Материал: искусственный интеллект
suai.ru/our-contacts |
quantum machine learning |
Non-separability Effects in Cognitive Semantic Retrieving |
37 |
Suppose there are two subsystems A and B, and experiments are performed, respectively, each having two possible outcomes coded by values of ±1. This condition is satisÞed, for example, by the system of electron pairs, whose spins are measured. Each of experiments A and B is performed in two versions A and A , B and B , which differ in the direction of spin measurement: 0◦, 90◦, 45◦, and 135◦, respectively. These directions are combined in four possible ways: {A, B}, A, B , A , B , A , B in each conÞguration to obtain a statistically signiÞcant set of (probabilistic) outcomes. The so-called ClauserÐHorneÐShimonyÐ Holt (CHSH) type Bell inequality
S = AB − AB + A B + A B ≤ 2 |
(1) |
is used to distinguish purely quantum and classical correlations in theory. Inequality
(1) holds for separable states, if factorization for statistically average values is true, i.e., . . . = . . . . . . .
In quantum theory, TsirelsonÕs bound predicts the existence of quantum states of
two subsystems for which (see [3]) |
|
||
√ |
|
|
|
2 < S ≤ 2 2. |
(2) |
||
In physics, these states are called entangled or non-separable [7]. Violation of CHSH inequality provides evidence for contextual interdependence for a given set of systems and experimental procedures.
2.2 Bell Test in Semantic Retrieving
In this paper, we use a Bell test, the experiment that checks inequalities discussed above, and conducted with objects in the semantic Hilbert space. In our experiment we use hyperspace analogue to language (HAL) algorithm for obtaining the vector representation of words, which unlike the popular bag of words allows to consider the word order in a sentence and thereby increasing the accuracy of determining dependencies between words. The HAL algorithm also gives the vector representation of words based on the vocabulary index (the word matches some unique numeric identiÞer) and the set of documents processed. To obtain such a representation, the matrix is built with cells containing sums of distances between the word corresponding to a row and the word corresponding to a column in the frame of the text corpus. At the same time, the relationship distance from a word in
ú
a row to a word in a column if the word in the column is to the rightI is modeled. Thus, the word order in the sentence is taken into account. Moreover, the distance is not calculated between all the words in the matrix, but only between those pairs of words that are closer to each other than a predetermined distance, which is called the HAL window size.
suai.ru/our-contacts |
quantum machine learning |
38 A. V. Platonov et al.
To perform the Bell test we use text Þles obtained from several Wikipedia articles in Russian on Programming Language: Programming Language, Programming, Java, C++. The content of these articles without the layout was subjected to preprocessing. While reading the Þles, a text index is constructed. It contains the normalized forms of words and their correspondence to a unique numeric identiÞer. This numeric identiÞer is used to determine one vector coordinate in the vector space of words obtained by HAL algorithm. After obtaining the index of the words for the document being processed, HAL matrix is built (see the next subsection). This allows to get a vector representation of the words of the document, and the average value of the sum of these vectors is the document vector. Query word vectors are derived from the same HAL matrix. The resulting document and query vectors are used to calculate a Bell parameter.
Thus, as far as the index and vector representations of words are obtained, the words of the user query, such as Programming Language, are reduced to a vector form and then normalized. On these words two bases are constructed deÞning the subspaces of vectors corresponding to the two query words. To obtain a basis, the Schmidt orthogonalization algorithm is used. The document vector decomposes
according to these bases: |
|
Dw1 = a |+ A + b |− A ; Dw2 = c |+ B + d |− B , |
(3) |
where Dw1 is the document vector; |+ A (|− A) and |+ B (|− B ) are bases in which queries A and B are fully relevant (not relevant) to the document, respectively. Next, we deÞne (projective) measurement operators for queries A and B, respectively:
Ax = |+ AA −| + |− AA +| ; Az = |+ AA +| − |− AA −| ;
(4)
Bx = |+ BB −| + |− BB +| ; Bz = |+ BB +| − |− BB −| .
