Материал: Інформатика_1 (методи побудови алгоритмівта та їх аналіз)
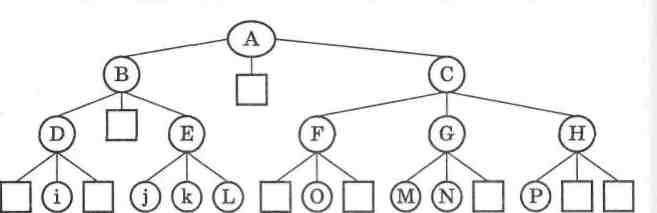
Мал. 27
Наприклад, довжина зовнішнього шляху на малюнку 27 дорівнює 24.
Особливе місце у структурі даних «дерево» займають упо-рядковані дерева другого степеня. їх ще називають двійкови-ми, або бінарними.
Визначимо упорядковане бінарне дерево як кінцеву мно-жину елементів, тобто вершин, яка або порожня, або скла-дається з кореня з двома окремими двійковими деревами - лі-вим і правим піддеревами.
Приклади бінарних дерев:
— генеалогічне дерево, де, як у кожної людини, в термінах поняття «дерево» «нащадками» є батько та мати;
- арифметичний вираз з бінарними операціями. Наприклад, для арифметичного виразу (а + Ь/с) ■ (d — е ■ f) деревовидна схе ма виглядатиме так (мал. 28):
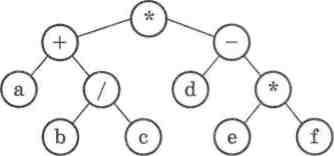
Мал. 28
Як програмно представити дерево? Кожну вершину можна розглядати як вхід у нове дерево. Це наводить на думку про ви-користання рекурсії в описі дерева. Посилання на порожні дерева, тобто термінальні вершини, будемо позначати значениям nil - порожне посилання.
86
У термінах посилань представимо попереднє дерево так (мал. 29):

 £~\
£~\
Г~і
г- I -у
*- I ta
nil nil
nil nil

I
I
t Tt t У ▼ t V
nil nil nil nil nil nil nil nil
Мал. 29
Розглянемо бінарне дерево як структуру даних. За анало-гією зі списком опишемо й так:
Type Ptr= "Node; Node = record
data: <тип > ; left, right: Ptr; end;
Отже, тепер можна дати ще одне означения структури даних «дерево».
I
Дерево з базовим типом Т — це порожне дерево або деяка вершина типу Т з кінцевою кількістю зв'язаних із нею ок-ремих дерев з базовим типом Т, що називаються піддере-вами.
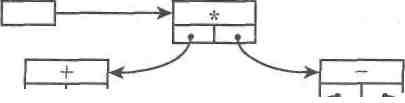
А як же в динамічній пам'яті будуть розміщені елементи такого бінарного дерева? З'ясуємо, яким чином структура даних «дерево» відображається на пам'ять комп'ютера. Оскільки пам'ять мае лінійну дискретну структуру, то й елементи роз-ташовуються там один за одним. Лише значення покажчиків указуватимуть на слідування одного елемента за іншим. Опробуемо схематично зобразити розташування в пам'яті комп'ютера структуру дерева, що відповідає арифметичному виразу (а + b/c) -(d-e-f)(мал. 30).
87
*ш
![]() ^S^T^FS.:
^S^T^FS.:
Мал. 30
Далі найкраще розглянути конкретну задачу, в якій вико-ристаємо дерево. Це буде задача формування бшарного дерева для цілих чисел, що читаються з файла. Будемо будувати дерево мінімальної глибини, розміщуючи вершини порівну зліва і справа від кожної вершини. Правило формування такого дерева визначимо так:
-
перше число розмістимо у першій вершині в якості коре-ня дерева;
-
побудуємо ліве піддерево з nl вершинами, де nl = п div 2;
3) побудуємо праве піддерево з пг вершинами, де пг = п — пі — 1. Побудоване за цим правилом дерево називається ідеально
збалансованим, бо кількість вершин у його правих і лівих під-деревах відрізняється не більш як на 1.
Почнемо зі створення дерева. Для цього можна запропонува-ти використання такої рекурсивно! функції:
function tree_balans (n: integer): Ptr; var q: Rr;
x, nl, nr: integer; begin
if n = 0 then q := nil else begin
nl := n div 2; nr := n - nl - 1 read (x); new (q); with q" do begin data := x;
left := tree_balans (nl); right := tree_balans (nr); end; end; tree_balans := q; end;
Використати функцію створення дерева можна такими дво-ма операціями:
read (n);
root := treebalans (n);
88
У результаті змінна root міститиме адресу його кореневого елемента.
