Материал: LR_HM14_2018
На рис. 22 наведено поверхню “входи-вихід”, у відповідності з синтезованою нечіткою системою. Для виведення цього вікна необхідно використовувати команду View surface... меню View. Порівнюючи поверхні на рис. 9, рис. 16 і рис. 22 можна зробити висновок, що нечіткі правила досить добре описують складну нелінійну залежність. При цьому, модель типу Сугено точніша. Перевага моделей типу Мамдані полягає в тому, що правила бази знань є прозорими і інтуїтивно зрозумілими, тоді як для моделей типу Сугено не завжди зрозуміло які лінійні залежності “входи-вихід” необхідно використовувати.
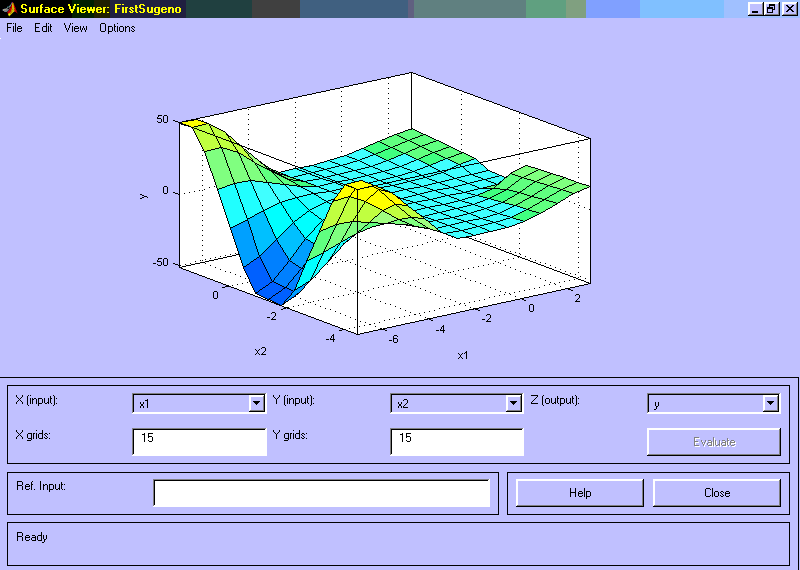
Рис. 22. Поверхня “входи-вихід” для системи типу Сугено.
3.4. Контрольні запитання
Яка структура типової системи нечіткого виведення?
Основні етапи нечіткого виведення.
Формування бази правил (знань) систем нечіткого виведення.
У чому відмінність методу нечіткого виведення за Сугено від методу нечіткого виведення за Мамдані?
Основні методи дефазифікації в процесі нечіткого виведення.
Лабораторна робота №4 Дослідження алгоритму нечіткої кластеризації
4.1 Мета роботи
Метою роботи є дослідження алгоритму нечіткої кластеризації та отримання практичних навичок вирішення завдань кластеризації методами нечіткої логіки.
4.2. Методичні вказівки з організації самостійної роботи студентів
Кластеризація – це об'єднання об'єктів в групи (кластери) на основі схожості ознак для об'єктів однієї групи і відмінностей між групами. Більшість алгоритмів кластеризації не спираються на традиційні для статистичних методів допущення; вони можуть використовуватися в умовах майже повної відсутності інформації про закони розподілу даних. Кластеризацію проводять для об'єктів з кількісними (числовими), якісними або змішаними ознаками. У цій роботі розглядається кластеризація тільки для об'єктів з кількісними ознаками. Початковою інформацією для кластеризації є матриця спостережень:
 ,
,
кожний рядок якої є значеннями n ознак одного з M об'єктів кластеризації.
Завдання кластеризації полягає в розбитті об'єктів з Х на декілька підмножин (кластерів), в яких об'єкти більш схожі між собою, чим з об'єктами з інших кластерів. У метричному просторі "схожість" зазвичай визначають через відстань. Відстань може розраховуватися як між початковими об'єктами (строчками матриці Х), так і від цих об'єктів до прототипу кластерів. Зазвичай координати прототипів заздалегідь невідомі – вони знаходяться одночасно з розбиттям даних на кластери.
