Материал: LS-Sb89574
по видам могут быть разделены один от другого с использованием строковой матрицы видов – species (150 × 1)
setosa_indices = strcmp('setosa',species);
setosa = meas(setosa_indices,:);
Результирующая переменная setosa представляет собой матрицу (50 × 4) 50 наблюдений 4 измеренных переменных для ирисов setosa. Чтобы получить и отобразить первые 5 наблюдений данных по setosa, используем поясняющее индексирование:
SetosaObs = setosa(1:5,:)
SetosaObs =
5.1000 3.5000 1.4000 0.2000
4.9000 3.0000 1.4000 0.2000
4.7000 3.2000 1.3000 0.2000
4.6000 3.1000 1.5000 0.2000
5.0000 3.6000 1.4000 0.2000
Эти данные организованы в таблицу с подразумеваемыми названиями колонок «Длина чашелистика», «Ширина чашелистика», «Длина лепестка» и «Ширина лепестка». Подразумеваемые названия строк – это «Наблюдение 1», «Наблюдение 2», «Наблюдение 3» и т. д.
Аналогично, по 50 наблюдений по ирисам разноцветным – versicolor, и ирисам виргинским – virginica, могут быть выделены из контейнерной переменной измерений (meas):
versicolor_indices = strcmp('versicolor',species); versicolor = meas(versicolor_indices,:);
virginica_indices = strcmp('virginica',species); virginica = meas(virginica_indices,:);
Так как множества данных для этих трех видов имеют один и тот же размер, они могут быть переформатированы в один многомерный массив iris с размерностью 50 × 4 × 3.
iris = cat(3,setosa,versicolor,virginica);
Полученный массив iris по ирисам представляет собой трехслойную таблицу с одинаковыми подразумеваемыми заголовками строк и столбцов:
массивы setosa, versicolor и virginica. Вдоль третьей размерности – подразумеваемые имена слоев «Setosa», «Versicolor» и «Virginica». Чтобы получить и отобразить данные в многомерном массиве, надо использовать
6
поясняющую индексацию, как и для двумерных массивов. Получим первые 5 наблюдений признака длина лепестка (sepal lengths) в данных по setosa:
SetosaSL = iris(1:5,1,1)
SetosaSL =
5.1000
4.9000
4.7000
4.6000
5.0000
Многомерные массивы обеспечивают естественный путь к организации числовых данных, для которых наблюдения или конструкции экспериментов имеют много размерностей. Если бы, например, данные со структурой ирисов были бы собраны многими наблюдателями в множестве мест в множестве разных дат, то полные данные могли бы быть организованы в единственный многомерный массив с размерностями для «Наблюдатель», «Местоположение» и «Дата». Подобно этому экспериментальный план для m наблюдений и n p-мерных переменных может быть запомнен как массив m × n × p.
Задание
1.Освоить генерацию и ввод матриц данных в системе MATLAB. Освоить способы расчета статистических параметров массива данных.
2.Освоить основы расчета статистической связи между массивами
данных.
Порядок выполнения работы
1.Запустите систему MATLAB. В главном окне (в поле Current Directory, расположенном в верхнем правом углу) установите путь к рабочей папке.
2.Создайте 2 массива из 10 случайных чисел каждый по нормальному закону с параметрами, представленными в табл. 1.2
Таблица 1.2
Массив |
V1 |
V2 |
V3 |
V4 |
V5 |
V6 |
V7 |
V8 |
V9 |
V10 |
1 |
m = 2 |
m = 3 |
m = 4 |
m = 5 |
m = 6 |
m = 3 |
m = 5 |
m = 6 |
m = 7 |
m = 8 |
|
σ = 1 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 2 |
σ = 2 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 3 |
2 |
m = 6 |
m = 8 |
m = 7 |
m = 2 |
m = 2 |
m = 7 |
m = 2 |
m = 7 |
m = 3 |
m = 4 |
|
σ = 2 |
σ = 4 |
σ = 3 |
σ = 1 |
σ = 1 |
σ = 4 |
σ = 1 |
σ = 1 |
σ = 2 |
σ = 2 |
3.Вычислите выборочные оценки среднего значения и среднеквадратического отклонения каждого массива.
