Материал: Интерфейсы интерактивного взаимодействия в информационных системах
Предположим, например, что система А, изображенная на рис.1, имеет информацию для отправки в систему В. Прикладная программа системы А начинает взаимодействовать с уровнем 4 системы А (верхний уровень), который, в свою очередь, начинает взаимодействовать с уровнем 3 системы А, и т.д. - до уровня 1 системы А. Задача уровня 1 забирать информацию из физической среды сети, отдавать, а потом после того как информация проходит через физическую среду сети и поступает в систему В, она последовательно обрабатывается на каждом уровне системы В в обратном порядке - сначала на уровне 1, затем на уровне 2 и т.д., пока, наконец, не достигнет прикладной программы системы В.
Многоуровневая модель не предполагает наличия
непосредственной связи между одноименными уровнями взаимодействующих систем.
Следовательно, каждый уровень системы А должен полагаться на услуги,
предоставляемые ему смежными уровнями системы А, чтобы помочь осуществить связь
с соответствующим уровнем системы В. Предположим, что уровень 4 системы А
должен связаться с уровнем 4 системы В. Для того чтобы выполнить эту задачу,
уровень 4 системы А должен воспользоваться услугами уровня 3 системы А, тогда
уровень 4 будет называться "пользователем услуг", а уровень 3 -
"источником услуг".
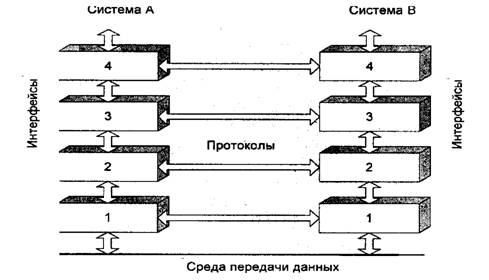
Рисунок 1.
Информация по оказываемым услугам передается
между уровнями в специальном информационном блоке, который называется
заголовком. Заголовок обычно предшествует передаваемой прикладной информации.
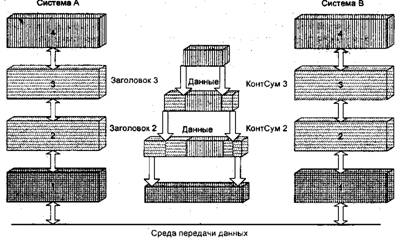
Рисунок 2. Инкапсуляция блоков данных различных
уровней
Предположим, что система А хочет отправить в систему В какой-либо текст, называемый "данные" или "информация". Этот текст передается из прикладной программы системы А в верхний уровень этой системы. Прикладной уровень системы А должен передать определенную информацию в прикладной уровень системы В, поэтому он помещает управляющую информацию своего уровня в виде заголовка перед фактическим текстом, который должен быть передан. Построенный таким образом информационный блок передается в уровень 3 системы А, который может предварить его своей собственной управляющей информацией, и т.д.
Размеры сообщения увеличиваются по мере того, как оно проходит вниз через уровни до тех пор, пока не достигнет сети, где оригинальный текст и вся связанная с ним управляющая информация перемещаются в систему В и поглощаются уровнем 1 системы В. Уровень 1 системы Отделяет от поступившей информации и обрабатывает заголовок уровня 1, после чего он определяет, как обрабатывать поступивший информационный блок. Уменьшенный в размерах информационный блок передается в уровень 2, который отделяет заголовок этого же уровня, анализирует его, чтобы узнать о действиях, которые он должен выполнить и т.д. Когда информационный блок наконец доходит до прикладной программы системы В, он должен содержать только оригинальный текст. Структура заголовка и собственно данных относительна и зависит от уровня, который в данный момент анализирует информационный блок. Например, на уровне 2 информационный блок состоит из заголовка этого же уровня и следующих за ним данных. Однако данные уровня 2 могут содержать заголовки уровней 3 и 4. Кроме того, заголовок уровня 2 является просто данными для уровня 1. Помимо заголовка на каждом уровне системы информационный блок завершается соответствующей контрольной суммой - КонтСум. Эта концепция иллюстрируется на рис.2.
В соответствии с ISO 7498 выделяются семь уровней (слоев) информационного взаимодействия:
. Уровень приложения (Application Layer).
. Уровень представления (Presentation Layer).
. Уровень сессии (Session Layer).