Існує багато методів кластеризації, які можна класифікувати на чіткі і нечіткі. Чіткі методи кластеризації розбивають початкову множину Х об'єктів на декілька непересічних підмножин. При цьому будь-який об'єкт з Х належить тільки одному кластеру. Нечіткі методи кластеризації дозволяють одному і тому ж об'єкту належати одночасно декільком (або навіть всім) кластерам, але з різним ступенем приналежності. Нечітка кластеризація в багатьох ситуаціях "природніша", ніж чітка, наприклад, для об'єктів, розташованих на межі кластерів.
Методи кластеризації також класифікуються по тому, чи визначена кількість кластерів заздалегідь чи ні. У останньому випадку кількість кластерів визначається в ході виконання алгоритму на основі розподілу початкових даних. При виконанні роботи ми розглянемо алгоритм нечітких с-середніх, що розбиває дані на наперед задане число кластерів, а потім алгоритм субтрактивної (гірської) кластеризації, який не вимагає завдання кількості кластерів.
Для підготовки до лабораторної роботи слід опрацювати конспект лекцій за темою: «Методи нечіткої кластеризації» а також відповідний матеріал з переліку рекомендованої літератури [3, 4].
4.3. Методичні вказівки та короткі відомості щодо виконання лабораторної роботи
Вивчити основні поняття, визначення і алгоритми нечіткої кластеризації.
Скласти матрицю початкових даних D у вигляді текстового файлу.
За допомогою функції findcluster (пакет MatLab) провести нечітку кластеризацію отриманої матриці D методом нечітких с-середніх (FCM).
За допомогою функції findcluster (пакет MatLab) визначити кількість кластерів отриманої матриці D методом subtractive.
Проаналізувати отримані результати.
Оформити звіт за результатами лабораторної роботи та захистити його.
1. Fcm алгоритм нечіткої кластеризації
Алгоритм нечіткої кластеризації називають FCM-алгоритмом (Fuzzy Classifier Means, Fuzzy C-Means). Метою FCM-алгоритму кластеризації є автоматична класифікація множини об'єктів, які задаються векторами ознак в просторі ознак. Іншими словами, такий алгоритм визначає кластери і, відповідно, класифікує об'єкти. Кластери представляються нечіткими множинами і, крім того, межі між кластерами також є нечіткими.
FCM-алгоритм кластеризації припускає, що об'єкти належать всім кластерам з певною ФП. Ступінь приналежності визначається відстанню від об'єкту до відповідних кластерних центрів. Даний алгоритм ітеративно обчислює центри кластерів і нові ступені приналежності об'єктів.
Для
заданої множини K
вхідних
векторів
![]() і N
кластерів
і N
кластерів![]() ,
що виділяються, передбачається, що
будь-який
належить будь-якому
із ступенем приналежності,
,
що виділяються, передбачається, що
будь-який
належить будь-якому
із ступенем приналежності,
![]() де
j
– номер кластера, а k
– вхідного вектора.
де
j
– номер кластера, а k
– вхідного вектора.
Приймаються до уваги наступні умови нормування:
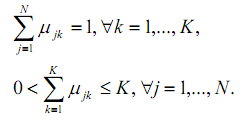
Мета алгоритму полягає в мінімізації суми всіх зважених відстаней
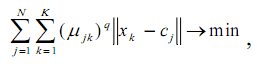
де q– фіксований параметр, що задається перед ітераціями.
Для досягнення вищезгаданої мети необхідно розв’язати наступну систему рівнянь:
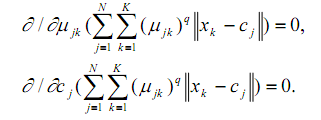
Спільно
з умовами нормування
![]() дана система диференціальних рівнянь
має наступний розв’язок:
дана система диференціальних рівнянь
має наступний розв’язок:
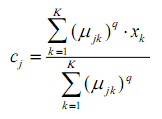
(зважений центр тяжіння (center of gravity – cog)) і
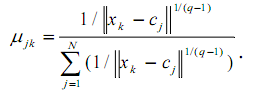
2. Розв’язання задачі нечіткої кластеризації з використанням MatLab методом fcm
У системі MatLab для розв’язання завдання нечіткої кластеризації на основі алгоритму FCM може бути використаний спеціальний графічний інтерфейс кластеризації, що викликається функцією findcluster. Розглянемо особливості його застосування.
