 x 5 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||
A |
|
|
|
|
C |
A |
|
|
|
|
D |
B |
|
|
|
D |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C |
||||
|
|
|
|
|
|
|
|
|
C |
|||||||||
|
|
B |
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Figure 1 illustrates the basic problem that we wish to address. Suppose large medical data sites provide information about co-occurrence of various kinds of symptoms, labeled A, B, C, and D in the Þgure. The symptoms can be manifest to different degrees. For example, symptom B is binary valued, symptom A has three levels, symptom C has four degrees, and symptom D has Þve rating values. Suppose different methods for querying the sites yield different contingency tables summarizing co-occurrence of pairs of variables and co-occurrence of triples of variables, which produce the tables shown in the Þgure. The cells of the contingency tables contain the frequency of a combination of symptoms. For example, the A by B by C table is a 3 by 2 by 4 table, and each cell contains the frequency that a particular combination of values was assigned to the variables A, B, C, using one query method.
The following problem arises from considering all these contingency tables. How does a data scientist integrate and synthesize these seven different tables into a compressed, coherent, and interpretable representation? This is a problem that often arises in relational database theory [1]. It is common to apply categorical data analysis [3] to a single table (e.g., a single A by B by C by D table). However, the problem is different here because there are a collection of seven tables of varying dimensions rather than a single four-way table. Alternatively, one could try Bayesian networks, which require assuming that all the tables are generated from a single latent four-way joint distribution [10]. Unfortunately, however, it may be the case that no four-way joint distribution exists that can reproduce all the observed tables! This occurs when the data tables violate consistency constraints, forced by marginalization, upon which Bayes nets rely to Þt the tables [11].
Hilbert space multi-dimensional (HSM) models are based on quantum probability theory [13]. They provide a way to account for a collection of tables, such as illustrated in Fig. 1, even when no four-way joint distribution exists. HSM models provide an estimate of the target populationÕs initial tendencies in the form of a state vector, and HSM models represent the inter-relationships between the different variables (symptoms in this example) using ÒrotationsÓ of the basis of the vector space.

suai.ru/our-contacts |
quantum machine learning |
Introduction to Hilbert Space Multi-Dimensional Modeling |
43 |
This chapter is organized as follows: First, we summarize the basic principles of quantum probability theory, then we summarize the steps required to build an HSM model, and Þnally we refer to programs available on the web for applying an HSM model to real data.
2 Basics of Quantum Probability Theory
The idea of applying quantum probability to the Þeld of judgment began from several directions [2, 4, 5, 14]. The Þrst to apply these ideas to the Þeld of information retrieval was by van Rijsbergen [18]. For more recent developments concerning the application of quantum theory to information retrieval, see [16]. van Rijsbergen argues that quantum theory provides a sufÞciently general yet rigorous formulation for integration of three different approaches to information retrievalÑ logical, vector space, and probabilistic. Another important reason for considering quantum theory is that human judgments (e.g., judging presence of symptoms by doctors) have been found to violate rules of Kolmogorov probability, and quantum probability provides a formulation for explaining these puzzling Þndings (see, e.g., [7]).
HSM models are based on quantum probability theory and so we need to brießy review some of the basic principles used from this theory.1
In quantum theory, a variable (e.g., variable A) is called an observable, which corresponds to the Kolmogorov concept of a random variable. The pair of a measurement of a variable and an outcome generated by measuring a variable is an event (e.g., measurement of variable A produces the outcome 3, so that we observe
A = 3).
Kolmogorov theory represents events as subsets of a sample space, . Quantum theory represents events as subspaces of a Hilbert space H .2 Each subspace, such as A, corresponds to an orthogonal projector, denoted PA for subspace A. An orthogonal projector is used to project vectors into the subspace it represents.