. Транспортный уровень (Transport Layer).
. Сетевой уровень (Network Layer).
. Канальный уровень (DataLink Layer).
. Физический уровень (Physical Layer).
Информационное взаимодействие двух или более систем, таким образом, представляет собой совокупность информационных взаимодействий уровневых подсистем, причем каждый слой локальной информационной системы взаимодействует только с соответствующим слоем удаленной системы.
Протокол - набор алгоритмов (правил) взаимодействия объектов одноименных уровней. Слои (уровни) одной информационной системы также взаимодействуют друг с другом, причем в непосредственном взаимодействии участвуют только соседние уровни. Как правило, средний уровень пользуется услугами, которые ему предоставляет нижний уровень, а сам, в свою очередь, предоставляет услуги для верхнего уровня.
Интерфейс - совокупность правил, в соответствии с которыми осуществляется взаимодействие с объектом данного уровня.
Иерархическая организация сетевого взаимодействия позволяет обеспечивать преемственность разработанных структур и их быструю адаптацию к изменениям, происходящим в технологиях передачи данных. Например, при переходе на новый способ передачи данных по физическому носителю, изменения коснутся только нижних уровней и совсем не затронут верхние в том случае, если система протоколов организована в соответствии с требованиями ISO 7498. На практике требования данного стандарта реализуются в виде стека протоколов.
Стек - иерархически организованную группу взаимодействующих протоколов. Протоколы, которые входят в стек, имеют специализированный интерфейс и предназначены для взаимодействия только с протоколами соответствующих уровней данного стека. В качестве примеров таких стеков можно привести стек TCP/IP. Уровни 7-5 считаются верхними и, как правило, не отражают специфики конкретной сети. Блок данных пользователя (сообщение) этими уровнями рассматривается как единое целое. Изменения могут испытывать только сами данные. Уровни 1-3 и иногда 4 считаются нижними уровнями OSI. На каждом из этих уровней определяется свой формат представления данных. При прохождении по стеку с 4-го уровня до первого сообщение пользователя последовательно фрагментируется и преобразуется в последовательность блоков данных соответствующего уровня. Инкапсуляция - процесс помещения фрагментированных блоков данных одного уровня в блоки данных другого уровня. Обычно инкапсулируются данные протоколов верхних уровней в блоки данных протоколов нижних уровней (сетевой - канальный), но также может выполняться инкапсуляция для протоколов одноименных уровней.
Применение многоуровневой модели, позволяет разбить
проблему перемещения информации на более простые и легко решаемые проблемы.
Многоуровневая модель даёт четкое описание тому, как информация проделывает
путь через среду сети, от одной прикладной программы к другой, расположенной на
другом конце сети.
.2 Программно-аппаратные интерфейсы. Интерфейсы
взаимодействия уровня приложений
Рассмотрим интерфейс взаимодействия двух приложений WEB-браузера и WEB-сервера (поскольку эти приложения обычно располагаются на разных машинах и, соответственно, на разных программно-аппаратных платформах используем термин программно-аппаратный интерфейс). При реализации интерфейса взаимодействия WEB - приложений используется протокол HTTP (Hypertext Transfer Protocol - протокол передачи гипертекcта), который представляет собой протокол прикладного уровня и обеспечивает возможность доступа к разнообразной информации, размещенной в сети WWW - World Wide Web. Протокол HTTP обладает высокопроизводительными механизмами тиражирования информации, независимо от типа представления данных. Протокол построен по объектно-ориентированной технологии и может использоваться для решения различных задач, например, управления распределенными информационными системами.
Способность хранить и представлять данные разнообразных форматов (изображения, видео, аудио) делает сеть WWW с используемым HTTP уникальным средством размещения информации. В настоящее время протокол HTTP используется системой WWW качестве одного из основных протоколов. С учетом этого рассмотрим подробнее методы работы протокола HTTP. Протокол HTTP позволяет получать доступ к информационным ресурсам и сервисам WWW-серверов. Для унификации доступа к многофункциональным ресурсам сети WWW-серверы поддерживают комплекс интерфейсов, позволяющих структурировать уровни и методы доступа к сетевым ресурсам. По сути, каждый из интерфейсов представляет собой объект сети со своими методами и своей структурой. Для поиска и отображения информации, размещенной в сети WWW, применяются специальные приложения, называемые Web-браузерами. Согласованное взаимодействие объектов (клиентских и серверных) и составляет понятие программного интерфейса.
