Материал: Алгоритм, эвристически строящий оптимальный граф для задачи децентрализованного поиска
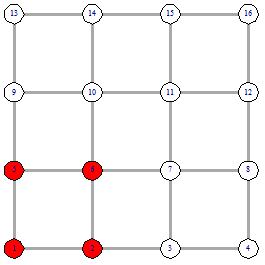
Рисунок 16 - Вершины для выбора
начала ребер
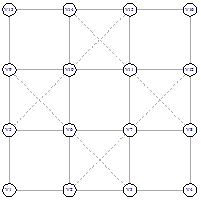
Рисунок 17 - Симметричные ребра
Принцип построения таких ребер описан ниже:
. У нас есть одно ребро с началом в вершине ![]() , а концом в вершине
, а концом в вершине ![]() .
.
. Для построения симметричного ребра считаем
его начало и конец
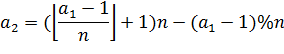
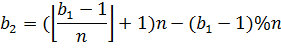
. Далее считаем третье ребро
![]()
![]()
. Последнее ребро
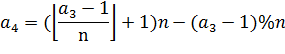
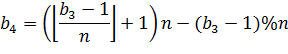
В примере на рисунке 17 ![]() , тогда
, тогда 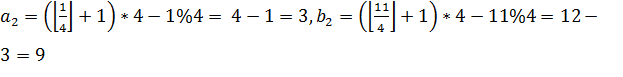 , получается ребро 3-9.
, получается ребро 3-9.
![]() , получаем ребро 5-15. И последнее
ребро
, получаем ребро 5-15. И последнее
ребро 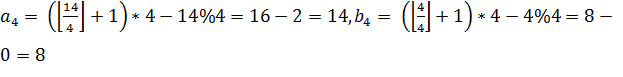 8-14. Таким образом при добавлении
или удалении ребра a-b, происходит удаление или добавление от 0 до 3х
симметричных ему ребер.
8-14. Таким образом при добавлении
или удалении ребра a-b, происходит удаление или добавление от 0 до 3х
симметричных ему ребер.
При использовании этого предположения количество вариантов изменения решения на каждом шаге заметно сокращается, поэтому локальный поиск приходит к локально оптимальному решению значительно быстрее.
Ниже представлен псевдокод этого алгоритма:
LocMin(G) //G - граф
. action* = -1
. O* = O(G)
. for action in actions
. O = calculate O for action
. if O < O*
. O* = O
. action* = action
. if action* == -1
. return G
. else
11. do action* for G
. return LocMin(G)
.2.2 Табу алгоритм
После изучения результатов, полученных при запуске алгоритма локального поиска, был имплементирован табу алгоритм для получения более лучшего решения. Для изменения алгоритма были добавлены новые входные параметры, такие как количество шагов алгоритма, на которое действие помещается в табу лист, и количество раз, когда алгоритм доходит до локального минимума без улучшений подряд. Второй параметр был введен для того, чтобы можно было закончить работу алгоритма.
Этот алгоритм отличается от предыдущего тем, что при достижении локального минимума он не останавливается, а делает действие, которое меньше всего ухудшает целевую функцию, затем заносит действие обратное сделанному в табу лист и продолжает работу. Тем самым мы можем сдвинуться с локального минимума и перейти в другой локальный минимум. Как показали результаты этот подход работает лучше предыдущего.
Однако из-за того, что количество действий на каждом шаге все еще очень большое даже после введения симметричности добавления и удаления ребер, было введено изменение в работу алгоритма. Теперь он ищет не самое оптимальное действие на каждом шаге, а первое действие, которое улучшает целевую функцию. Псевдокод работы этого алгоритма представлен ниже:
Tabu(G) //G - граф
. check tabu list
. action* = -1
. O* = O(G)
. for action in actions
. O = calculate O for action
. if O < O*
. O* = O
. action* = action
. break
. if action* == -1
. if O* ≥ min_O
. fails++
. if fails == number_of_fails
. return G
. else
. fails = 0
. min_O = Inf
. tabu_action = -1
. for action in G
. O = calculate O for action
. if O < min_O
. min_O = O
. tabu_action = action
. do tabu_action
25. add reverse tabu_action to tabu list for number_of_tabu steps
26. return Tabu(G)
. else
28. do action for G
. return Tabu(G)
В этом алгоритме на первом шаге идет проверка табу листа, во-первых, на уменьшение для каждого элемента количество шагов в табу листе, во-вторых, удаление тех элементов, счетчик которых достиг нуля.