The operators related to the same queries (for example, to A or to B) do not commute with each other and correspond to operators of measurement of spin projections in quantum physics [7, 10]. Operator Az allows us to determine the degree of the document relevance with the Þrst word of the query. In this case, if the document vector in the basis of the Þrst word is represented by the vector [a, b] (3), then the probability that the document relates to the subject of the Þrst word can
2 |
2 |
. |
√ |
|
be obtained by the Born rule Az D = D |Az| D = a√− b |
||||
We also use the combinations B+ = (Bz − Bx )/ |
2, B− = −(Bz + Bx )/ |
|
2 |
|
which determine the degree of correspondence of the document to the second word in the rotated basis. Note that the calculations can be performed in the basis of one of the words, for example, A. The resulting set of operators is used to calculate the Bell parameter of queries:
Sq = | AzB+ + Ax B+ | + | AzB− − Ax B− | . |
(5) |
suai.ru/our-contacts |
quantum machine learning |
Non-separability Effects in Cognitive Semantic Retrieving |
39 |
3 Results
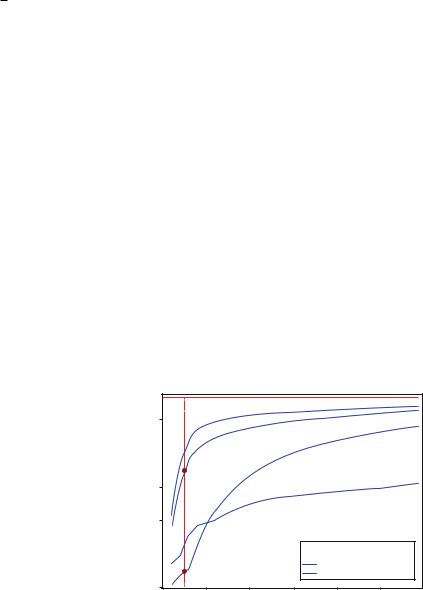
Figure 1 displays the results of the Bell test performed with Russian texts on Language (word A) of Programming (word B) from Wikipedia. As seen, the Bell test essentially depends on the size of the HAL window under the modeling semantic space√ . For a large HAL window all four curves approach the value of quantum limit 2 2. This can be explained by the fact that with increasing the size of the window, the terms included in the userÕs request overlap more often with each other contexts. The same can be said about the values of less than 2. However, it is important that all the curves in Fig. 1 reach the quantum entanglement domain at different window sizes. From Fig. 1 it is evident that the document ÒProgramming LanguageÓ Þrst reaches this domain as it directly relates to the subject of the request. Then the documents ÒJava,Ó ÒC++,Ó and ÒProgrammingÓ follow.
Thus, we can conclude that a Bell test can be used as a sign of relevance (contextuality) of the article to the subject of a request.
The bigger value of the Bell test parameter does not mean the greater entanglement. However, the size of a HAL window, which Òquantum entanglementÓ or ÒinseparabilityÓ appears on, can indicate the presence of a subject searched in an article.
Moreover, this test can be used to separate text documents by means of request subjects. Documents more relevant to a query subject reveal Bell test parameter value greater than 2 with less size of a HAL window. This interesting feature can be applied in two ways.
First, one can rank the documents by a size of a HAL window giving Bell test parameter greater than 2. More relevant documents have less size of a window.
Second, this test may be used for subject terms extraction. Choosing a Þxed window size one can extract pairs of word chains for which a Bell test parameter is greater than a threshold. Further we are going to apply this test for more extensive testing of these hypotheses.
Fig. 1 Bell test parameter vs. HAL window size for four documents. The dots characterize Bell parameter values indicating the ranking of the documents at the request
Sq
2 √2
2.5
2.0 

1.5
1.0

 Programming 0.5
Programming 0.5 
 “Java”
“Java”
Programming language “C++”
0.0 |
50 |
100 |
150 |
200 |
250 |
300 |
0 |
HAL window size
suai.ru/our-contacts |
quantum machine learning |
40 |
A. V. Platonov et al. |
Acknowledgements This work was Þnancially supported by the Government of the Russian Federation, Grant 08-08. The authors are grateful to Prof. Andrei Khrennikov and Dr. Ilya Surov for fruitful discussions.
