Материал: Інформатика_1 (методи побудови алгоритмівта та їх аналіз)
/ Запитання для самоконтролю
-
Сформулюйте задачу пошуку необхідної інформаціі в заданій групі значень, використовуючи рекурсивність.
-
Як можна застосувати алгоритм бінарного пошуку у випадку, коли шукана інформація у сформульованій задачі присутня у за-даній послідовності лише один раз?
-
Обґрунтуйте некоректність роботи алгоритму бінарного пошуку для випадку існування кількох шуканих елементів у заданій по-слідовності.
-
Чому рекурсивний алгоритм бінарного пошуку вирішує проблему, поставлену в попередньому запитанні? Обґрунтуйте свою відповідь.
118
-
Запишіть алгоритм і текст Pascal-програми рекурсивного бі-нарного пошуку.
-
Як можна здійснити виклик рекурсивно! процедури бінарного пошуку з тіла основної програми?
-
Чим пояснюеться включения граничного елемента а[т] при поділі поточної послідовності на дві частини у перегляд як лівої, так і право! частин, що надалі досліджуватимуться?
-
Поясніть умову завершения рекурсивного пошуку L + 1 О R. Обґрунтуйте свою відповідь.
-
Коли використання алгоритму рекурсивного пошуку є ефектив-ним?
-
Коли використання алгоритму рекурсивного пошуку може стати неефективним?
-
Оцініть умови ефективності використання лінійного й рекурсивного бінарного пошуків декількох шуканих елементів у великій послідовності заданих елементів.
-
Якою є оцінка ефективності роботи рекурсивного бінарного пошукового алгоритму?
Завдання
-
Розробити й реалізувати алгоритм бінарного рекурсивного пошуку збоїв системи підрахунку виготовлених деталей.
-
Виконати завдання 1 для .N=10:1112345678. Визначити, скільки рекурсивних викликів процедури бінарного пошуку використано для отримання відповіді.
-
Виконати завдання 1 для N •= 10: 123456788 8. Визначити, скільки рекурсивних викликів процедури бінарного пошуку використано для отримання відповіді.
-
Виконати завдання 1 для N = 10: 123444567 8. Визначити, скільки рекурсивних викликів процедури бінарного пошуку використано для отримання відповіді.
-
Виконати завдання 1 для N = 50 і для рівномірно роз-поділених збоїв системи в заданій послідовності. Визначити, скільки рекурсивних викликів процедури бінарного пошуку використано для отримання відповіді.
-
Зробити порівняльний аналіз завдань 2-5.
-
Виконати завдання 1 для N ■ 10: 1111111111. Визначити, скільки рекурсивних викликів процедури бінарного пошуку використано для отримання відповіді.
-
Виконати завдання 7, використавши алгоритм лінійного пошуку.
-
Провести аналіз виконання завдань 7-8 щодо ефективнос-ті використання рекурсивного алгоритму.
10. Виконати завдання 7-9 для N = 1000.
119
ПОШУКОВІ АЛГОРИТМИ НА БІНАРНИХ ДЕРЕВАХ
Задача про частотний словник
Розглядаючи структуры даних, ми вже ознайомилися з такою структурою, як дерево:
type Prt = ANode; Node = record
data: <тип > ; left, right: Prt; end;
Нагадаємо, що дерево пошуку будується за такою ознакою: лівим нащадком для кожного числа у вершині дерева буде мен-ше за нього число, а правим - більше.
Ми ознайомилися також із тим, яким чином у дереві відбу-вається читання та запис інформації.
Однією з найпоширеніших задач, яка супроводжує виконан-ня операцій на деревах, є «обхід» дерева. Прикладом такої задач! є процедура друкування дерева, яка наводилася раніше, коли розглядалася структура даних «дерево».
Ще одна задача - пошукова, або, як ще кажуть, пошук за унікальним ключей. Спираючись на принцип побудови дерева пошуку, рух по ньому можна здійснювати від кореня по лівому або правому піддереву лише на підставі одного порівняння з ключей поточної вершини:
function locate (х: integer; t: Prt): Prt; begin
while (t <> nil) and (t\key <> x) do if t".key<x then t :=t\right else t := r.left; locate := t end;
Зрозуміло, що, в разі відсутності ключа в дереві, отримаємо результат locate (х, t) := nil.