Цікаво було б побачити, яким чином елементи збалансова-ного дерева наслідують один одного. Назвемо цю процедуру PrintTree:
procedure PrintTree(t: Ptr; h: integer); var i: integer; begin
If to nil then with t* do begin
PrintTree (left, h + 1); for i := 1 to h do write) '); write(data: 6); writeln; PrintTree (rigth, h+ 1); end; end;
Звернення в основній програмі до цієї процедури для виве-дення на екран монітора побудованого дерева буде таким:
PrintTree(root, 0);
Якщо виконаємо наведену процедуру виведення вмісту побудованого збалансованого дерева, наприклад для послідовно-сті 2, 5, 1, 7, 6, 3, 10, 9, 4, то отримаємо вигляд дерева, зобра-женого на малюнку 31:
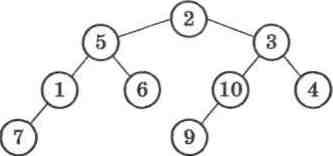
Мал. 31
Щоб визначити операції читання й запису елементів дерева, спочатку треба розібратися з операцією пошуку заданого елемента в дереві. Адже перш ніж вставляти елемент у дерево або вилучати його, необхідно знайти елемент, перед яким або після якого треба виконати відповідну операцію.
Зрозуміло, що дерево формується завжди за певною озна-кою. На відміну від списку, у кожної вершини дерева є два нащадки. Тобто, будуючи дерево, ми спочатку обумовлюемо ознаку, за якою один елемент є лівим, а другий - правим на-щадком для даного.
89
У збалансованому дереві такою ознакою є порядковий номер числа в заданій послідовності: перші числа заимають ліві «позиції» у лівому піддереві, а наступні числа - праві.
Можна також умовою формування дерева визначити якісну характеристику чисел, тобто їх значения: лівим нащадком для кожного числа у вершині дерева буде менше за нього число, а правим - більше. Дерево, побудоване таким чином, називаєть-ся деревом пошуку. Процедура створення такого дерева вигля-дае так:
procedure tree_find (х: integer; var р: Ptr); begin if p = nil then begin new (p); with p" do begin data := x;
left := nil; right := nil; end; end else
if x< p".data
then tree_find (x, pMeft) else treejirtd (x, рл.right); end;
Нехай нам відоме значения елемента дерева х, яке необхідно знайти. Найпростіший алгоритм опису цієї процедури є ре-курсивним. Якщо елемент не знайдено, пройдемо крайньою лі-вою межею дерева, поки не вийдемо на термінальну вершину, в якої покажчик на ліве піддерево дорівнює nil. Потім поверне-мося у найближчу батьківську вершину і здійснимо перехід до правого піддерева. Наступні діі' виконуватимемо аналогічно. Завершениям обходу дерева буде знаходження шуканого елемента або повернення назад у корінь дерева, що означатиме від-сутність у дереві шуканого елемента.
Процедура обходу дерева й одночасного пошуку заданого елемента виглядає так:
procedure search (t: Ptr); begin
if (t <> nil) and (f.data <> x) then with Г do begin
search (t'.left); search (f.rigth); end; end;
Аналогічно можна знайти елемент, для якого лівий або пра-вий нащадок є шуканим елементом, використавши для цього таку умову:
((tMeft <> nil) and (tMeft'.data о х)) or ((t\rigth О nil) and (t\rigth\data о x)).
Тобто можна знайти предка або батьківську вершину для шуканого елемента. Подібні операції ми визначали на структур! даних «список».
Поговоримо про визначення на побудованому дереві опера-цій читання та запису.
Залисати новий елемент у побудоване дерево не так уже й просто. Якщо побудоване дерево є ідеально збалансованим, то запис нового елемента у будь-яке місце порушить цю умову. Тому для збереження структури дерева запис повинен супрово-джуватися його переформуванням. Якщо ж дерево є деревом пошуку, то запис логічно здійснювати лише після відповідних термінальних вершин.
Розглянемо запис нового елемента зі значениям х саме у дерево пошуку. Послідовність дій повинна бути такою:
- «спуститися» гілками дерева до термінальної вершини за виконання умови х < p'.data або х > p".data;
— дописати елемент зі значениям х у визначене місце. Текст відповідної процедури повністю збігається із наведе-
ною вище процедурою створення дерева пошуку tree_find.
