Материал: LS-Sb89574
2-й признак
Обучение и классификация на статистических данных
8
|
Класс A |
7 |
Класс B |
|
Класс C |
6 |
|
5 |
|
4 |
|
3 |
|
2 |
|
1 |
|
0
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
1-й признак |
|
|
|
|
|
Рис. 6.1
numobs = size(a,1)
sum(bad) / numobs % средняя ошибка классификации
ans =
0.3000
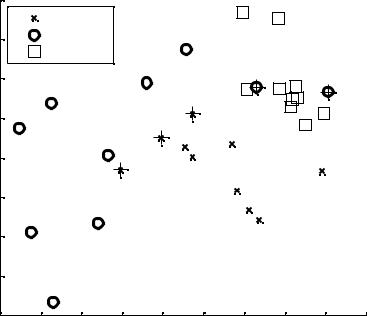
Из 30 объектов 30 %, или 10 объектов, классифицированы неправильно посредством линейной дискриминантной функции.
% Построим групповую диаграмму рассеяния gscatter для %исходных данных: классы A,B,C по 1-му и 2-му признакам.
gscatter(a(:,1),a(:,2),g,'','xos') % групповая диаграмма
% рассеяния для классов A,B,C по 1-му и 2-му признакам. xlabel('1-й признак');
ylabel('2-й признак');
legend('Класс A','Класс B','Класс C','Location','NW') title('{\bf Обучение и классификация на статистических данных}')
hold on
Теперь, наложив знак «+» на неверно классифицированные точки, можно увидеть ошибки классификации.
plot(a(bad,1), a(bad,2), 'k+');
hold off;
26
Пример 6.2 (рис. 6.2)
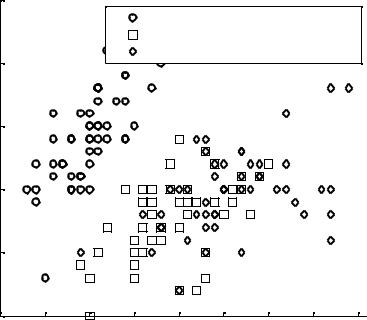
Исследуем, как измерения чашелистика (его длина – sepal length и
ширина – sepal width) различаются между видами. Будем использовать только два столбца, содержащие измерения чашелистика.
load fisheriris
gscatter(meas(:,1), meas(:,2), species,'rgb','osd'); xlabel('Длина чашелистика')
ylabel('Ширина чашелистика')
legend('Ирисы щетинистые (setosa)','Ирисы разноцветные
(versicolor)','Ирисы виргинские
(virginica)','Location','NE')
title('{\bf Классификация обучающих данных по ирисам Фише-
ра}')
Классифицируем эти данные, используя стандартный линейный метод.
linclass = classify(meas(:,1:2),meas(:,1:2),species); bad = ~strcmp(linclass,species);
numobs = size(meas,1); sum(bad) / numobs
ans =
0.2000 |
|
|
|
|
|
|
|
|
|
|
Классификация обучающих данных по ирисам Фишера |
||||||||
|
4.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Ирисы щетинистые (setosa) |
|
|||
|
|
|
|
|
Ирисы разноцветные (versicolor) |
||||
|
4 |
|
|
|
Ирисы виргинские (virginica) |
|
|||
|
|
|
|
|
|
|
|
|
|
чашелистика |
3.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ширина |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.5 |
|
|
|
|
|
|
|
|
|
2 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
7.5 |
8 |
|
4 |
||||||||
|
|
|
|
Длина чашелистика |
|
|
|
||
Рис. 6.2
27
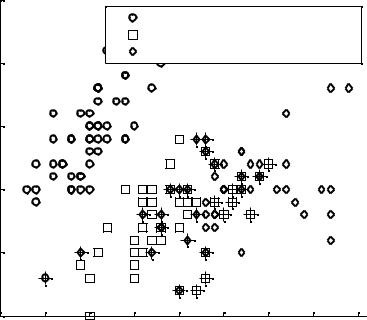
Из 150 образцов 20 %, или 30 образцов, классифицированы ошибочно с помощью линейной дискриминантной функции. Наложив знак «+» на неверно классифицированные точки, можно посмотреть, что это за образцы (рис. 6.3).
hold on;
plot(meas(bad,1), meas(bad,2), 'k+');
hold off;
Дискриминантная функция разделила «линиями» плоскость рис. 6.3 на области и присвоила различным областям принадлежность различным видам.
|
Классификация обучающих данных по ирисам Фишера |
||||||||
|
4.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Ирисы щетинистые (setosa) |
|
|||
|
|
|
|
|
Ирисы разноцветные (versicolor) |
||||
|
4 |
|
|
|
Ирисы виргинские (virginica) |
|
|||
|
|
|
|
|
|
|
|
|
|
чашелистика |
3.5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ширина |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.5 |
|
|
|
|
|
|
|
|
|
2 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
7.5 |
8 |
|
4 |
||||||||
|
|
|
|
Длина чашелистика |
|
|
|
||
Рис. 6.3
Как линейный, так и квадратичный дискриминантный анализ предназначены для ситуаций, для которых измерения по каждой группе имеют многомерное нормальное распределение. Часто это разумное допущение, но иногда делать такое допущение нежелательно или ясно видно, что оно недействительно.