Зауважимо, що висота дерева, яке складається з п вершин, не буде перевищувати log2n.
Доповнимо всю згадану інформацію про бінарні дерева ще однією задачею, яка в літературі носить назву «частотного словника», або «пошуку по дереву з включениям». Якщо рані-ше ми розв'язували подібні задачі на вже побудованих деревах, то ця задача розглядає ситуацію, коли дерево постійно росте.
Умова задачі полягає в тому, щоб у наперед заданій послі довності визначити частоту входження кожного елементг (ключа). Це означав, що будь-який елемент треба шукати в де реві, причому вважаючи, що початковий стан дерева — по
120
рожнє дерево. Якщо елемент знайдено, то лічильник його вхо-джень збільшується, якщо ж ні, то цей новий елемент вклю-чається у дерево з початковим значениям лічильника 1.
Згідно з умовою задачі дещо змінимо тип, який описує дерево пошуку із включениям:
typeWprt = "Node; Node = record
data: <тип > ; count: word; left, rigth: Wprt; end;
Як бачимо, зміни відбулися у структурі елементів, 3 яких складається дерево. 3'явилося ще одне поле count - лічильник входження відповідного елемента в задану послідовність.
Процедура search повинна бути організована таким чином, що коли пошук заходить у «глухий кут» (піддерево - nil), то у цьому разі відбувається включения на це місце значения х.
procedure search (х: integer; var р: Wprt); begin
if p = nil then
begin new (p); with pA do begin
key := x; count := 1; left := nil; right := nil; end; end else
if x<pA.key then search (x, pMeft)
else if x > p\key then search (x, p\right)
else pA.count := p\count + 1 end;
Нехай root - змінна, що означає корінь дерева. Тепер фрагмент програми, за допомогою якого інформація читається із вхідного файла і, за необхідності, включається в дерево, мати-ме такий вигляд:
read (f, х); while not eof (f) do begin
search (x, root); read (f, x) end;
Для виведення вмісту побудованого дерева на екран монітора можна використати процедуру PrintTree (root, 0), що наводила-ся раніше при ознайомленні зі структурою даних «дерево».
121
Спочатку для прикладу розглянемо таку послідовність да-них, що містяться у файлі та трапляються в ньому лише один раз:
21,8,9,11,15,19,20,21, 7,3,2,1, 5,6,4,13,14,10,12,17,16,18.
Згідно з нашою програмою першим елементом є значения п, а далі розміщені елементи заданої послідовності. Дерево по-шуку матиме такий вигляд (мал. 38):
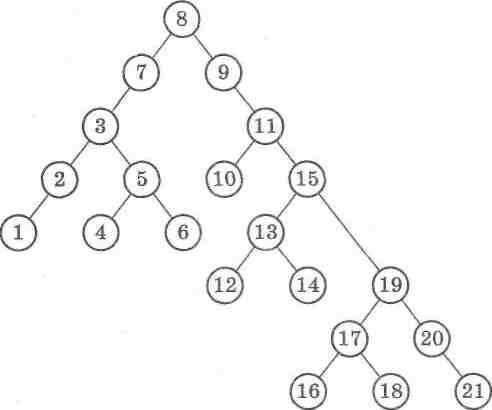
Мал. 38
Тепер розглянемо приклад послідовності елементів, серед яких е повтори значень. Наприклад:
21,8,9,13,15,19,10,21, 7,13,2,1,5,16,4,15,14,10,12,8,16,18.
При побудові дерева пошуку біля кожного елемента будемо визначати кількість його повторень у заданій послідовності (мал. 39).
Підіб'ємо деякі підсумки розглянутого пошукового алгоритму.
По-перше, основна ідея даного алгоритму базується на вико-ристанні структури даних «дерево».
По-друге, саме використання цієї структури дає змогу до-сить компактно зберігати в пам'яті вхідну інформацію, що по-дібна до алгоритмів «стиснення», оскільки в такому дереві від-сутні повтори одних і тих самих елементів.
По-третє, pyx побудованим деревом під час пошуку необхід-ного елемента значно швидший, аніж лінійно по масиву.
