Материал: 1_9продолжАБРАКАДАБРА
Продолжение 1.9.
«Сцепляется» с началом 1.9.
Кодируется текст АБРАКАДАБРА!, содержащий 12 символов, включая специальный символ !, означающий конец текста. В строящемся дереве Хаффмана будет использоваться специальный узел нулевого веса, отображающий все символы алфавита, включая символ !, не встретившиеся до сих пор. Будем обозначать этот узел как !. Первые вхождения символов кодируются по текущему дереву Хаффмана кодом узла !, за которым следует код собственно нового символа в специальной кодировке. Рассмотрим ее далее отдельно, а пока обозначим такой код подчеркиванием символа.
Перед началом кодирования и передатчик (кодировщик), и приемник (декодировщик) знают лишь используемый алфавит (набор элементарных сообщений), в том числе количество символов алфавита (это важно для кодирования первых вхождений). Рассмотрим последовательно все 12 шагов кодирования: А1Б2Р3А4К5А6Д7А8Б9Р10А11!12.
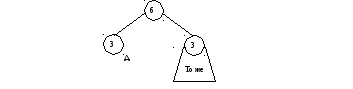
1) Изначально все веса равны нулю, поэтому первая буква А кодируется непосредственно специальным кодом А, а текущее дерево Хаффмана становится таким:

2) Следующий символ Б встречается впервые и кодируется по текущему дереву как 0Б (поскольку 0 – код узла !). Будем далее для краткости записывать это как Б 0Б. Полученное дерево изображено на рисунке слева.
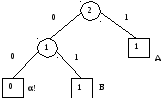
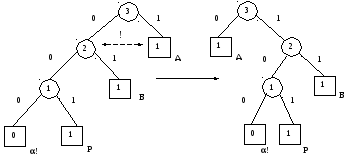 3)
Следующий символ Р также встречается
впервые, поэтому Р 00Р.
Дерево Хаффмана получается заменой
листа ! на
поддерево с листьями !
и Р и соответствующим изменением
весов. Однако здесь уже для сохранения
свойства упорядоченности дерева
требуется перевешивание узлов в
соответствии с ранее описанным алгоритмом,
что и изображено на рисунке
3)
Следующий символ Р также встречается
впервые, поэтому Р 00Р.
Дерево Хаффмана получается заменой
листа ! на
поддерево с листьями !
и Р и соответствующим изменением
весов. Однако здесь уже для сохранения
свойства упорядоченности дерева
требуется перевешивание узлов в
соответствии с ранее описанным алгоритмом,
что и изображено на рисунке
4) Второе вхождение символа А, поэтому А 0.
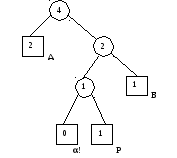

 5)
Первое вхождение символа К.
Кодирование: К 100
К. При модификации дерева
перевешивается узел Б со своим
предшественником в упорядоченной
последовательности.
5)
Первое вхождение символа К.
Кодирование: К 100
К. При модификации дерева
перевешивается узел Б со своим
предшественником в упорядоченной
последовательности.
6) А 0.
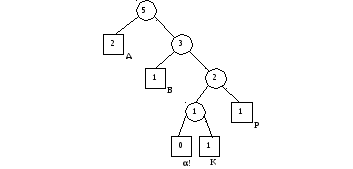
7) Первое вхождение Д 1100Д. После перевешивания получаем дерево
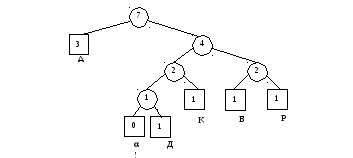
8) А 0. В дереве изменяется только вес узла А и корня.
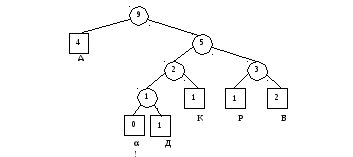 9)
Б 110. В
дереве меняются местами узлы Б и Р.
9)
Б 110. В
дереве меняются местами узлы Б и Р.
10) Р 110. Обратите внимание, что девятый символ Б и десятый символ Р кодируются одним и тем же кодом – 110. Структура дерева не изменяется.
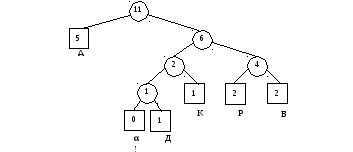 11)
А 0. Дерево
принимает вид
11)
А 0. Дерево
принимает вид
12) ! 1000!. Этот символ означает конец текста. Перестраивать дерево не требуется.
Итак, входная последовательность АБРАКАДАБРА! порождает следующий код (для наглядности между кодами букв вставлены пробелы):
А 0Б 00Р 0 100К 0 1100Д 0 110 110 0 1000!
А А А Б Р А
Вспомним
теперь о специальной кодировке, которая
должна использоваться при кодировании
первых вхождений символов. Будем считать,
что появление первого вхождения любого
из n символов алфавита
равновероятно. В этом случае в качестве
оптимального можно взять следующий
код: пусть
![]() ,
где
,
где
![]() ,
тогда символ i
кодируется как (p + 1)-битное
представление числа i 1,
если 1 i 2q,
иначе как p-битное
представление числа i q 1.
Поясним этот код. Рассмотрим максимально
ровное бинарное дерево при
,
тогда символ i
кодируется как (p + 1)-битное
представление числа i 1,
если 1 i 2q,
иначе как p-битное
представление числа i q 1.
Поясним этот код. Рассмотрим максимально
ровное бинарное дерево при
![]() ,
например такое, как на следующем рисунке.
,
например такое, как на следующем рисунке.

Из рисунка понятно, почему символы с номерами от 1 до 2q кодируются
(p + 1)-битным кодом, а символы с остальными номерами – p-битным.
Пусть в данном примере входной алфавит состоит из 33 букв русского алфавита и символа ! конца сообщения. Всего 34 символа. Поскольку 34 = 25 + 2, т. е. p = 5 и q = 2, то четыре первые буквы А, Б, В и Г кодируются 6-битными кодами 000000, 000001, 000010 и 000011 соответственно, а остальные 30 букв кодируются 5-битными кодами чисел от 2 до 31, т. е. кодами от 00010 до 11111, и такой код является префиксным.
В данном примере в исходное сообщение входят только буквы А, Б, Д, К, Р и символ !, а коды их первых вхождений есть
код (А) = 000000, код (Б) = 000001,
код (Д) = 00010, код (К) = 01001, код (Р) = 01111, код (!) = 11111.
Таким образом, код(АБРАКАДАБРА!) получается заменой в строке
А0Б00Р0100К01100Д011011001000!
букв А, Б, Д, К, Р и символа ! на указанные коды:
00000000000010001111010001001011000001001101100100011111.