Материал: Анализ поведения финансовых индексов с помощью методов математической статистики на примере курса Центрального банка валютной пары евро/рубль
ГЛАВА 2. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ СТАТИСТИЧЕСКИХ ДАННЫХ. ТОЧЕЧНЫЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
.1 Вычисление основных характеристик выборочных данных. Свойства полученных оценок
Основными характеристиками статистических данных являются среднее, мода,
медиана, размах, дисперсия, среднеквадратическое отклонение. Данные
характеристики можно получить с помощью инструмента «Описательная статистика»
(Рисунок 13).
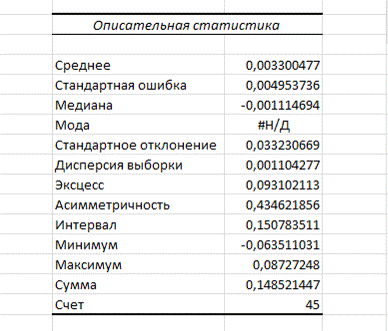
Рисунок
13. Описательная статистика
Математическое ожидание - это среднее значение СВ (центром распределения СВ). Такое значение может быть использовано вместо случайной величины в приблизительных расчетах или оценках. Математическое ожидание обозначается - М[Х] или mХ и рассчитывается по формуле:
![]()
![]() (2.1)
(2.1)
Стандартное отклонение, среднеквадратичное отклонение - это очень распространенный показатель рассеяния в описательной статистике. Данный показатель можно использовать в техническом анализе для обнаружения степени рассеяния цены анализируемого инструмента. Обозначается греческим символом Сигма «σ».
Алгоритм вычисления стандартного отклонения:
1. Вычисляем среднее арифметическое выборки данных;
. Отнимаем это среднее от каждого элемента выборки;
. Все полученные разницы возводим в квадрат;
. Суммируем все полученные квадраты;
. Делим полученную сумму на количество элементов в выборке;
. Вычисляем квадратный корень из полученного частного (именуемого дисперсией).
Общие формулы расчета выборочной дисперсии и выборочного среднего
квадратического отклонения (См.[2]):
![]()
![]() (2.2)
(2.2)
![]()
![]() (2.3)
(2.3)
Если
количество элементов в выборке превышает 30, то необходимо рассчитывать
исправленную дисперсию, уменьшив объем выборки на 1:
![]()
![]() (2.4)
(2.4)
Соответственно
число ![]()
![]() называется
исправленным выборочным средним квадратическим отклонением.
называется
исправленным выборочным средним квадратическим отклонением.
Результаты
расчетов представлены на Рисунке 14:

Рисунок
14.Расчет дисперсии и ср. квадрат-го отклонения
Чтобы судить о том, насколько точно проведенные измерения отражают состав генеральной совокупности, необходимо вычислить стандартную ошибку средней арифметической выборочной совокупности.
Стандартная ошибка средней арифметической характеризует степень отклонения выборочной средней арифметической от средней арифметической генеральной совокупности.
Стандартная ошибка средней арифметической вычисляется по формуле:
 , где (2.5)
, где (2.5)
s- стандартное отклонение результатов измерений, n - объем выборки.
В выборке отсутствует мода, так как значения не повторяются.
Асимметрия - это показатель симметричности / скошенности кривой распределения, а эксцесс определяет ее островершинность(См.[5])..
При левосторонней асимметрии ее показатель является положительным и в
распределении преобладают более низкие значения признака. При правосторонней -
показатель положительный и преобладают более высокие значения. У всех
симметричных распределений (в том числе и у нормального распределения) величина
асимметрии равна (или близка) нулю. Формула показателя асимметрии является
следующей:
![]() (2.6)
(2.6)
Если в распределении преобладают значения близкие к среднему арифметическому,
то формируется островершинное распределение. В этом случае показатель эксцесса
стремится к положительной величине. У нормального распределения эксцесс равен
(или близок) нулю. Если у распределения 2 вершины (бимодальное распределение),
то тогда эксцесс стремится к отрицательной величине. Показатель эксцесса
определяется по формуле(См.[9]):
![]() (2.7)
(2.7)
Таким образом, для нормального закона распределения, если эксцесс
положительный, то на графике функция распределения островершинная и для
отрицательных значений более пологая. Так можно установить отклонения заданного
закона от нормального.
2.2 Точечные оценки параметров предполагаемого закона распределения случайных величин методом максимального правдоподобия
В статистике существует два вида оценок: точечные и интервальные. Точечная оценка представляет собой отдельную выборочную статистику, которая используется для оценки параметра генеральной совокупности(См.[8]).