Читання заданого елемента з дерева є значно складнішою операцією. Треба вилучити елемент із побудованої структури, не порушивши при цьому закону ЇЇ будови.
Розглянемо такі три випадки:
-
елемент, що вилучається, є термінальною вершиною;
-
елемент, що вилучається, мае одного нащадка;
-
елемент, що вилучається, мае двох нащадків. Найпростішим є випадок, коли шуканий елемент є термі-
нальною вершиною або вершиною з одним нащадком. Склад-ніше, коли треба вилучити елемент, що мае обох нащадків, оскільки в цьому разі його необхідно замінити на крайній справа елемент його лівого шддерева або ж на крайній зліва елемент його правого шддерева.
Розглянемо створення повної версії процедури вилучення елемента з дерева пошуку поетапно.
Якщо шуканий елемент, значения якого знаходилося за адресою р, є термінальною вершиною, то досить цю адресу за-мінити на nil. Тобто до заміни вміст полів за адресоюр є таким: p".data = х; pMeft = nil; pA.rigth = nil, a після заміни - p = nil.
Якщо шуканий елемент, значения якого знаходилося за адресою р, мае лише одного нащадка, то він мае бути замінений
91
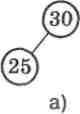
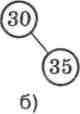
на нього. Це означає, що якщо відсутній правий нащадок (мал. 32, а), то шуканий елемент, що розташований за адре-сою р, мае набути значения елемента, що розташований зліва за адресою pMeft: р := pMeft. Якщо ж відсутній лівий нащадок (мал. 32, б), то шуканий елемент мае набути значения елемента, що розташований справа за адресою p".rigth: р := p'.rigth.
Коли ж шуканий елемент, що розташований за адресою р, мае двох нащадків, то його необхідно замінити крайнім справа нащадком у лівому піддереві. Чим це мотивовано? По-перше, це повинен бути елемент, що є термінальною вершиною, оскільки після його вилучення дерево пошуку не потребуе пе-ребудови і ми вже вміємо таку вершину вилучати. По-друге, цей елемент буде більший за лівого нащадка елемента, що ви-лучається, і менший за правого нащадка. Це слідує з умови по-будови дерева пошуку.
Найкраще розглянути конкретний приклад дерева і пере-свідчитися в логіці попередніх тлумачень (мал. 33).
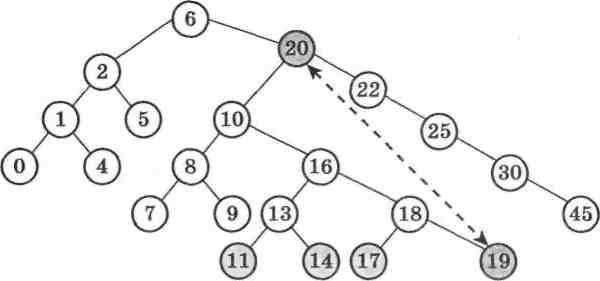
Мал. 33
Насамперед звернемо увагу на те, що для будь-якого елемента дерева пошуку, що не є термінальною вершиною, справ-джуеться тлумачення: всі елементи лівого шддерева менші за нього, а правого - більші. Саме на цьому буде грунтуватися на-ступне роз'яснення.
92
Нехай треба вилучити елемент дерева пошуку зі значениям 20. 3 малюнка видно, що справді всі елементи лівого під-дерева менші за цей елемент, а правого - більші за нього. На місце числа 20 ми повинні поставити елемент, менший за нього, щоб не порушити структуру правого піддерева. Такі елементи є лише у лівому піддереві. Але одночасно цей елемент повинен бути більший за його лівого нащадка, тобто більший за 10. Ця умова повинна бути збережена після переміщення, щоб не порушити структуру лівого піддерева. Такий елемент є у правому піддереві для вершини 10, оскільки саме тут розміщені всі елементи, більші за значения його вершини.
На перший погляд претендентом на переміщення може бути будь-яка з термінальних вершин 11, 14, 17, 19: для всіх цих значень лівий нащадок за значениям менший, а правий - біль-ший. Однак насправді лише термінальна вершина 19 може бути переміщеною на місце вершини зі значениям 20. Саме ЇЇ значения на новому місці не порушить структури дерева пошуку. Адже якщо на місце вершини 20 помістити вершину зі значениям 11, то в її лівому піддереві знайдуться елементи, більші за її' значения, наприклад числа 13, 18, 17, 16, і таким чином структура дерева буде порушена.