Функція findcluster призначена для виклику графічного інтерфейсу програми нечіткої кластеризації для методу нечітких с-середніх і методу субтрактивної кластеризації (subtractive clustering). Вона може бути викликана в одному з наступних форматів: findcluster або findcluster('file.dat'). У першому випадку функція findcluster викликає графічний інтерфейс GUI програми для виконання нечіткої кластеризації алгоритмом FCM і/або нечіткій субтрактивної кластеризації. При цьому необхідно завантажити в робочу область початкові дані із зовнішнього файлу за допомогою кнопки Load Data (рис. 4.1).
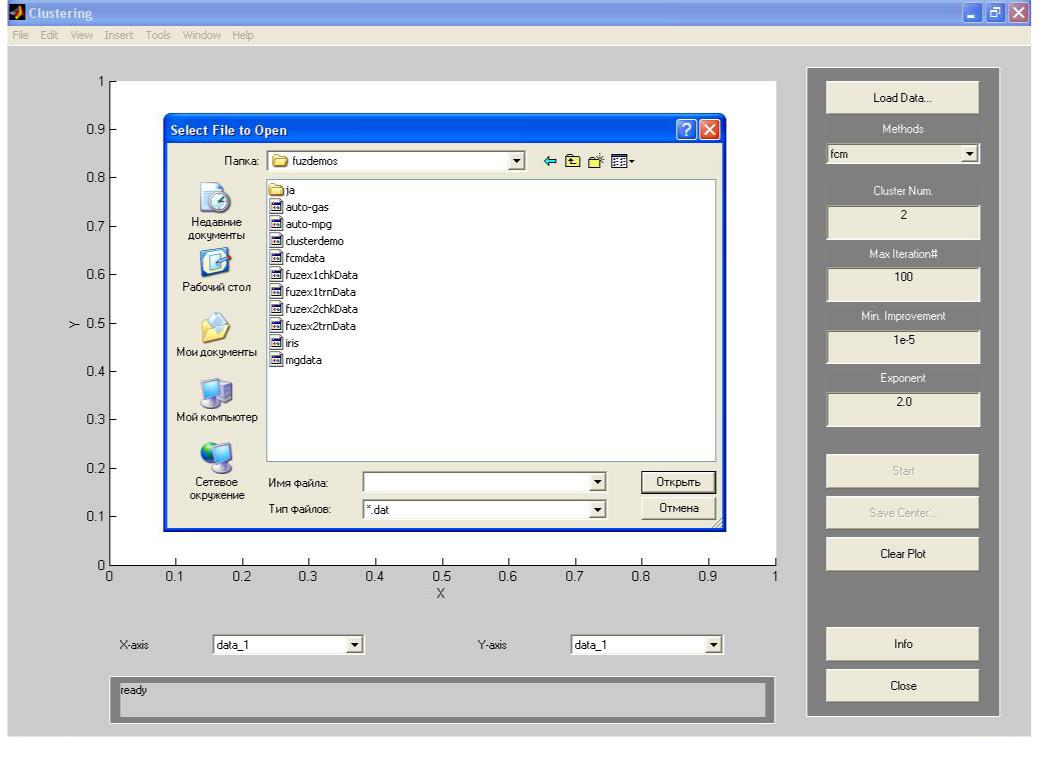
Рис. 4.1.
У другому випадку функція findcluster('file.dat') викликає графічний інтерфейс, а в робочу область автоматично завантажуються дані кластеризації із зовнішнього файлу file.dat. При цьому на графіку відображаються значення матриці даних для перших двох ознак. Результат із завантаженими початковими даними із зовнішнього файлу fcmdata.dat представлений на рис. 4.2.