Так же изменения произошли в первом цикле. Во-первых, выбирается не самое оптимальное действие, как говорилось ранее, а первое действие, которое приносит улучшение. Во-вторых, при выборе действия проверяется не лежит ли оно в табу, тем самым это помогает нам не возвращаться обратно в тот же локальный минимум. Однако если действие, которое лежит в табу листе, все же улучшает решение до такого, что оно лучше самого лучшего известного, то это действие совершается и удаляется из табу списка.
Небольшие отличия от предыдущего алгоритма есть в
моменте после нахождения локального минимума. Во-первых, идет проверка улучшили
мы или нет текущее оптимальное, если да, то алгоритм сохраняет новое
оптимальное, обнуляет количество неудач (fails) и продолжает работу. Если же
алгоритм не нашел решение лучшее, чем текущее оптимальное, то количество неудач
увеличивается на 1, сравнивается с глобальным параметром. Если количество
неудач сравнялось с фиксированным числом, то алгоритм останавливается. Если
алгоритм не остановлен, то программа находит действие, которое приводит к
наименьшему ухудшению целевой функции. Делает его и добавляет обратное действие
в табу список на определенное количество шагов.
1.2.3 Метод ветвей и границ
После получения результатов работы второго алгоритма, нужно было проверить предположение о существовании оптимального решения, которое содержит в себе только симметричные ребра. Так как и первый и второй алгоритм являются эвристическими, т.е. не дают гарантии нахождения глобально оптимального решения, то для проверки этой гипотезы был придуман метод ветвей и границ, который является точным алгоритмом, т.е. находит глобально оптимальное решение.
В этом методе уже рассматривались все возможные
действия, без симметричности. На рисунке 18 можно увидеть начало дерева для
графа 4х4.
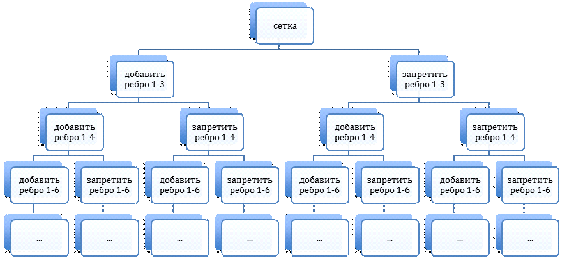
Рисунок 18 - Ветвление в методе
ветвей и границ
Таким образом это дерево представляет собой все возможные варианты существующих графов. Для того, чтобы не рассматривать все решения, используют границы. На каждом шаге идет подсчет нижней границы для определения наименьшего возможного значения целевой функции для текущего релаксированного графа.
Рассмотрим алгоритм подсчета нижней границы для
релаксированной задачи с матрицей смежности (таблица 1)
Таблица 1 - Матрица смежности
|
0 |
1 |
1 |
-1 |
-1 |
1 |
|
1 |
0 |
0 |
1 |
0 |
0 |
|
1 |
0 |
0 |
1 |
1 |
0 |
|
-1 |
1 |
1 |
0 |
0 |
1 |
|
-1 |
0 |
1 |
0 |
0 |
1 |
|
1 |
0 |
0 |
1 |
1 |
0 |
В таблице выше представлена матрица смежности графа с шестью вершинами, где 1 означает, что ребро есть; 0 означает, что ребра нет, но может быть проведено; -1 означает, что этого ребра не может быть в графе, построенном далее.