122
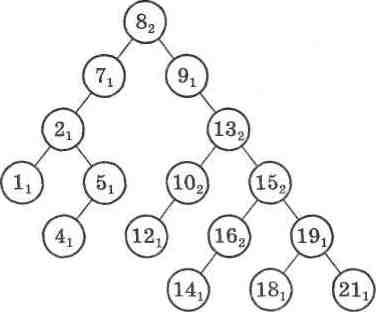
Мал. 39
Однак слід зазначити, що остання перевага мае сенс лише у випадку, коли треба здійснювати багатократний пошук зада-ного елемента у послідовності. Тоді варто лише один раз побу-дувати дерево, а потім протягом виконання алгоритму здійс-нювати пошук необхідну кількість разів. Якщо ж пошук відбу-вається одноразово, то його можна організувати лінійно під час читання самої послідовності значень і одночасно рахувати кількість входжень шуканого елемента у цю послідовність.
Оцінка ефективності використання дерева пошуку для ви-значення наявності шуканого елемента х у заданій послідов-ності а[і], і = 1, 2, ..., п складає 0(log2n). Таку формулу можна пояснити тим, що на кожному кроці шлях пошуку змен-шується вдвічі і вибирається один із двох можливих варіантів руху по дереву.
• Запитання для самоконтролю
-
Опишіть структуру даних, яка визначає дерево.
-
Яке дерево називаеться деревом пошуку?
-
Запишіть алгоритм обходу дерева.
-
Запишіть алгоритм пошуку елемента в дереві за унікальним ключем.
-
У чому полягає сутність задачі, що носить назву «частотний словник»?
-
Опишіть структуру дерева, що визначаеться постановкою зада-чі частотного словника.
-
Запишіть алгоритм І текст Pascal-процедури включения нового елемента х у дерево пошуку для реалізації задачі «частотний словник».
-
Як можна використати описану в попередньому пункті процедуру для побудови частотного словника?
-
Запишіть алгоритм І текст Pascal-процедури виведення на екран монітора вмісту побудованого дерева пошуку для реалізації задач! «частотний словник».
10. Наведіть свій приклад послідовності елементів і зобразіть гра-фічно дерево пошуку, що відповідає цій послідовності.
123
I
-
У чому полягають переваги використання структури даних «дерево» для пошуку необхідної інформаці? в заданій послідов-ності елементів?
-
Якою є оцінка ефективності роботи лінійного пошукового алгоритму? Обґрунтуйте свою відповідь.
Завдання
-
Розробити й реалізувати алгоритм побудови частотного словника.
-
Виконати завдання 1 для послідовності з 10 різних еле-ментів, вивівши на екран монітора вміст побудованого дерева.
-
Виконати завдання 1 для послідовності з 10 елементів, серед яких є значения, що повторюються. Вивести на екран монитора вміст побудованого дерева.
-
Виконати завдання 1 для послідовності з 1000 елементів, серед яких є значения, що повторюються. Вивести на екран мо-нітора вміст побудованого дерева.
-
Проаналізувати ефективність виконання алгоритму побудови частотного словника для багатократного пошуку різних елементів, використовуючи завдання 4. Для визначення ефек-тивності роботи алгоритму підраховувати кількість вершин, які необхідно пройти для визначення результату.
-
Виконати завдання 4-5, використовуючи алгоритм ліній-ного пошуку.
-
Порівняти ефективність алгоритмов у завданнях 4-5 та в завданні 6.
Пошук у рядку
Прямий пошук підрядка у рядку
Нехай треба визначити можливість входження тексту х, що складається з т символів, у текст s, що складається з п сим-волів (т < п). Слід зазначити, що саме така задача є реалізова-ною в будь-якому текстовому редакторі.
Як розв'язувати сформульовану задачу? Першим спадає на думку такий простий алгоритм: будемо послідовно суміщати символи підрядка х із символами рядка s, починаючи з першо-го (мал. 40).
|
81 |
*г |
S3 |
... |
»* |
... |
sm |
Sm+1 |
... |
Vi |
S л |
|
|
х1 |
Х2 |
хг |
... |
хн |
... |
Хп, |
|
|
|
|
|
Мал. 40
124
При першому ж незбіганні деякого символу підрядка х, тоб-то при виконанні умови хк * sk для k < т (на мал. 40 зображено сірим кольором), зміщуємо накладаиня підрядкя х на рядок s далі вправо на один символ: xL порівнюватимемо з s2, х2 з s3 i т. д. (мал. 41).
|
«1 |
«2 |
«8 |
... |
*ы |
SmH |
... |
8п-1 |
Sn |
|
|
|
Х1 |
Х2 |
... |
** |
Хт |
|
|
|
|
Мал. 41
Якщо ж i в цьому разі збігання з відповідним символом рядка s не відбудеться для деякого хк, де k < т, то зміщення підряд-ка х по рядку s продовжимо далі.
