Материал: z2evbAG14A
задач из очереди ожидания;
- элемент матрицы назначения, которая является результатом ра боты системы планирования задач.
Описанный метод на шаге II.1 предполагает осуществление поиска ближай ших задач, который обладает следующими особенностями:
1.Основной проблемой такого рода поиска является его высокая размер ность. Для каждого сочетания (узел, задача) необходимо вычислить рас стояние до всех задач из предыстории выполнения, где асимптотическая сложность единичного запроса равна ( ).
2.При вычислении расстояния необходимо учитывать различную значимость атрибутов задач с точки зрения ресурсопотребления.
3.Необходимо учитывать гетерогенность атрибутов, поскольку прикладные
задачи характеризуются как категориальными, так и численными мета данными.
Исходя из сформулированных требований в настоящей работе предлагает ся модификация алгоритма поиска на основе метода локализованного хэширо вания, которая позволяет выполнить часть поиска за константное время (1), а часть – за сублинейное ( ), << . Отличия от стандартного алгоритма выделены жирным шрифтом.
Модификация алгоритма поиска ближайших соседей на основе метода локализованного хэширования:
I. Выбор атрибутов для хэширования:
I.1. Разделить множество атрибутов на категориальные и численные. I.2. Для каждого из полученных множеств вычислить коэффи
циенты значимости используя обучающую выборку.
I.3. Выбрать наиболее значимых для ресурсопотребления ка тегориальных атрибутов и наиболее значимых численных атрибутов.
II. Построение хэш-таблицы на основе обучающей выборки: для каждого объ
11
екта данных:
II.1. Вычислить хэш значение отдельно для категориальных и отдельно для численных типов из множества выбранных на шаге 1.3 атрибутов.
II.2. Использовать полученный суммарный хэш в качестве индекса в хэш таблице для выбора корзины.
II.3. Сохранить идентификатор объекта по полученному адресу в хэш таб лицу.
III. Поиск ближайших соседей для нового объекта:
III.1. Вычислить хэш значение отдельно для категориальных и отдельно для численных типов из множества выбранных на шаге 1.3 атрибутов.
III.2. Использовать полученный суммарный хэш в качестве индекса в хэш таблице для выбора корзины.
III.3. Вычислить расстояние до каждого из объектов, идентификаторы ко торых хранятся в корзине, полученной на предыдущем шаге.
III.4. Отсортировать полученный вектор расстояний.
III.5. Выбрать объектов с наименьшим расстоянием.
Для применения описанного метода планирования задач в РСОД на прак тике, была сформулирована методика планирования задач на основе ме таданных и ресурсных метрик (Рисунок 1).
12
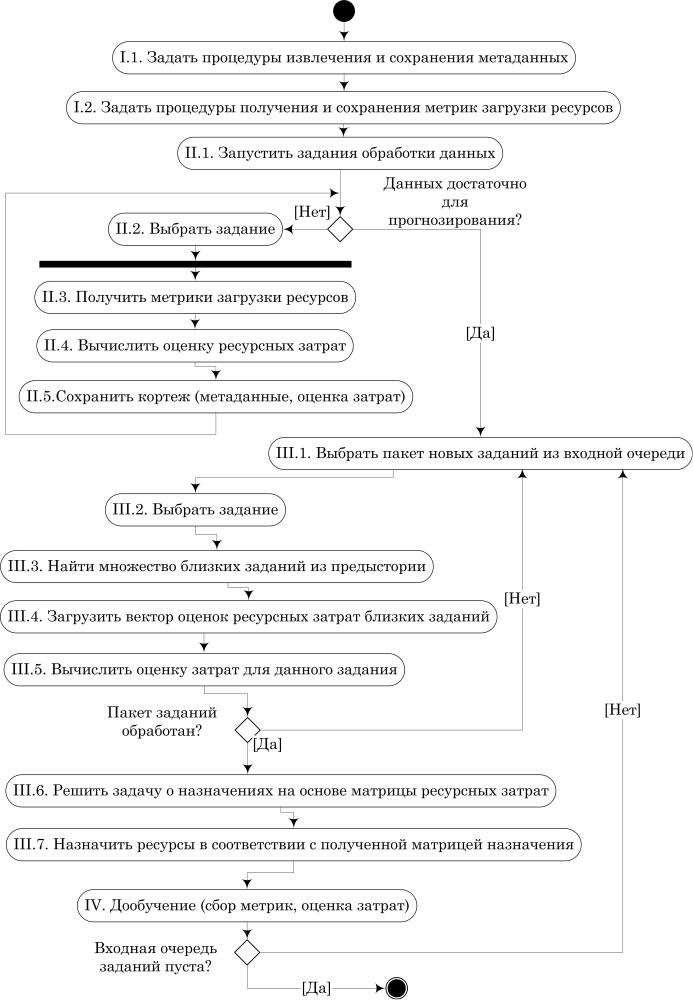
Рисунок 1. Методика планирования задач на основе метаданных и ресурсных метрик
В четвертой главе предложена программная архитектура РСОД, на ос нове которой реализована программная система планирования для задач деко дирования видео данных.