4.Вычислите коэффициент корреляции между вашими двумя массивами.
7
5. Вычислите выборочные статистические параметры двух первых признаков ирисов «Setosa» и коэффициент корреляции между ними.
Содержание отчета
1.Название, цель и задачи работы.
2.Тексты программ, которые требовалось сохранять в ходе выполнения
работы.
3.Объяснение полученных результатов и выводы.
2. СРАВНЕНИЕ ОДНОМЕРНЫХ ДАННЫХ
Цель работы: получение навыков сравнения одномерных данных в си-
стеме MATLAB.
Основные положения
Визуально близость и различие двух и более групп одномерных данных можно оценить с помощью графиков (plot), гистограмм (hist) и коробочко-
вых диаграмм (boxplot).
Гистограммы
Функция n = hist(Y) разбивает элементы вектора Y на 10 одинаковых и равномерно распределенных интервалов и возвращает число элементов, попавших в каждый интервал в виде вектора-строки. Функция n = hist(Y,x), где x –
вектор, возвращает распределение Y по ячейкам переменной x, причем центры этих ячеек равны значениям переменной x. Функция hist показывает распреде-
ление элементов Y в виде гистограммы с одинаковыми и равномерно распреде-
ленными ячейками между минимальным и максимальным значениями Y.
00 |
|
|
|
|
|
|
3000 |
|
|
|
|
|
|
2500 |
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
hist(yn) |
|
|
|
|
|
|
(yn) |
|
|
|
|
|
|
1500 |
|
|
|
|
|
|
hist |
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
500 |
|
|
|
|
|
|
00 |
-3 |
- |
-1 |
|
|
yn5 |
-4 |
0 1 2 |
3 4 |
||||
–4 –3 –2 |
–1 |
x |
||||
|
|
|
Рис. 2.1 |
|
|
|
|
30000 |
|
|
|
|
|
|
|
|
|
|
|
25000 |
|
|
|
|
|
|
|
|
|
|
|
20000 |
|
|
|
|
|
|
|
|
|
|
hist(yn) |
(yn) |
|
|
|
|
|
|
|
|
|
|
15000 |
|
|
|
|
|
|
|
|
|
|
|
hist |
|
|
|
|
|
|
|
|
|
|
|
|
10000 |
|
|
|
|
|
|
|
|
|
|
|
5000 |
|
|
|
|
|
|
|
|
|
|
|
001 |
2 |
3 |
4 |
5 |
|
6 |
7 |
8 |
9 |
10 |
|
1 |
2 |
3 |
4 |
5 |
x |
6 |
7 |
8 |
9 |
ynx |
|
|
|
|
|
Рис. 2.2 |
|
|
|
|
||
8
Пример 2.1
Выражение
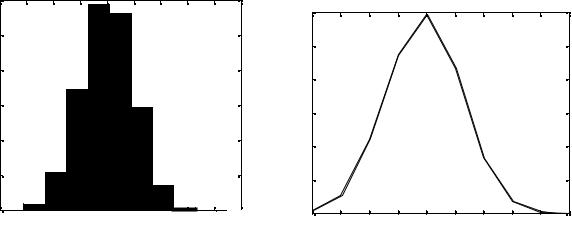
yn = randn(10000,1); hist(yn)
генерирует 10 000 случайных чисел и создает гистограмму с 10 ячейками,
распределенными вдоль оси x между минимальным и максимальным значе-
ниями yn, как показано на рис. 2.1.
Если нужно отредактировать график то, используя plot, вместо последней строки нужно написать:
plot (hist(yn))
В этом случае можно получить сплошной график, как на рис. 2.2.