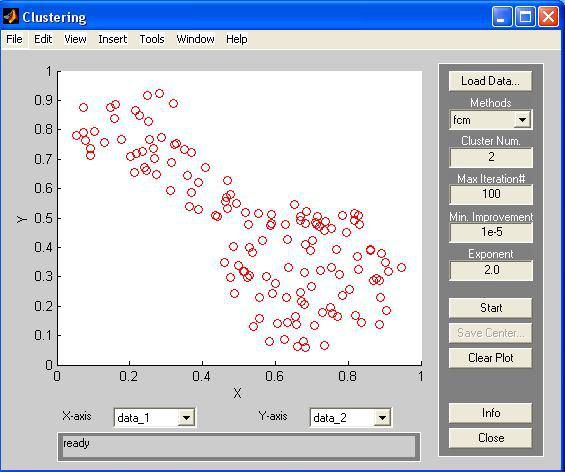
Рис. 4.2.
Вибір методу нечіткої кластеризації здійснюється за допомогою списку Methods. Для кожного з методів нечіткої кластеризації у відповідних рядках введення встановлені значення параметрів алгоритмів за умовчанням. В цьому випадку вони мають наступні значення:
- Cluster Num: число шуканих нечітких кластерів с, дорівнює с=2;
- Max Iteration#: максимальне число ітерацій s, дорівнює s=100;
- Min Improvement: параметр збіжності алгоритму е, дорівнює е=0.00001;
- Exponent: експоненціальна вага m для розрахунку матриці нечіткого розбиття, дорівнює m=2.
Ці значення можуть бути змінені користувачем. Для цього необхідно встановити курсор введення у відповідне поле і набрати потрібні цифри з урахуванням допустимих значень параметрів.
Після натиснення на кнопку Start починає роботу відповідний алгоритм нечіткої кластеризації з параметрами, встановленими за умовчанням або зміненими користувачем. Результати роботи алгоритму відображаються на графіку (рис. 4.3). Знайдені центри кластерів зображені чорними квадратиками, і їх координати можна зберегти в зовнішньому файлі з метою подальшого аналізу, натиснувши кнопку Save Center…
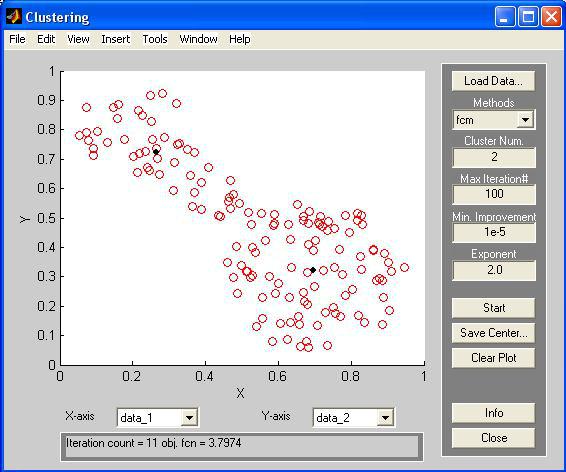
Рис. 4.3.
Параметр iteration count показує кількість ітерацій, а obj.fcn – відповідне значення цільової функції.
3. Розв’язання задачі нечіткої кластеризації з використанням MatLab методом субтрактивної кластеризації (subtractive clustering)
Іноді кількість нечітких кластерів, необхідних для роботи алгоритму FCM, апріорі є невідомою. В цьому випадку доцільно використовувати реалізований в системі МatLab так званий алгоритм субтрактивної кластеризації.
Ідея методу субтрактивной кластеризації полягає в тому, що кожна точка даних передбачається в якості центра потенційного кластеру, після чого слід обчислити деяку міру здатності кожної точки даних представляти центр кластеру. Ця кількісна міра заснована на оцінці щільності точок даних навколо відповідного центра кластеру.