References
1.Alodjants, A. P., & Arakelian, S. M. (1999). Quantum phase measurements and nonclassical polarization states of light. Journal of Modern Optics, 46(3), 475Ð507.
2.Busemeyer, J. R., & Bruza, P. D. (2012). Quantum models of cognition and decision (p. 408). Cambridge: Cambridge University Press.
3.CirelÕson, B. S. (1980). Quantum Generalizations of BellÕs Inequality. Letters in Mathematical Physics, 4, 93.
4.Gurevich, I. I., & Feigenberg, I. M. (1977). What probabilities work in psychology? Probabilistic forecasting of human activity (pp. 9Ð21). Moscow: Science.
5.Khrennikov, A. Yu. (2010). Ubiquitous quantum structure. From psychology to finance (p. 216). Berlin: Springer.
6.Melucci, M. (2015). Introduction to information retrieval and quantum mechanics. The information retrieval series (Vol. 35, p. 232). Berlin: Springer.
7.Peres, A. (2002). Quantum theory: Concepts and methods (p. 464). Dordrecht: Kluwer.
8.Piwowarski, B., Frommholz, I., Lalmas, M., & van Rijsbergen, C. J. (2010). What can quantum theory bring to information retrieval. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (pp. 59Ð68). New York, NY: ACM.
9.Van Rijsbergen, C. J. (2004). The geometry of information retrieval (p. 150). New York, NY: Cambridge University Press.
10.Wheeler, J. A., & Zurek W. (Eds.) (1983). Quantum theory and measurement (p. 811). Princeton, NJ: Princeton University Press.
11.Zhang, P., Li, J., Wang, B., Zhao, X., Song, D., Hou, Yu., et al. (2016). A quantum query expansion approach for session search. Entropy, 18, 146.
12.Zhang, P., Song, D., Zhao, X., & Hou, Y. (2011). Investigating query-drift problem from a novel perspective of photon polarization. in Proceedings of the Conference on the Theory of Information Retrieval (pp. 332Ð336). Berlin: Springer.
13.Zuccon, G., & Azzopardi, L. (2010). Using the quantum probability ranking principle to rank interdependent documents. In: Proceedings of the European Conference on Information Retrieval (pp. 357Ð369). Berlin: Springer.

suai.ru/our-contacts |
quantum machine learning |
Introduction to Hilbert Space
Multi-Dimensional Modeling
Jerome Busemeyer and Zheng Joyce Wang
Abstract This chapter provides a brief introduction to procedures for estimating Hilbert space multi-dimensional (HSM) models from data. These models, which are built from quantum probability theory, are used to provide a simple and coherent account of a collection of contingency tables. The collection of tables are obtained by measurement of different overlapping subsets of variables. HSM models provide a representation of the collection of the tables in a low dimensional vector space, even when no single joint probability distribution across the observed variables can reproduce the tables. The parameter estimates from HSM models provide simple and informative interpretation of the initial tendencies and the inter-relations among the variables.
Keywords Quantum probability á Non-commutativity á Data fusion
1 Introduction
This chapter provides an introduction to computational tools, based on what we call Hilbert space multi-dimensional theory, which can be used for representing data tables from multiple sources by a single coherent vector space and linear operations on the space. For more complete descriptions of this theory, see the original articles by the authors Busemeyer and Wang [8, 9], which include detailed worked out examples. Here we plan to outline the main steps of building a program and also point to computer programs available to process collections of data tables.
J. Busemeyer ( )
Psychological and Brain Sciences, Indiana University, Bloomington, IN, USA e-mail: jbusemey@indiana.edu
Z. J. Wang
School of Communication, Center for Cognitive and Brain Sciences, The Ohio State University, Columbus, OH, USA
© Springer Nature Switzerland AG 2019 |
41 |
D. Aerts et al. (eds.), Quantum-Like Models for Information Retrieval and Decision-Making, STEAM-H: Science, Technology, Engineering, Agriculture, Mathematics & Health, https://doi.org/10.1007/978-3-030-25913-6_3