In Kolmogorov theory, the conjunction ÒA and BÓ of two events, A and B, is represented by the intersection of the two subsets representing the events (e.g., (A = 3) ∩ (B = 1)). In quantum theory, a sequence of events, such as A and then B, denoted AB, is represented by the sequence of projectors PB PA. If the projectors commute, PAPB = PB PA, then the product of the two projectors is a projector corresponding to the subspace A ∩ B, that is, PB PA = P (A ∩ B); and the events A and B are said to be compatible. However, if the two projectors do not commute, PB PA = PAPB , then neither their product is a projector, and the events
1See [7, 15, 16, 18] for tutorials for data and information scientists.
2Technically, a Hilbert space is a complex valued inner product vector space that is complete. Our vectors spaces are Þnite, and so they are always complete.
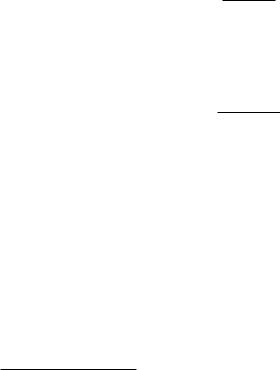
suai.ru/our-contacts |
quantum machine learning |
44 |
J. Busemeyer and Z. J. Wang |
are incompatible. The concept of incompatibility is a new contribution of quantum theory, which is not present in Kolmogorov theory.
Kolmogorov theory deÞnes a state as a probability measure p that maps events to probabilities. Quantum theory uses a unit length state vector, here denoted ψ, to assign probabilities to events.3 Probabilities are then computed from the quantum algorithm
p(A) = PAψ 2 . |
(1) |
Both Kolmogorov and quantum probabilities satisfy the properties for an additive measure. In the Kolmogorov case, p(A) ≥ 0, p( ) = 1, and if (A ∩ B) = 0, then p(A B) = p(A) + p(B).4 In the quantum case, p(A) ≥ 0, p(H ) = 1, and if PAPB = 0, then p(A B) = p(A) + p(B).5 In fact, Eq. (1) is the unique way to assign probabilities to subspaces that form an additive measure for dimensions greater than 2 [12].
Kolmogorov theory deÞnes a conditional probability function as follows:
p(B|A) = p(A ∩ B) , p(A)
so that the joint probability equals p(A ∩ B) = p(A)p(B|A) = p(B)p(A|B) = p(B∩A), and order does not matter. In quantum theory, the corresponding deÞnition of a conditional probability is
p(B|A) = PB PAψ 2 , p(A)
and so the probability of the sequence AB equals p(AB) = p(A) · p(B|A) =PB PAψ 2. In the quantum case, this deÞnition of conditional probability incorporates the property of incompatibility: if the projectors do not commute, so that PAPB = PB PA, then p(AB) = p(BA), and order of measurement matters. Extensions to sequences with more than two events follow the same principles for both classical and quantum theories. For example, the quantum probability of the sequence (AB)C equals PC (PB PA) ψ 2.
3A more general approach uses what is called a density operator rather than a pure state vector, but to keep ideas simple, we use the latter.
4 is the union of subsets A, B.
5 is the span of subspaces A, B.
suai.ru/our-contacts |
quantum machine learning |
Introduction to Hilbert Space Multi-Dimensional Modeling |
45 |
3 Steps to Build an HSM Model
An HSM model is constructed from the following six steps:
1.Determine the compatibility and incompatibility relations among the variables.
2.Determine the dimension of the Hilbert space based on assumed compatibility relations.
3.DeÞne the initial state given the dimension of the Hilbert space.
4.DeÞne the projectors for the variables using unitary transformations to change the basis.
5.Compute the choice probabilities given the initial state and the projectors.
6.Estimate model parameters, compare Þt of models.
3.1 How to Determine the Compatibility Relations
There are two ways to investigate and determine compatibility between a pair of variables. The direct way is to empirically determine whether or not the joint frequencies change depending on order of presentation. If there are order effects, then that is evidence for incompatibility. An indirect way is to compare Þts of models that assume different compatibility relations. This indirect methods might be needed if no empirical tests of order effects are available.
