Материал: 1_8ДХафф
1.8. Энтропийная оценка средней длины кода
Рассмотрим
зависимость оптимального значения
Lmin(W)
от входного набора
![]() .
Здесь удобно использовать вероятностную
интерпретацию: pi
– вероятность появления символа i
во входном потоке, а L(p, l) = i=1..n pi li
– математическое ожидание длины кода
случайно выбранного символа. Оптимальное
значение L(p, l)
обозначим как Lmin(p).
.
Здесь удобно использовать вероятностную
интерпретацию: pi
– вероятность появления символа i
во входном потоке, а L(p, l) = i=1..n pi li
– математическое ожидание длины кода
случайно выбранного символа. Оптимальное
значение L(p, l)
обозначим как Lmin(p).
Определение.
Энтропия распределения вероятностей
![]() есть
есть
![]() (считаем, что
(считаем, что
![]() ).
).
Лемма 1.
Для любых распределений вероятностей
p
и
![]() справедливо неравенство
справедливо неравенство
![]() .
.
Равенство имеет
место тогда и только тогда, когда
![]() для всех
для всех
![]() .
.
Доказательство.
![]()
![]()
![]() .
.
Так как функция
![]() строго выпукла и касательной к кривой
строго выпукла и касательной к кривой
![]() в точке (0, 0) служит прямая y = x,
то справедливо неравенство
в точке (0, 0) служит прямая y = x,
то справедливо неравенство
![]() ,
причем при
,
причем при
![]() имеем даже
имеем даже
![]() .
Поэтому
.
Поэтому
![]() ,
,
что и требовалось доказать.
Утверждение.
Пусть
![]() для
для
![]() и Lmin(p)
– средняя длина слова некоторого
оптимального префиксного кода с априорным
распределением p.
Тогда
и Lmin(p)
– средняя длина слова некоторого
оптимального префиксного кода с априорным
распределением p.
Тогда
![]() .
.
Доказательство.
1) Докажем левое неравенство
![]() .
Пусть
.
Пусть
![]()
длины кодовых слов некоторого оптимального
префиксного кода. Положим
длины кодовых слов некоторого оптимального
префиксного кода. Положим
![]() и
и
![]() .
Можно рассматривать
.
Можно рассматривать
![]() как некоторое распределение вероятностей.
Из неравенства Крафта следует, что
Q 1,
а поэтому log2 Q 0.
Из леммы вытекает, что
как некоторое распределение вероятностей.
Из неравенства Крафта следует, что
Q 1,
а поэтому log2 Q 0.
Из леммы вытекает, что
![]()
![]() .
.
В случае, когда
Q = 1
и
![]() для всех i,
получим
для всех i,
получим
![]() .
Это, следовательно, справедливо, если
.
Это, следовательно, справедливо, если
![]() и
и
![]() ,
т. е.
,
т. е.
![]() .
.
2) Перейдем к
доказательству правого неравенства
![]() .
В общем случае
.
В общем случае
![]() ,
поэтому выберем
,
поэтому выберем
![]() .
Отсюда вытекает, что
.
Отсюда вытекает, что
![]() и, в частности,
и, в частности,
![]() .
Тогда
.
Тогда
![]() и
и
![]() ,
т. е. для набора
,
т. е. для набора
![]() выполняется неравенство Крафта, а
следовательно, существует префиксный
код с длинами кодовых слов
выполняется неравенство Крафта, а
следовательно, существует префиксный
код с длинами кодовых слов
![]() .
Итак,
.
Итак,
![]() ,
,
что и требовалось доказать.
Следствие
из теоремы:
![]() .
.
Приведенное
доказательство позволяет сделать
конструктивный вывод: если взять
![]() и построить, исходя из неравенства
Крафта, префиксный код для набора
и построить, исходя из неравенства
Крафта, префиксный код для набора
![]() ,
то этот код будет достаточно хорошим,
поскольку для него
,
то этот код будет достаточно хорошим,
поскольку для него
![]() .
.
Отметим, что для
неравномерного распределения p
энтропия H(p)
может быть мала и средняя длина кода
окажется тоже малой. Действительно,
энтропия равномерного распределения
вероятностей
![]() есть
есть
![]() .
Если же рассмотреть неравномерное
распределение вероятностей, например
такое, что
.
Если же рассмотреть неравномерное
распределение вероятностей, например
такое, что
![]() для i 1..n 1
и
для i 1..n 1
и
![]() ,
то для него
,
то для него
![]() .
Например, при n =1024
получим
.
Например, при n =1024
получим
![]() ,
тогда как при равномерном распределении
H(p) = 10.
,
тогда как при равномерном распределении
H(p) = 10.
1.9. Динамическое кодирование по Хаффману
Рассмотренный (статический) метод Хаффмана имеет некоторые недостатки, влияющие на эффективность его применения, например:
-
двухпроходность алгоритма (сначала вычисляются веса
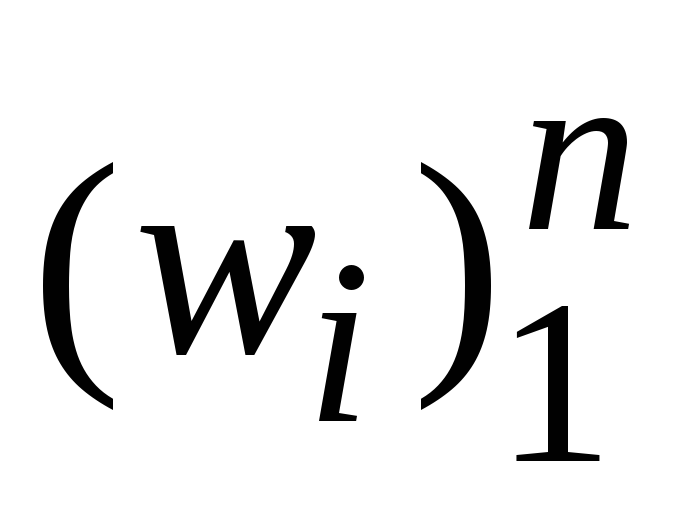 ,
затем строится дерево (код) Хаффмана);
,
затем строится дерево (код) Хаффмана); -
необходимость передавать кодовое дерево вместе с последовательностью закодированных сообщений.
Этих недостатков
лишен так называемый динамический
(однопроходный) метод Хаффмана, в котором
кодирование осуществляется «на лету».
При этом используется динамически
изменяющееся дерево Хаффмана (изменяющийся
префиксный код). Кодировщик
и декодировщик
работают в этом случае синхронно: начиная
с пустого дерева, они строят одно и то
же дерево Хаффмана, причем кодировщик
– по последовательности сообщений, а
декодировщик – по последовательности
кодовых слов. Можно представить этот
процесс в виде схемы, изображенной на
рис. 1.1 (здесь ДХ(i) –
дерево Хаффмана, построенное по
последовательности символов (сообщений)
![]() ).
).
ci
ai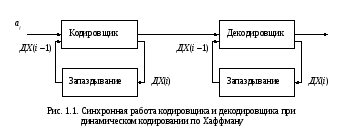
Кодировщик выполняет две основные операции: 1) построение кодового слова ci для очередного символа ai по текущему дереву Хаффмана ДХ(i 1); 2) перестройку текущего ДХ(i 1) в новое ДХ(i) с учетом поступившего символа ai. Декодировщик также выполняет две операции: