Материал: Інформатика_1 (методи побудови алгоритмівта та їх аналіз)
Мал. 76
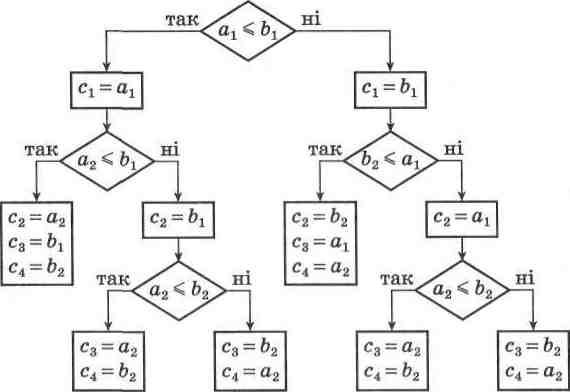
Проблема полягає лише у виборі значения х. Найчастіше в якості х обирають середній за розміщенням у масиві елемент, як це зображено на малюнках 73-76.
ПДкавим є випадок, коли в якості осьового елемента є наймен-ший або найбільший елемент даного фрагмента. Таку ситуацію можна спостерігати на малюнку 73, а. Однак це не є перешкодою. Розглянемо її детальніше. Осьовим елементом е х = а2- 06, гра-ницями фрагмента масиву, який упорядковується, і = 1, / = 3. Згідно з алгоритмом цикл while a[i] < х do i := i + 1 (a1> x) завершиться значениям i = 1, а цикл while x < a[j] do j := j - 1 - значениям j = 2 (x < a3, x ■ a2). Подальше виконання алгоритму при i <= j = true призведе до обміну значень а1 = 18 ** а2 ■= 06, тобто елементи масиву набудуть значень а1 = 06 і аг - 18. Далі за алгоритмом буде збільшено значения і та зменшено значения j: і - 2, / -= 1. Ці нові значения лівої і правої меж підмасиву, який сортується, дають змогу завершити цикл (і > j •= true). Таким чином, пересвідчилися, що навіть у випадку, коли осьовий елемент х є найменшим або найбільшим елементом фрагмента ма-
179
сиву, який сортується, це не є перешкодою для коректного сорту-вання.
Реалізація запропонованого алгоритму буде мати рекурсивный вигляд. А саме фрагмент алгоритму, який виконує обмін елементів масиву відносно граничного елемента х, оформимо у вигляді рекурсивно! процедуры sort.
procedure sort (L, R: integer); var i, j: integer; c, x: real; begin
i:=L;j:=R; x:=a[(L + R)div2]; repeat while a[i]<x do i := i + 1; while x<afj] do j :=j-1; if i<=jthen begin
с:=а[і];а[і]:=аШ;аШ:=с; i:=i + 1;j:=j-1; end; until i > j;
if j > L then sort (L, j); if i<R then sort (i, R) end;
Виклик цієї рекурсивної процедури в основній програмі можна здійснити так:
sort (1, n);.
Для визначення оцінки ефективності роботи методу швид-кого сортування ще раз нагадаємо описаний вище алгоритм.
Оскільки ми кожного разу поділяли масив на дві частини, а отримані дві частини знову на дві, то це приводить до думки про існування логарифмічної залежності, яка була визначена і під час аналізу алгоритму пірамідального сортування. «Гли-бина» такого поділу, або кількість поділів, буде log2n. Можна представити процес поділу масиву навпіл у вигляді дерева ре-курсії на схемі (мал. 77).
3 малюнка 77 видно, що кількість поділів дорівнює log2n, а кількість елементів на кожному рівні поділу становить п еле-ментів. Тому результуюча оцінка методу швидкого сортування становить n\og2n.
Ми розглянули алгоритм швидкого сортування для випад-ку, коли на кожному кроці рекурсії поточний масив ділиться практично навпіл. Це і дає схему, наведену на малюнку 77, та логарифмічну оцінку ефективності такого методу.
180

/\ /\ /\ /\
log2n п/8 п/8 п/8 п/8 п/8 п/8 п/8 п/8
*- п
> п
--*■ п
11111111111111111-*/»
Мал. 77
Однак саме коректність поділу є основою такої оцінки. Роз-
глянемо варіант іншого поділу масиву: у пропорції . Тоді
л-1 схема поділу масиву на частини матиме такий вигляд (мал. 78):
/"\ """""'"
1 ,л-1 -»• п
/ \
1 ,п-2 - -► л-1
/ \
п
1 ,п-3 > л-2
/ ч
1
3
2
1 1
Мал. 78
3 дерева рекурсії, зображеного на малюнку 77, можна зроби-ти висновок, що оцінка методу швидкого сортування при такому алгоритмі поділу масиву на частини складає 0(п2). Тобто цей поділ є чи не найгіршим. Отже, висновок мае бути таким: від принципу поділу масиву на дві частини залежить ефектив-ність роботи алгоритму швидкого сортування. I найкращим по-ділом є поділ навпіл, якого треба прагнути, використовуючи метод швидкого сортування.