При вычислении нижней границы для такой матрицы
смежности алгоритм выполняет жадный поиск от каждой вершины до каждой. Но когда
алгоритм рассматривает соседей вершины, то он рассматривает не только те
вершины, с которыми она соединена, но и те вершины, с которыми она может быть
соединена (те, где 0 в матрице), при этом игнорирует вершины, с которыми нет
возможности соединиться (где -1 в матрице). Однако при подсчета сложности
поиска от одной вершины до другой в сумму целевой функции входят только те
вершины, до которых есть ребро. Например, если мы рассмотрим вторую вершину у
нее 2 соседа (1 и 4) и 3 возможных соседа (3,5 и 6). При поиске от нее алгоритм
рассмотрит все 5 вершин и выберет ту, которая ближе к финальной точке, но при
этом в целевую функцию внесет только 2 единицы.
1.3 Дополнения к алгоритмам
.3.1 Выбор между одинаковыми соседями
При проведении жадного поиска от одной вершины до другой может появится случай, когда у алгоритма будет несколько вершин с одинаковым расстоянием до финальной точки. Возникает вопрос, какую вершину выбрать для продолжения пути. В нашем алгоритме есть входной параметр, который отвечает за способ выбора одной вершины из множества одинаковых.
Эта переменная может принимать три значения:
· 0 - выбираем вершину с наименьшей степенью. Таким образом она внесет наименьший вклад в целевую функцию, что улучшит решение.
· 1 - выбираем вершину с наибольшей степенью. Хоть она и внесет в целевую функцию максимально возможный вклад, но при этом из нее можно будет рассмотреть наибольшее количество вершин для дальнейшего пути, что может сократить поиск.
· 2 - выбираем случайную вершину.
Рассмотрим на примере, как изменится значение
сложности жадного поиска.
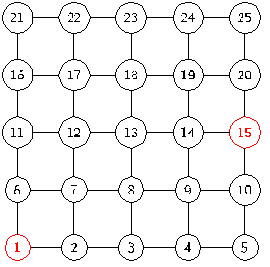
Рисунок 19 - начало поиска
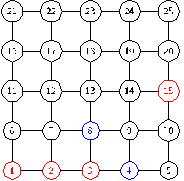
Рисунок 20 - выбор следующей вершины
На рисунке 20 видим, что расстояние от вершины 4 до
вершины 15 равно расстоянию от вершины 8 до 15, таким образом мы используем
входной параметр для определения следующей вершины. Если он равен 0, то
выбирается вершина 4, так как она имеет степень 3 ![]() 4 - степени вершины 8. Если он равен
1, то выбирается вершина 8. Если он равен 2, то с вероятностью 0.5 выбирается
вершина 4, с вероятностью 0.5 выбирается вершина 8.
4 - степени вершины 8. Если он равен
1, то выбирается вершина 8. Если он равен 2, то с вероятностью 0.5 выбирается
вершина 4, с вероятностью 0.5 выбирается вершина 8.
Различный выбор будет влиять на путь и значение
целевой функции. На следующих рисунках показано, как выглядит пути в каждом из
двух случаев.
|
|
|
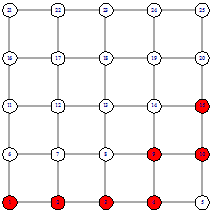 Рисунок 21 - Выбор 0
Рисунок 21 - Выбор 0
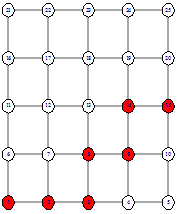 Рисунок 22 - Выбор 1
Рисунок 22 - Выбор 1
Теперь можно посчитать сложность поиска от вершины 1 до вершины 15. В первом случае сложность равна 12, во втором случае - 13.
.3.2 Стартовый граф
После тестирования локального и табу алгоритма на
различных входных графах-сетка было принято решение начинать не с пустого графа
и стараться добавить в него ребра, а начинать с полного графа и удалять ребра.