Отже, з погляду на побудову алгоритму для пошуку вершини, яка є претендентом на переміщення, необхідно весь час правою гілкою спускатися правим піддеревом вершини 10 до термінальної вершини. На цьому шляху ми дійдемо саме до шуканої термінальної вершини 19.
Тепер можемо записати послідовність описаних дій у вигля-ді процедури з відповідними коментарями:
procedure del (var р: Ptr; х: integer); var q: prt;
procedure d (var r: Ptr); {Рекурсивна процедура пошуку}
begin {крайнього справа найбільшого елемента.}
if rA.right <> nil {Будемо рухатися в глибину цього піддерева)
then d (rA.right) {крайньою справа гїлкою.}
else
begin
{Для знайденоі термінальноТ вершини} q'.data := r".data; q := г; {перенесемо посилання.}
{Вилучимо вершину зі значениям 19,} Г := г".left {записавши на її місце лівого нащадка.}
end; end; begin if p = nil
then writeln ('Шуканого елемента в дереві немає')
{Якщо шуканий елемент менший за значения} else if x<p\data {даноі вершини, то рухаємося вліво;}
93
end;
then del (pMeft, x)
{якщо шуканий елемент більший за значения} else if х > p".data {даної вершини, то рухаємося вправо;} then del (рл.right, x)
else {якщо шуканий елемент знайдено в дереві}
begin {у вершині з адресою р, то збережемо}
q := р; {його адресу в змінній q;}
{якщо в дано! вершини немає правого} {піддерева, то ви лучимо її, записавши} if q". right = nil
{на це місце вершину лівого піддерева;} then р := qMeft
{якщо в даноі вершини немає лівого} {піддерева, то вилучимо м, записавши} else if qMeft = nil
{на це місце вершину правого піддерева;} then р := q".right
{якщо в дано? вершини є обидва}
{піддерева, то перейдемо до Щ
{лівого нащадка, викликавши}
{рекурсивну процедуру.}
else d (qMeft);
{Вивільнимо пам'ять} dispose (q); {у купі від змінноі q.)
end;
Структура даних «дерево» так само, як i «список*, є структурою послідовного доступу, ми можемо знайти будь-який ви-значений елемент дерева, тільки починаючи з кореня дерева і рухаючись далі його гілками.
/ Запитання для самоконтролю
-
Яка структура даних називається деревом?
-
Зобразіть схематично дерево як структуру даних.
-
Наведіть приклади представления інформації у вигляді дерева.
-
Яке дерево називається упорядкованим?
-
Яка вершина дерева називається нащадком для даноі вершини?
-
Яка вершина дерева називається предком для даної вершини?
-
Яка вершина дерева називається коренем?
-
Що називається глибиною дерева?
-
Яка вершина дерева називається термінальною, а яка - внут-рішньою?
-
Як визначається степінь вершини і степінь дерева?
-
Як визначається довжина шляху до задано! вершини?
-
Як визначається довжина внутрішнього шляху всього дерева?
-
Як визначається довжина зовнішнього шляху всього дерева?
-
Які дерева називаються двійковими? Наведіть приклади двійко-вих дерев.
94
-
Запишіть опис структури даних «двійкове дерево» мовою Pascal та зобразіть його схематично.
-
Зобразіть схематично відображення на пам'ять комп'ютера еле-ментів двійкового дерева.
-
Поясніть принцип побудови ідеально збапансованого дерева.
-
Запишітьрекурсивнуфункцію побудови ідеальнозбалансовано-го дерева.
-
Запишіть процедуру виведення на екран монітора вмісту побудованого дерева.
-
Зобразіть збалансоване дерево, побудоване зі значєнь наведено! послідовності цілих чисел.
-
Поясніть принцип побудови дерева пошуку.
-
Запишіть процедуру побудови дерева пошуку.
-
Поясніть послідовність виконання дій при обході або перегляді елементів дерева.
-
Поясніть алгоритм запису нового елемента в дерево пошуку.
-
Поясніть алгоритм читання елемента з дерева пошуку.
-
Наведіть приклад дерева пошуку І продемонструйте алгоритм читання з нього деякого елемента.
-
Запишіть процедуру читання (вилучення) заданого елемента з дерева пошуку і поясніть роботу кожного оператора.
-
Який принцип доступу здійснюється до елементів дерева? Обґрунтуйте свою відповідь.