По гистограмме можно определить, что курс рубля имеет нормальное распределение, поэтому описывается параметрами a и σ.
Популярным статистическим методом, который используется для создания
статистической модели на основе данных, и обеспечения оценки параметров модели,
является метод максимального правдоподобия. Метод максимального правдоподобия
точечной оценки неизвестных параметров заданного распределения сводится к
отысканию максимума функции одного или нескольких оцениваемых параметров. Метод
максимального правдоподобия применим для оценки параметров. Найдем параметры a
и σ
нормального
распределения:
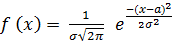 , (2.8)
, (2.8)
если в результате n испытаний величина X приняла значения x1,x2,..,xn.
Составим
функцию правдоподобия, учитывая, что q1 = a, q2 = s:
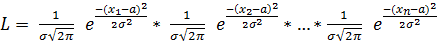 (2.9)
(2.9)
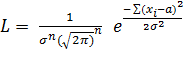 . (2.10)
. (2.10)
Найдем
логарифмическую функцию правдоподобия:
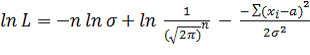 (2.11)
(2.11)
Найдем
частные производные по a и по σ:
![]()
![]() (2.12)
(2.12)
Приравняв
частные производные нулю и решив полученную систему двух уравнений относительно
a и ![]()
![]() ,
получим:
,
получим:
![]()
![]() , a
, a ![]()
![]() (2.13)
(2.13)
Итак,
с помощью метода максимального правдоподобия выяснили, что параметр ![]()
![]() , а
параметр
, а
параметр ![]()
![]() .
Заметим, что первая оценка несмещенная, а вторая смещенная.
.
Заметим, что первая оценка несмещенная, а вторая смещенная.
2.3 Восстановление теоретической функции распределения и плотности распределения СВ
Необходимо вычислить теоретическую вероятность и теоретическую частоту. Для этого напротив каждого интервала запишем соответствующую ему частоту. Воспользуемся функцией НОРМРАСП (х; среднее; стандартное_откл; интегральная). В качестве значений х взяли левую границу интервала для вычисления F(x(i)) и правую для F(x(i+1)); в качестве среднего берется выборочное среднее значение, полученное в описательной статистике. Стандартное же отклонение - показатель рассеивания значений случайной величины относительно ее математического ожидания, интегральная функция показывает логическое значение.
Для нахождения теоретической вероятности для интервального
статистического ряда вычисляется вероятность попадания в интервал по формуле
P(a<X<b)=F(b)-F(a). А чтобы получить теоретические частоты, умножим
теоретическую вероятность на объем выборки. Для удобства округлим данные
значения (Рисунок 15).
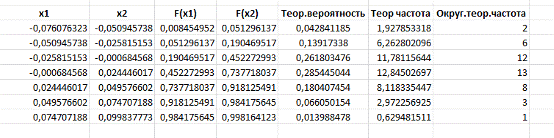
Рисунок
15. Восстановление теоритической функции
2.4 Построение доверительных интервалов для математического ожидания и дисперсии с надежностью 0,95
Доверительный интервал - термин, используемый в математической статистике при интервальной оценке статистических параметров, что предпочтительнее при небольшом объеме выборки. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надежностью.
Интервальная
оценка, доверительный уровень которой равен 95%, интерпретируется следующим
образом: если из генеральной совокупности извлечь все выборки, имеющие объем n,
и вычислить их выборочные средние, то 95% доверительных интервалов, построенных
на их основе, будут содержать математическое ожидание генеральной совокупности,
а 5% - нет. На практике, как правило, из генеральной совокупности извлекается
только одна выборка, а математическое ожидание генеральной совокупности ![]()
![]() не
известно. По этой причине невозможно гарантировать, что некий конкретный
доверительный интервал содержит величину
не
известно. По этой причине невозможно гарантировать, что некий конкретный
доверительный интервал содержит величину ![]()
![]() . Можно
лишь утверждать, что вероятность этого события равна 95%.
. Можно
лишь утверждать, что вероятность этого события равна 95%.
Найдем
доверительный интервал для среднего и среднеквадратического отклонения с
надежностью 0,95. Для начала посчитаем значение аргумента функции Лапласа - t (Рисунок
16).

Рисунок
16. Функция Лапласа
Данная оценка для курса рубля равна 0,057960064.