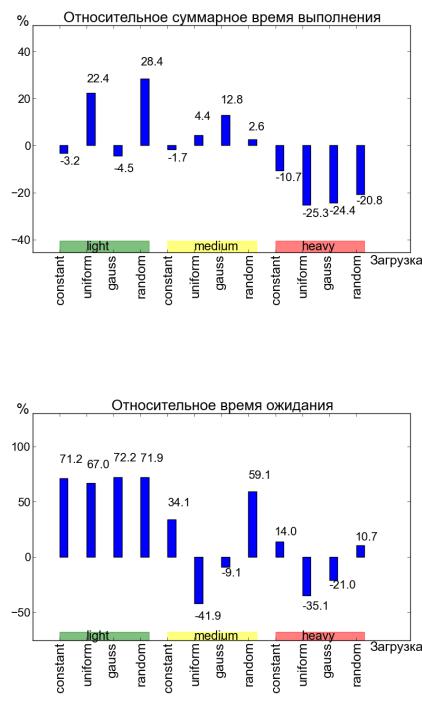
Проведён цикл экспериментов по планированию задач, результаты кото рых приведены на Рисунках 2 и 3.
Рисунок 2. Изменение временных затрат выполнения задач для метода Meta_Sched по срав нению с методом FIFO_LLF
Рисунок 3. Изменение среднего времени ожидания в очереди для метода Meta_Sched по сравнению с методом FIFO_LLF
Эксперименты проводились при различных условиях распределения тру
доёмкости задач (равномерное, гауссово, постоянное, случайное) и интенсив
14
ности вычислительной нагрузки (легкая - до 6 задач/мин, средняя - от 6 до 19 задач/мин и высокая - 86 задач/мин и выше) с использованием предлага емого метода планирования (Meta_Sched) и метода FIFO/Least Loaded First (FIFO_LLF). Оба метода принадлежат к классу методов, которые не требуют указания ресурсных требований.
Анализ результатов эксперимента (Рисунки 2 и 3) показывает следующее:
1.Суммарное время нахождения заявок в системе при использовании метода планирования на основе метаданных сокращается на 20% по сравнению
с методом FIFO_LLF при высокой интенсивности поступления задач в систему, но возрастает на 4.5% при средней интенсивности и на 10.7%
при слабой интенсивности.
2. Среднее время ожидания обработки заявок при использовании метода планирования на основе метаданных сокращается на 7.58% по сравнению с методом FIFO_LLF при высокой интенсивности поступления задач в систему, но возрастает на 10.55% при средней интенсивности и на 70.6%
при слабой интенсивности (что объясняется значительной долей наклад ных расходов в этом случае).
3.Увеличение интенсивности поступления заявок также увеличивает объём данных предыстории, что приводит к повышению качества прогнозирова ния.
Взаключении сформулированы основные научные и практические ре зультаты работы:
1.Предложена математическая модель планирования задач в РСОД, отли чающаяся от существующих совместным учётом метаданных и метрик загрузки ресурсов при отображении задач на вычислительные ресурсы.
2.Предложен метод планирования задач в РСОД, отличающийся от суще ствующих учетом метаданных из предыстории выполнения, которые удо влетворяют критерию близости.
3.Предложена модификация алгоритма поиска ближайших соседей на ос
15