Задание
1. Исследовать применение функции classify (линейный и квадра-
тичный варианты) к классам A, B, C из примера 1.1.
2. Исследовать применение функции classify (линейный и квадратичный варианты) к трем классам ирисов Фишера.
28
3.Оценить ошибки классификации во всех случаях и сравнить их с ошибками, полученными на занятиях.
4.Сделать вывод о важности числа признаков и вида решающей функции на качество классификации.
Порядок выполнения работы
1.Провести линейную классификацию массива а из примера 1.1 на классы A, B, C по всем 4 признакам. Оценить ошибки классификации.
2.Провести квадратичную классификацию массива а из примера 1.1 на классы A, B, C по всем 4 признакам. Оценить ошибки классификации.
3.Провести линейную классификацию ирисов Фишера на 3 класса по всем 4 признакам. Оценить ошибки классификации.
4.Провести квадратичную классификацию ирисов Фишера на 3 класса по всем 4 признакам. Оценить ошибки классификации.
Содержание отчета
1.Название, цель и задачи работы.
2.Тексты программ и изображения графических окон, которые требовалось сохранять в ходе выполнения работы.
3.Объяснение полученных результатов и выводы.
7.НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ КЛАССИФИКАЦИИ
Цели работы: знакомство с непараметрическими методами классификации для случая 2 классов; получение навыков работы с этим методом в си-
стеме MATLAB.
Основные положения |
|
Для непараметрических методов классификации входные |
векторы |
X = (x1, x2, ..., xn) представляются в виде векторов Y = ( y1, y2, ..., yn, |
yn+1) , где |
yi = xi для i = 1, ..., n, yn+1 = 1. Тогда разделяющая граница приобретает вид
n+1
∑ wk yk = 0 или в векторном виде WтY = 0. Для двух линейно непересека-
k =1
ющихся классов ϑ1 и ϑ2 можно найти такой весовой вектор W, для которого выполняется требование:
29
WтY > 0 для каждого Y ϑ1,
WтY < 0 для каждого Y ϑ2 .
Если все объекты второго класса умножить на –1, то для целей обуче-
ния вышеприведенное условие приобретает вид: WтY > 0 для каждого
Y (ϑ1 ϑ2) .
Рассмотрим процедуру последовательного обучения, когда обучающие объекты Y предъявляются последовательно, по одному, а весовой вектор W уточняется с каждым новым входным вектором Y. В этом случае если после предъявления объекта Y ϑ выполняется WтY > 0 , то W остается неизмен-
ным. Если же WтY < 0 , то вычисляется новое значение W, равное W', по формуле
W′ = W + cY ,
где c > 0 называется коэффициентом коррекции. Объекты предъявляются либо циклически, либо в случайном порядке до тех пор, пока не повторится результат испытания каждого из них. Начальное значение W произвольно (но не равно нулю).
Анализ данных с помощью непараметрических методов классификации в системе MATLAB
Реализация вышеприведенного алгоритма последовательного обучения в системе МАТЛАБ может быть проиллюстрирована на следующем примере.
Пример 7.1
Пусть даны 2 массива данных: class_1 и class_2.
class_1 |
|
class_2 |
|
||
0.4 |
0.9 |
0.6; |
0.6 |
0.3 |
1.0; |
0.6 |
0.6 |
1.2; |
0.4 |
0.4 |
1.2; |
0.8 |
0.3 |
1.2; |
0.6 |
0.5 |
0.7; |
0.6 |
0.5 |
1.0; |
0.5 |
0.5 |
0.8; |
0.5 |
0.6 |
1.1; |
0.3 |
0.2 |
0.6; |
0.5 |
0.7 |
1.0; |
0.2 |
0.2 |
0.7; |
0.7 |
0.3 |
1.2; |
0.4 |
0.2 |
0.8; |
0.6 |
0.6 |
1.5; |
0.8 |
0.3 |
0.6; |
0.7 |
0.7 |
1.0; |
0.5 |
0.6 |
0.4; |
0.4 |
1.0 |
0.4 |
0.9 |
0.3 |
0.5 |
По этим данным надо провести процедуру обучения и найти оптимальный весовой вектор по критерию отсутствия ошибок распознавания. Эту за-
30