Затем находим точность интервальной оценки для среднего значения по формуле:
![]()
![]() (2.14)
(2.14)
Среднее
генеральной совокупности, имеющей нормальный закон распределения, с
доверительной вероятностью 1-a находится в доверительном
интервале:
![]()
![]() (2.15)
(2.15)
Таким образом получен доверительный интервал для математического ожидания (Рисунок 17).

Рисунок
17. Границы доверительных интервалов
Это значит, что математическое ожидание может находиться в пределах данного интервала при данном уровне надежности.
Построим доверительный интервал для неизвестной дисперсии нормально
распределенной генеральной совокупности (Рисунок 18). Оценкой для генеральной
дисперсии является выборочная дисперсия. Доверительный интервал находится по
следующей формуле:
![]()
![]() (2.16)
(2.16)
Значения
![]()
![]() и
и ![]()
![]() находятся
при помощи функции ХИ2ОБР(), исходя из следующих условий:
находятся
при помощи функции ХИ2ОБР(), исходя из следующих условий:
![]()
![]() (2.17)
(2.17)
![]()
![]() (2.18)
(2.18)
Рисунок
18. Нахождение левого и правого хи-квадрат значений
Таким образом получили доверительный интервал для дисперсии,
представленный на Рисунке 19.
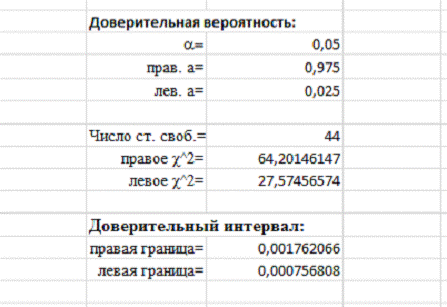
Рисунок
19. Доверительный интервал для дисперсии
Получили, что дисперсия выборки находится в интервале от 0,000756808 до 0,001762066.
Стоит вспомнить, что дисперсия отражает меру разброса данных вокруг средней величины, поэтому доверительный интервал показывает, что данные могут находиться в пределах найденного доверительного интервала.
ГЛАВА 3. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
.1 Проверка с помощью критерия согласия гипотезы о виде закона распределения СВ, уровень значимости α=0,05
финансовый индекс валютный статистика
Для оценки соответствия имеющихся экспериментальных данных нормальному закону распределения выполним следующие действия:
. Выдвигаем основную гипотезу ????0: случайная величина X подчиняется нормальному закону распределения.
. Формулируем альтернативную гипотезу ????1: случайная величина распределяется не по нормальному закону.
. Имея частоты и теоритические частоты, укрупняем их так, чтоб они были
больше либо равны 5 и затем рассчитываем критерий по формуле:
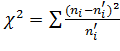 (3.1)
(3.1)
. Выбирается правосторонняя критическая область, и граница ее при заданном уровне значимости α и числом степеней свободы ???? = ???? − 1 − ????, где v - число частичных интервалов выборки или вариант, r - число параметров предполагаемого распределения находится по таблице критических точек распределения ????кр2 (????,????). Это значит, что если ????2 <????кр2 (????,????), то основная гипотеза принимается, в противном случае отвергается.
Произведя все действия по данному алгоритму, получаем для выборки по курсу рубля значения ????2 = 1,141 и ????крит. (0,05;6) = 1,145 (Рисунок 20). Это говорит о том, что гипотеза о нормальном распределении принимается с ошибкой 0,05.

Рисунок 20. Проверка гипотезы о нормальном законе распределения
.2 Построение графика функции плотности вероятности и сравнение его с гистограммой
Для построения графика функции плотности вероятности необходимы теоретические частоты, рассчитанные ранее. График плотности вероятности показывает, сколько единиц доходности приходится на единицу интервала.
Построим данный график для курса ЦБ валютной пары евро/рубль и сравним
его с гистограммой (Рисунок 21).
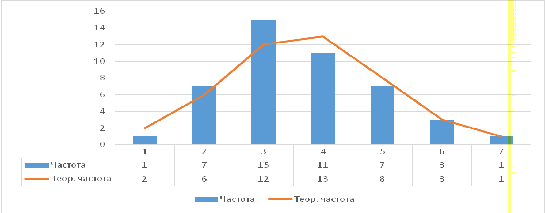
Рисунок
21.График функции плотности
Анализируя полученные графики, можно говорить о нормальном распределении СВ, так как значения частот и теоретических частот практически повторяют друг друга. Следовательно, нет причин утверждать обратное.