Рассмотрим составляющие программно-аппаратных интерфейсов на основе протоколов уровня приложений. URI (Uniform Resource Identifier, Идентификатор ресурса), URL (Uniform Resource Locator, Местонахождение ресурса), URN (Uniform Resource Name, Имя ресурса) - разные аспекты идентификации одного и того же сервиса, определяющие тип, метод доступа и расположение узла сети, на котором находятся ресурс, доступный через сеть Интернет. Этот сервис состоит из трех частей.
) Схема. Идентифицирует тип сервиса, через который можно получить доступ к сервису, например, WWW-сервер.
) Адрес. Идентифицирует адрес (хост) ресурса, например, www.ripn.net.
) Имя или путь доступа. Идентифицирует полный путь к ресурсу на выбранном хосте, который мы хотим использовать для доступа к ресурсу, например, /home/images/image l. gif. Например, файл readme. txt, расположенный на сайте Microsoft (WWW-сервере), представляет собой ресурс с идентификатором: http://www.microsoft.com/readme. txt. Это означает, что для обращения к ресурсу должен использоваться протокол HTTP, (схема доступа отделена двоеточием ": " и указывает название использованного протокола), следующие два слэша отделяют адрес сервера www.microsoft.com; а также) имя файла /readme. txt. Как правило, когда имеют в виду компьютер, на котором расположен ресурс, используют значение URL или URN, а когда обозначают ресурс полностью (тип, хост, путь) используют URI. Нет ошибки, если используется одно обозначение вместо другого, но обязательно следует пояснить, что оно значит в контексте.
Идентификатор URI может содержать не только имя ресурса, но и параметры, необходимые для его представления. Имя ресурса отделяется от строки параметров символом "?". Строка параметров состоит из символьных групп с постоянной структурой (лексем), разделяемых символом "&", каждая такая лексема состоит из имени параметра и его значения, разделенных символом "=", символ пробела " " заменяется знаком "+". Символы лексем, не входящие в набор символов ASCII, заменяются знаком "%" и шестнадцатеричным значением этого символа. Для указанного ресурса вся строка параметров является одним строковым параметром, поэтому тип, порядок следования или уникальность имен отдельных параметров строки не существенны. Например: http://www.exe.com/bm/scrshell.run? in=10&go=ok+and+ok&event=l&event=2 Этот идентификатор URI содержит 4 параметра, три из которых - чиcловые, а два имеют одно имя. Анализ и разбор значений отдельных параметров целиком возлагается на идентификатор URI, в данном примере на ресурс scrshell.run.
HyperText Markup Language (HTML) - это язык описания информации, хранимой в сети WWW.HTML-файл может содержать специальные коды, обозначающие присоединенную графическую, видео или аудио информацию или исполняемые коды среды отображения информации (Web-браузер - Java Script, Java). Для языков Java и JavaScript приложение Web-браузер представляет операционную систему или среду, в которой они выполняются, а Web-страница является ресурсом, выделенным для их работы. Эти языки не строят Web-страницу по данным пользователя, а используют ее как платформу для своих действий и действий пользователя. Когда Web-браузер получает доступ к этому файлу, он сначала интерпретирует закодированную в HTML-файле информацию, а затем в соответствующей форме представляет эту информацию пользователю.
Буквы "НТ" в названии протокола HTML обозначают "HyperText" - основную концепцию размещения информации в сети WWW.Документы HyperText содержат специальные связи, которые называются гиперссылками (hyperlinks) и размещаются в тексте документа. Гиперссылки позволяют пользователю не только переходить от одной части этого документа к другой, но и обращаться к другим связанным документам, размещенным в сети WWW.
Common Gateway Interface (CGI) - это стандарт расширения функциональности WWW, позволяющий WWW-серверам выполнять программы, аргументы которых может определять пользователь. Интерфейс CGI расширяет возможности пользователя и позволяет ему выполнять программы, ассоциированные с данной Web-страницей, предоставляя таким образом возможность получения динамической информации из WWW-сервера. Например, пользователь такого WWW-сервера может получить самую последнюю информацию о погоде, выполнив программу, которая запрашивает прогноз погоды на текущий момент из базы данных. Интерфейс CGI в основном играет роль шлюза между WWW-сервером и внешними исполняемыми программами. Он получает запрос от пользователя, передает его внешней программе и затем возвращает результаты пользователю через построенную динамически Web-страницу. При этом построенные Web-страницы могут коренным образом отличаться друг от друга, поскольку они формируются в прямой зависимости от параметров, определяемых пользователем.