Швидке сортування вважається одним із найкращих методів. При тестуванні цього алгоритму необхідно для п = 10, п = 100, п = 1000, п = 10 000, п = 30 000 згенерувати такі вхідні дані:
181
-
вхідний масив уже впорядкований необхідним чином;
-
вхідний масив є частково впорядкованим;
-
вхідний масив упорядкований у зворотному порядку;
-
елементи вхідного масиву розміщені випадковим чином.
/ Запитання для самоконтролю
-
На якому з методів прямого сортування базується метод швид-кого сортування?
-
У чому полягає ідея алгоритму швидкого сортування?
-
Який елемент може відігравати роль осьового елемента і яке йо-го призначення в методі швидкого сортування?
-
Продемонструйте роботу методу швидкого сортування на влас-ному прикладі одновимірного масиву.
-
Запишіть фрагмент алгоритму у вигляді тексту Pascal-програми, який реалізує обмін елементів масиву відносно визначеного осьового елемента.
-
Продемонструйте роботу алгоритму, наведеного в запитанні 5, на конкретному прикладі, обґрунтовуючи переміщення індексів / та/.
-
Вибір якого з елементів масиву в якості осьового є найефектив-нішим?
-
Продемонструйте роботу алгоритму, наведеного в запитанні 5, на власному прикладі у випадку, коли осьовий елемент є най-більшим або найменшим у поточному фрагменті масиву, що впорядковуеться.
-
Як виглядатиме рекурсивний алгоритм методу швидкого сортування мовою Pascal?
-
Як здійснити виклик рекурсивної процедури, що реалізує алгоритм методу швидкого сортування, з тіла основної програми?
-
Якою є оцінка ефективності роботи алгоритму швидкого сортування? Обґрунтуйте свою відповідь.
Завдання
-
Реалізувати у вигляді програми алгоритм швидкого сортування заданої послідовності за зростанням.
-
Модифікувати алгоритм, представлений у завданні 1, так, щоб сортування відбувалося за спаданиям.
-
Протестувати реалізовані у завданнях 1-2 алгоритми для масиву 15, 4, 10, 8, 6, 9, 16, 1, 7, 3, 11, 14, 2, 5, 12, 13.
-
Проаналізувати покрокове виконання завдання 3 для впо-рядкування заданої вхідної інформації за зростанням, контро-люючи зміну значень змінних i, j та х.
-
Шдібрати власні тести, які доводять переваги й показу-ють недоліки методу швидкого сортування при п > 100.
-
Зробити письмовий аналіз завдань 3-5.
182
СОРТУВАННЯ ПОСЛІДОВНОСТЕЙ
Досі розглядалися сукупності елементів, кількість яких відповідала розміру пам'яті комп'ютера. Але інколи виникає потреба працювати із сукупностями, які неможливо заван-тажувати в пам'ять комп'ютера у масиви. Такі сукупності знаходяться у файлах на зовнішніх носіях. Але оскільки для реалізації подальших алгоритмів потрібний прямий доступ до елементів цих файлів, то зрозуміло, що і файли ці повинні бути прямого доступу. Такими можуть бути в Pascal типізовані файли. Означену сукупність елементів, записаних у файли прямого доступу, будемо називати послідовністю.
Наступні два методи були описані Н. Віртом саме для сорту-вання даних, які з-за свого розміру не можуть бути розміщені в пам'яті комп'ютера. Однак сьогоднішні технічні можливості комп'ютерів знімають саме ці фактори. Тому переваги методів сортування послідовностей, зазначені свого часу Н. Віртом, на сьогодні вже втратили свою актуальність.
Методи, що розглядатимуться далі, можна виконувати як на масивах, так і на файлах. Однак слід зазначити, що робота з файлами, тобто запис у файли та читання з файлів, займає пев-ний час, який пов'язаний з пошуком самого файла на диску, необхідного елемента у файлі. Тому наступні два методи можна рекомендувати застосовувати на файлах лише у випадку вико-ристання великих об'ємів інформації, які не можна розмістити в пам'яті сучасного комп'ютера.
Надалі розглянемо методи злиття послідовностей на прикладах масивів.
Метод прямого злиття
Почнемо з відповіді, на перший погляд, на дуже просте запитання: який за довжиною масив можна вважати стовід-сотково відсортованим? Відповідь однозначна: масив, який складається з одного елемента.
Справді, такий масив стовідсотково є одночасно впорядко-ваним як за зростанням, так і за спаданиям. А як із двох упо-рядкованих масивів, що складаються з одного елемента кож-ний - at i bj, зробити один упорядкований масив ct, i = 1,2? Відповідь однозначна: якщо аг < bv то сл = av с2 - bv у про-тилежному випадку ct= bv сг = av Таким чином злилися дві впорядковані послідовності, що містили по одному елементу, в упорядковану послідовність з двох елементів.