Зрозуміло, що цей процес припиниться в одному 3 двох ви-падків:
-
або на якомусь кроці символи всього підрядка х збігати-муться з фрагментом рядка s, i це означатиме, що ми знайшли входження підрядка х у рядок в;
-
або нас весь час будуть супроводжувати незбігання сим-волів підрядка х з символами рядка s, i це означатиме, що під-рядок х жодного разу не входить до рядка s.
Наведений лінійний алгоритм пошуку підрядка у рядку вва-жається найпростішим і є достатньо прозорим.
Запишемо його основну частину у вигляді тексту на мові Pascal:
n := length(s); m := length(x); i:=0;
flag := false; repeat inc(i);
j:=1;
while (x[j] = s[i + j - 1]) and (j <= m) do inc (j);
if j > m then flag := true; until flag or (i > n - m + 1); if flag
then writeln ('Позиція входження ', x,' у', s,':', i)
else writeln ('Текст ', x,' не входить у текст', s,' жодного разу');
Внесемо деякі роз'яснення в текст програми.
Чому в наведеному прикладі використані цикли з післяумо-вою і передумовою, а не цикли з лічильником? Справа в тому, що цикли з лічильником обов'язково виконуються вказану кількість разів. У нашому ж випадку в разі незбігання першо-го ж символу підрядка х з відповідним символом рядка s немає
125
сенсу продовжувати порівняння далі, а можна відразу зміщу-вати підрядок у рядку. Для цього ми використали внутрішній цикл while ... do. Для організації зовнішнього циклу викорис-тано цикл з післяумовою repeat ... until тому, що у випадку повного збігання підрядка у рядку нам потрібно припинити по-шук, але все ж таки хоча б одне накладання підрядка х на рядок s треба зробити.
Логічна змінна flag відіграє роль індикатора відшукання під-рядка х у рядку s: коли вона набуде значения true, пошук при-пиняється, оскільки це означатиме, що підрядок знайдено.
Зрозуміло, що оцінкою алгоритму лінійного пошуку підряд-ка у рядку є 0{п ■ т), оскільки кожного разу ми повинні всі т символів підрядка х порівнювати із л символами рядка s.
/ Запитання для самоконтролю
-
Сформулюйте умову класичної задачі пошуку підрядка у рядку. Де ця задача найчастіше використовується?
-
Зобразіть схематично лінійний алгоритм пошуку підрядка у рядку.
-
Сформулюйте умови завершения лінійного алгоритму.
-
Запишіть алгоритм і фрагмент тексту Pascal-програми лінійного пошуку підрядка у рядку.
-
Обґрунтуйте використання циклів з післяумовою та передумо-вою в реалізації алгоритму лінійного пошуку підрядка у рядку.
-
Поясніть необхідність використання логічної змінної у лінійному алгоритмі пошуку підрядка у рядку.
-
Якою є оцінка ефективності роботи алгоритму лінійного пошуку підрядка у рядку?
Завдання
-
Розробити й реалізувати лінійний алгоритм пошуку під-рядка х у рядку $.
-
Виконати завдання 1 для підрядка х завдовжки 3 символи у рядку s довжиною в 20 символів, протестувавши його для випадку, коли підрядок х входить у рядок s:
-
на початку рядка s;
-
посередині рядка s;
-
у кінці рядка s;
-
декілька разів у рядок s.
3. Виконати завдання 1 для підрядка х довжиною в 10 сим- волів у рядку s довжиною в 255 символів, протестувавши його для випадку, коли підрядок х входить у рядок s:
-
на початку рядка s;
-
посередині рядка s;
-
у кінці рядка s;
-
декілька разів у рядок s.