Механизм интерфейса CGI
также является универсальным и может передавать данные между любыми WWW-серверами.
Поскольку интерфейс CGI
основан на исполняемых файлах, нет ограничений на тип программы, которая будет
в нем исполняться. Программа может быть написана на любом из языков программирования,
позволяющих создавать исполняемые модули. CGI-программа
также может быть написана с использованием командных языков операционных
систем, таких как Perl
или Shell. В
настоящее время широко используется технология активных серверных страниц ASP
(Active Server
Pages). По сути, эта
технология представляет применение того же самого стандарта CGI,
только на уровне объектно-ориентированного подхода к построению Web-страниц.
.3 Интерфейс информационного взаимодействия
программных приложений
Рассмотрим интерфейс взаимодействия программных приложений на примере HTTP. Интерфейс реализуется последовательно.
Первый этап - это когда HTTP-клиент (броузер) соединяется с сервером. Для этого он использует протокол TCP/IP, и соединение происходит с известным клиенту TCP-портом. Принятый номер порта HTTP - 80; для других сервисов определены другие TCP-порты.
Вторым этапом является запрос клиента: клиент передает заголовок запроса (Request header) и, возможно (в зависимости от метода), тело сообщения запроса. В заголовке обязательно указываются метод, URL и версия HTTP. Там может быть еще несколько необязательных полей, которые тоже дают серверу информацию о том, как обрабатывать запрос.
Третий этап - ответ сервера, который состоит из заголовка (Response header), в котором сервер указывает версию HTTP и код статуса, который может говорить об успешном или неуспешном результате и его причинах. После заголовка идет тело ответа, отделенное от заголовка пустой строкой.
Четвертым этапом является разрыв TCP/IP
соединения. Request
header может выглядеть
следующим образом:
GET /MyDoc. htm HTTP/1.1:
Keep-AliveAgent: Mozilla/3.0 (Win95; I): 212.54.196.226: image/gif,
image/x-bitmap,/jpeg,
*. *
Здесь: MyDoc. htm - имя запрашиваемого документа; GET - тип запроса; Host - IP-адрес; Accept - форматы данных "понимаемых" клиентом.
Request header, приведенный ниже, получен от документа, содержащего форму:
/Scripts/ReadData. pl HTTP/1.1:
http://212.54.196.226: Keep AliveAgent: Mozilla/3.0 (Win95; I): 212.54.196.226:
image/gif, image/x-bitmap,/jpeg, *. *type:
application/x-www-form-urlencodedlength: 38
Здесь: POST
- метод передачи данных из формы; Referer
- адрес web-страницы, с
которой пользователь перешел на документ, содержащий форму.; Content-type
- способ кодировки передаваемых данных; Content-length
- количество передаваемых данных (байт); FirstName,
LastName - имена полей
формы; Mary+Ann,
Sylvester - передаваемые
значения (пробел заменен знаком "+"). eb-сервер
отвечает на запрос браузера, посылая ему HTML-файл,
которому предшествует Response
header.
Типичный Response
header содержит следующие
данные:
HTTP/1.1 200 OK: Microsoft-IIS/4.0
Date: Tue, 04 Apr 2005 00: 26: 34
GMTtype: text/html
Этот заголовок сформирован сервером. Строка "200 OK" - это статус запроса. Если бы сервер не смог обработать запрос, то он сформировал бы сообщение об ошибке, например, "404 Object Not Found"; Content-type - тип содержимого. Браузер отображает документ (интерпретирует его код именно как HTML-код, поскольку Content-type имеет значение text/html) и ждет, когда клиент запросит (щелкнув по гиперссылке) очередную страницу этого сайта или перейдет на другой сайт. Если страница содержит изображение (например, формата jpeg), оно будет направлено web-сервером клиенту вместе с другим Response header, где Content-type будет иметь значение image/jpeg. Set-Cookie - устанавливает значение cпециальной информации записываемой на компьютере клиента. В этом поле хранится идентификатор текущей сессии.