Цей алгоритм, який є узагальненням методу кластеризації Р. Ягера (R. Yager), заснований на виконанні наступних дій:
вибрати точку даних з максимальним потенціалом для представлення центру першого кластера;
видалити всі точки даних в околиці центра першого кластера, величина якої задається параметром Influence, щоб визначити наступний нечіткий кластер і координати його центру.
Ці дві процедури повторюються до тих пір, поки всі точки даних не опиняться всередині околиць радіусу Influence шуканих центрів кластерів. В загальному випадку малі значення цього параметра приводять до знаходження малого числа великих по кількості точок кластерів.
Якнайкращі результати можливо отримати при значеннях між 0.2 і 0.5 (за умовчанням 0.5).
Розглянемо розв’язання задачі визначення кількості кластерів для множини початкових даних, показаних на рис. 2, з використанням графічного інтерфейсу кластеризації. Для цього завантажимо початкові дані із зовнішнього файлу командою findcluster('fcmdata.dat'), виберемо метод кластеризації subtractive в списку Methods і натиснемо кнопку Start. Решту параметрів залишимо запропонованими за умовчанням:
- quashFactor – параметр, що використовується як коефіцієнт для множення тих значень (Influence), які визначають околицю центру кластера. Це здійснюється з метою зменшення впливу потенціалу граничних точок, що розглядаються як частина нечіткого кластера (за умовчанням це значення дорівнює 1.25);
- acceptRatio – параметр, що встановлює потенціал як частину потенціалу центру першого кластера, вище за яке інша точка даних може розглядатися як центр іншого кластера (за умовчанням це значення дорівнює 0.5);
- rejectRatio – параметр, що встановлює потенціал як частину потенціалу центру першого кластера, нижче за яке інша точка даних не може розглядатися як центр іншого кластера (за умовчанням це значення дорівнює 0.15).
Результат розв’язання задачі субтрактивної кластеризації зображений на рис. 4.4 і містить три нечітких кластера.
На закінчення слід зазначити, що результати нечіткої кластеризації мають наближений характер і можуть слугувати лише для попередньої структуризації інформації, що міститься в множині початкових даних.
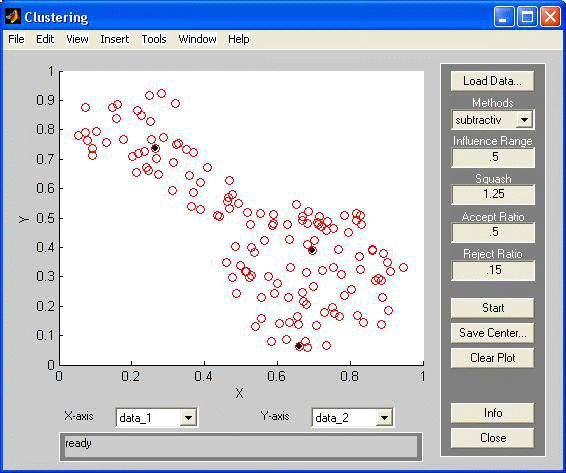
Рис. 4.4.
При розв’язанні завдань нечіткої кластеризації, потрібно пам'ятати про особливості і обмеження процесу вимірювання ознак у сукупності об'єктів кластеризації. Оскільки нечіткі кластери формуються на основі евклидової метрики, відповідний простір ознак повинен задовольняти аксіомам метричного простору. В той же час для пошуку закономірностей в проблемній області, що мають неметричний характер, необхідно використовувати спеціальні засоби і інструментарій, що розроблений для інтелектуального аналізу даних (Data Mining).
4.4. Контрольні запитання
Дайте визначення нечіткого покриття і нечіткого розбиття нечіткої множини.
Сформулюйте в загальному вигляді задачу нечіткого кластерного аналізу.
Опишіть алгоритм розв’язання задачі нечіткої кластеризації методом нечітких с-середніх (FCM).
Опишіть алгоритм розв’язання задачі нечіткої кластеризації методом субтрактивної кластеризації (subtractive clustering).
Як впливають на якість розв’язку додаткові параметри алгоритму кластеризації?
Охарактеризуйте засоби розв’язання задачі нечіткої кластеризації в середовищі MatLab?