Так как чаще всего оптимальное решение предполагает добавление небольшого
количества ребер к графу-сетке, то если алгоритм начинает с полного графа, то
время работы увеличивается в несколько раз. Но результаты показывают, что
иногда, начиная с полного графа вместо сетки, можно прийти к наиболее лучшему
решению.
1.3.3 Функции расстояний
Для выбора функции вычисления расстояний между вершинами,
наш алгоритм использует входной параметр. Если параметр равен 1, то ![]() . Если параметр равен 2, то
. Если параметр равен 2, то 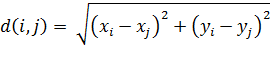 . Если параметр равен INFINITY, то
. Если параметр равен INFINITY, то ![]() . Также можно ввести любое
положительное число p, тогда
. Также можно ввести любое
положительное число p, тогда 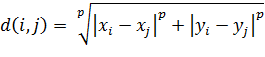 .
.
2. Программная реализация
Для реализации алгоритмов был выбран язык С++, так как он обладает быстротой выполнения и поддерживает объектно-ориентированное программирование.
Граф представляет собой класс, который содержит в себе
все необходимые данные, такие как на рисунке 23.

Рисунок 23 - Переменные класса Graph
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Рисунок 24 - структура Edge
представляет собой структуру данных, которая содержит в себе начало ребра (start), конец ребра (finish), количество шагов алгоритма, на которое это ребро помещается в табу список (tabuSteps) и действие, которое запрещено делать (tabuAction).
Также алгоритм принимает на вход файл конфигурации,
который содержит в себе параметры для алгоритмов. Эти параметры отвечают за
количество fails в табу алгоритме, количество табу шагов, на которое ребро
помещается в табу список и способ перехода к следующему шагу алгоритма (в
локальном и табу алгоритме). Способ перехода либо выбираем самое лучшее
действие из всех локальных переходов, либо первое действие, который уменьшает
нашу целевую функцию.
3. Результаты
Результаты табу алгоритма всегда лучше результатов алгоритма локального поиска, поэтому в результатах будут показаны только решения, которые были получены с помощью табу алгоритма.
Были проведены тесты на графах 4х4, 5х5, 6х6, 7х7 с
различными параметрами для выбора между одинаковыми вершинами и с началом как
от графа-сетки, так и от полного графа с использованием различных расстояний.
Названия рисунков представляют собой расстояние, переменная выбора вершины и
значение целевой функции.
4х4 (стартовый граф - граф-сетка)
|
|
|
|
|
|
|
|
|
|
|
|
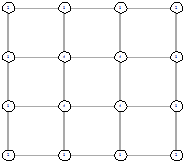 Рисунок 25 - L1, 0, 1728
Рисунок 25 - L1, 0, 1728
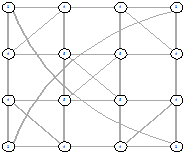 Рисунок 26 - L1, 1, 1828
Рисунок 26 - L1, 1, 1828
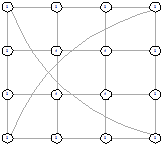 Рисунок 27 - L1, 2, 1782
Рисунок 27 - L1, 2, 1782
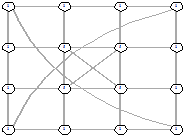 Рисунок 28 - L2, 0, 1800
Рисунок 28 - L2, 0, 1800
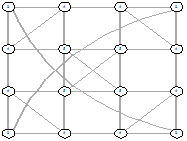 Рисунок 29 - L2, 1, 1820
Рисунок 29 - L2, 1, 1820
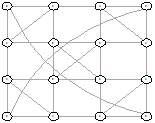 Рисунок 30 - L2, 2, 1814
Рисунок 30 - L2, 2, 1814
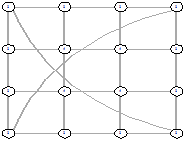 Рисунок 31 - LI, 0, 1816
Рисунок 31 - LI, 0, 1816
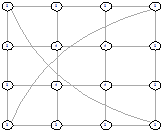 Рисунок 33 - LI, 2, 1846
Рисунок 33 - LI, 2, 1846