Пример 2.2
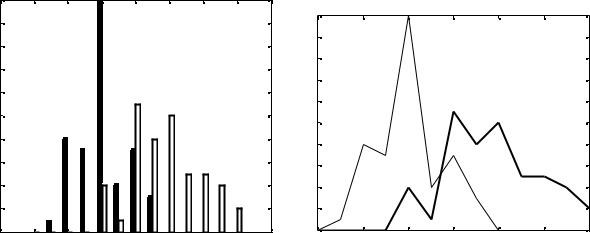
Сравним два вида ирисов (setosa и versicolor) по первому признаку c помощью их гистограмм (рис. 2.3):
load fisheriris
setosa_indices = strcmp('setosa',species);
S = meas(setosa_indices,:); % Результирующая переменная S
%представляет собой матрицу (50 х 4) 50 наблюдений 4 измеренных
%признаков для ирисов setosa.
versicolor_indices = strcmp('versicolor',species);
V = meas(versicolor_indices,:); % Результирующая переменная V
%представляет собой матрицу (50 х 4) 50 наблюдений
%4 измеренных признаков для ирисов versicolor. s1=S(:,1); % Первый столбец (признак) переменной S. v1=V(:,1); % Первый столбец (признак) переменной V.
s1v1=[s1 v1]% Объединение двух матриц в виде двух столбцов.
|
20 |
|
|
|
|
|
|
|
|
|
|
18 |
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
16 |
|
|
|
|
|
|
|
|
18 |
|
|
|
|
|
|
|
|
|
|
|
|
14 |
|
|
|
|
|
|
|
|
16 |
|
|
|
|
|
|
|
|
|
14 |
|
t) |
|
|
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
|
|
|
hist (s1v1, |
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
|
|
s1v1h |
||
10 |
|
|
|
|
|
|
|
10 |
||
|
|
|
|
|
|
|
|
|||
8 |
|
|
|
|
|
|
|
8 |
||
|
|
|
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
4 |
|
2 |
|
|
|
|
|
|
|
|
2 |
|
0 |
4 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
7.5 |
0 |
|
3.5 |
|
||||||||
|
|
|
|
|
t |
|
|
|
|
|
|
|
|
|
Рис. 2.3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
4 |
4.5 |
5 |
5.5 |
6 |
6.5 |
7 |
|
|
|
t |
|
|
|
|
|
|
Рис. 2.4 |
|
|
|
svmax=max(s1v1);
svmin=min(s1v1);
t=4:0.25:7 % Назначение последовательности t, которая
% устанавливает центры ячеек для построения гистограмм. hist(s1v1,t)% Построение гистограмм
Для получения линейного графика (рис. 2.4) вместо последней строки надо написать:
s1v1h=hist(s1v1,t) % Формирование гистограммы plot(t,s1v1h) % построение графика гистограммы
Коробочковая диаграмма
Коробочковая диаграмма (boxplot) – способ представления выборки в виде одной или нескольких коробочек с рисками (усами).
boxplot(X) выдает график, состоящий из прямоугольных коробочек и ри-
сок для каждого столбца матрицы Х. Коробочка имеет линии на значениях нижнего квартиля, медиане и верхнего квартиля. Риски представляют собой линии, расположенные за концами прямоугольника и показывающие основное распространение остальных данных. Выбросы – это данные, имеющие значения за пределами концов рисок. Если за пределами рисок данных нет, то на нижней риске ставится точка.
boxplot(x,G) выдает график, состоящий из прямоугольных коробочек и рисок для вектора х, образующего группы посредством G – переменной группировки, определенной как вектор, строковая матрица или матрица строк.
boxplot(...,'Param1', val1, 'Param2', val2,...) задает дополни-
тельные (необязательные) пары имя/значение параметра. В табл. 2.1 описаны некоторые параметры и их значения.
|
Таблица 2.1 |
|
|
|
|
Наименование параметра |
Значения параметра |
|
'notch' |
'on'для включения зазубрин (по умолчанию 'off') |
|
'whisker' |
Максимальная длина риски в единицах межквартильного |
|
размаха (по умолчанию 1,5) |
||
|
||
|
Буквенный массив или матрица строк, содержащие |
|
'labels' |
обозначения столбцов (если Х – матрица, то обозначения |
|
|
по умолчанию – это номер столбца) |
На графике с зазубринами зазубрины представляют робастную оценку неопределенности по поводу медиан при сравнении коробочек друг с другом. Коробочки, зазубрины которых не пересекаются (не накладываются), указывают, что медианы данных двух групп отличаются при уровне значимости 5 %.
10