Чи можна продовжити далі міркування щодо злиття двох упо-рядкованих послідовностей, що містять по два елементи, в одну впорядковану послідовність, що складатиметься з чотирьох елементів? Цей алгоритм буде вже складнішим, ніж поперед-ній, але все одно досить прозорим. Як ми діяли б інтуїтивно?
183
Будемо міркувати так. Якщо а, < Ь,, то с1 - av інакше -с1 = bv Наступний вибір для перенесения значения елемента в с2 буде відбуватись між аг та Ь1 у першому випадку та між а1 та Ьг - у другому. Як не заплутатися в тому, який елемент з масиву а та масиву b записаний на даному кроці в масив с? На якому елемента в кожному з масивів ми зупинилися? У даному випадку найпростіше навести схему алгоритму злиття двох упорядкова-них послідовностей, у кожній із яких по два елементи, в одну упорядковану послідовність із чотирьох елементів (мал. 79).
Мал. 79
Тепер уже вимальовується алгоритм для злиття впорядкова-них послідовностей із чотирьох елементів у впорядковану послідовність із восьми елементів. Але запис такого алгоритму стае вже надто заплутаним. Варто знайти якусь закономірність.
Для розв'язання даної ситуації треба ввести змінні, які бу-дуть поточними індексами для роботи з кожним із цих масивів. Отже, для масиву а визначимо індекс і, для масиву Ь - індексу', а для масиву с - індекс k.
n:=4;
i:=1;j:=1;k:=1; while (i <= n) and (j <= n) do begin
if a[i]<b[j] then begin
elk] := a[i]; inc(i); inc(k) end
 else
begin
else
begin
с[к]:=ЬШ; inc(j); inc(k) end; end; while i <= n do {Дописування у кінець масиву с залишків масиву а.}
begin
c[k]:=a[i]; inc(i); inc(k) end; while j <= n do {Дописування у кінець масиву с залишків масиву Ь.)
begin
c[k] := ьш; lnc(j); inc(k) end;
Тепер цей алгоритм можна застосувати для злиття будь-яких двох однакових за кількістю елементів упорядкованих масивів в один, також упорядкований. У новому злитому ма-сиві буде 2га елементів.
Але насправді маємо зовсім іншу ситуацію. У нас немає двох масивів, які треба злити в один, а є один масив, який треба упо-рядкувати.
А для чого ж ми стільки розбиралися з попереднім алгоритмом? Застосуемо його наступним чином. Розбиватимемо наш масив на частини, які зливатимемо разом. Злиті частини можна записувати в новий масив, а потім переписувати його на «свое» місце в заданий.
Але й цю процедуру можна спростити: продовжити заданий масив удвічі, тобто наперед зарезервувати для нього місце на 2га елементів. Тепер після першого злиття результат буде міс-титися у частині а„ + 1, ••-, а2п, і ЇЇ можна зробити вхідним ма-сивом для наступного кроку злиття. Результат другого кроку злиття будемо писати в першу половину масиву ах, ..., ап. Таким чином, на кожному кроці злиття заданого масиву дов-жиною в га елементів будемо робити послідовні кроки по пе-ремиканню злиття першої половини масиву ау, ..., а2п у другу, і навпаки.
Контроль за тим, яка з половин масиву а,, ..., а2л є вхідною, а яка вихідною, здійснюватиме логічна змінна up. Коли вона набуватиме значения true, то це означатиме, що вхідним є перша половина масиву а:, ..., a2n, a вихідним - друга, коли false, то навпаки. При цьому на кожному такому кроці збільшувати-мемо розміри фрагментів масиву, що зливаються, за принципом р := р * 2.
Але й це ще не все. Рухатися вздовж масиву, наприклад, а,, ..., ал, міняючи індекси з крокомр, - зайві ігри. Оскільки
185
маємо справу зі структурою прямого доступу, то час доступу до будь-якого елемента однаковий. Давайте зробимо так, щоб лег-ше було скласти алгоритм. Уведемо таку індексацію: iraj- ін-декси елементів, що сортуються, для ситуації, коли злиття від-бувається у першій половині масиву, k та I - відповідно для другої половини масиву. Тому слід зміну індексу і починати з 1, a k — з п + 1, зміну індексу у — з останнього елемента п, a I — з 2п. А далі під час злиття і та k збільшуватимемо, a ;' та I - зменшу-ватимемо, поки вони не зійдуться посередині.
Для зручності роботи з індексами писати результат злиття будемо так само: у початок вихідної частини масиву, потім у кі-нець, і т. д., сходячись до центра.
Розглянемо описаний алгоритм покроково на прикладі (мал. 80).
|
; |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
|
44 |
55 |
12 |
42 |
94 |
18 |
06 |
67 |
|
|
|
|
|
|
|
|