3.2 How to Determine the Dimension
The basic idea of HSM modeling is to start with the minimum dimension required, and then add dimensions only if needed to obtain a satisfactory Þt to the data. Of course this model comparison and model selection process needs to provide a reasonable balance between accuracy and parsimony. For example, when Þtting the models using maximum likelihood estimation, model comparison indices such as Bayesian information criterion or Akaike information criterion can be used.
The minimum dimension is determined by the maximum number of combinations of values produced by the maximum number of compatible variables. For example, in Fig 1, suppose variables B and C are compatible with each other, and variables A and D are compatible with each other, but the pair B,C is incompatible with the pair A,D. In this case, there are at most two compatible variables. The B,C pair produces 2 · 4 = 8 combinations of values, but the A,D pair produces 3 · 5 = 15 combinations. The minimum dimension needs to include all 15 combinations produced by the A,D pair. Therefore, the minimum dimension is 15 in this example.
suai.ru/our-contacts |
quantum machine learning |
46 |
J. Busemeyer and Z. J. Wang |
3.3 Define the Initial State
The compatible variables can be chosen to form the basis used to deÞne the coordinates of the initial state ψ. In this example, the space is 15 dimensional, and the compatible pair, A,D can be chosen to deÞne the initial basis for the unit length 15 × 1 column matrix ψ. Each coordinate ψij represents the amplitude corresponding to the pair of values (A = i, D = j ), i = 1, 2, 3; j = 1, 2, . . . , 5, for representing the initial state. The squared magnitude of a coordinate equals the probability of the combination, p(A = i, D = j ) = ψij 2. In general, the coordinates can be complex, but in practice they are usually estimated as real values.
3.4 Define the Projectors
The orthogonal projector for an event that is deÞned in the initial basis is simply an indicator matrix that picks out the coordinates that correspond to the event. For example, using the previous example, the projector for the event (A = i, D = j ) is simply PA=i,D=j = diag 0 · · · 1 · · · 0 , where the one is located in the row corresponding to (i, j ), which is a one-dimensional projector. The projector for the event (A = i) equals PA=i = j PA=i,D=j and the projector for the event (D = j ) equals PD=j = i PA=i,D=j , and these are multi-dimensional projectors.
The projectors for the incompatible events require changing the basis from the original basis to the new basis for the incompatible variables. For example, suppose we wish to deÞne the events for the variables B,C. If we originally deÞned the initial state ψ in the B,C basis from the start, then these projectors would simply be deÞned by indicator matrices as well. Recall that the dimension of the space is 15, and there are only 8 combination of values for B, C. Therefore one or more of the combinations for B, C need to be deÞned by a multi-dimensional projector, Mkl , which is simply an indicator matrix, such as Mkl = diag 1 0 . . . 1 0 that picks out two or more coordinates for the event (B = k, C = l). The collection of indicator matrices, {Mkl , k = 1, 2; l = 1, 2, 3, 4}, forms a complete orthonormal set of projectors. The projector for the event (B = k), in the B, C basis, is simply p(B = k) = l MB=k,C=l , and the projector for (C = l) in the B, C basis is p(C = l) =
We did not, however, deÞne the initial state ψ in terms of the B,C basis. Instead we deÞned the initial state ψ in terms of the A,D basis. Therefore we need to ÒrotateÓ the basis from the A, D basis to the B, C basis to form the B,C projectors as follows: PB=k,C=l = U ·Mj k ·U , where U is a unitary matrix (an orthonormal matrix). Now the projector for the event (B = k), in the A, D basis, is p(B = k) = l PB=k,C=l , and the projector for (C = l) in the A, D basis is p(C = l) =
Any unitary matrix can be constructed from a Hermitian matrix H = H by the matrix exponential U = exp(−i · H ). Therefore, the most challenging problem is to construct a Hermitian matrix that captures the change in bases. This is facilitated