Материал: Статистический анализ многомерных неоднородных данных в программной среде R
3.1 Модельные данные
Согласно [10], смоделируем выборку ![]() из модели FMSN с
из модели FMSN с ![]() компонентами,
имеющими скошенное многомерное нормальное распределение размерности
компонентами,
имеющими скошенное многомерное нормальное распределение размерности ![]() . Выберем
следующие параметры:
. Выберем
следующие параметры:
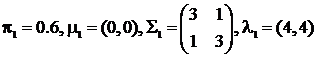 ;
;
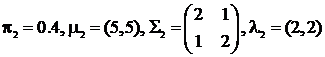 ,
,
где и - параметры для первой и второй компонент соответственно.
Оценим параметры и классификацию
полученной выборки в условиях двух режимов применения EM алгоритма:
в предположении модели FMNOR или модели FMSN. Для
сравнения результатов будет использовать статистики информационных критериев AIC, BIC, EDC и ICL [10].
Полученные результаты приведены в таблице 1. Согласно данным результатам, все
статистики принимают наименьшие значения для модели FMSN, которая
является образующей для выборки данных, что и следовало доказать.
Таблица 1. - Информационные
критерии для альтернативных моделей
Модель
AIC
BIC ICL
FMNOR
7773.877
7827.863
7821.447
7838.332
FMSN
7644.406
7718.022
7709.274
7723.102
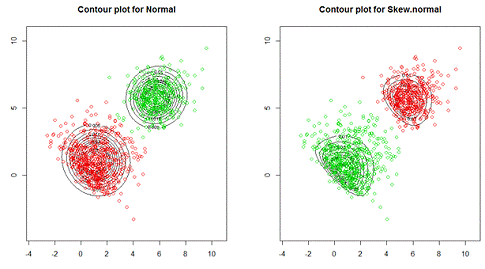
Также, на рисунке 1 визуализирована используемая
выборка данных с нанесением контурных линий, где слева нанесены контурные линии
для случая оценивания модели FMNOR,
а справа - FMSN. Согласно
данному рисунку, графическая визуализация в данном случае менее информативна.
Рисунок 1.
-
Контурные графики для моделей FMNOR,
FMSN
Большой интерес вызывает сравнение оцененных
классификаций (в предположении различных моделей) с истинной классификацией,
обозначающей принадлежность каждого наблюдения к заданной компоненте смеси, для
чего, как правило, используются оценки ошибок классификации. Однако последнее
оказалось невозможным, поскольку функция генерации выборки данных, реализованная
в библиотеке mixsmsn,
не предоставляет вектор классификации при генерации данных.
3.2 Реальные данные
Применим EM алгоритм к
квартальным данным по финансовому состоянию предприятий (16 кварталов, 300
предприятий, 4800 наблюдений) [7]. Оценим все имеющиеся в библиотеки модели: FMNOR, FMSN, FMSSL, FMSCN, и FMT и FMST. Для
оценивания будем использовать ненормированные коэффициенты. Также будем
классифицировать выборку на 4 класса, т.е. рассмотрим случай 4 компонент в
смеси распределений.
При вычислении некоторых
коэффициентов для 4 наблюдений были получены пропущенные значения. Исключив
данные наблюдения из анализа, получим выборку из 4796 наблюдений. Применим EM алгоритм
для оценивания каждой из перечисленных моделей. В ходе экспериментов при оценивании
моделей FMSSL, FMSCN не была
достигнута сходимость EM алгоритма, поэтому были
получены результаты только для остальных четырех моделей, которые представлены
в таблице 2.
Таблица 2. - Информационные критерии
для альтернативных моделей
Модель
AIC
BIC
EDC
ICL
FMNOR
158380.4
161482.2
164056.9
161956.3
FMSN
155541.7
159006.1
161881.8
159468.5
FMT
141542.8
144644.6
147219.2
145131.8
FMST
140066.1
143530.5
146406.2
144054.5
Согласно таблице 2, наилучшее соответствие
данным достигнуто при использовании модели FMST
(смесь скошенных многомерных t-распределений),
поскольку значениями статистик всех информационных критериев для данной модели
принимают наименьшее значение.
Также были предприняты попытки
оценить все вышеуказанные модели по соответствующим нормированным данным,
однако во всех случаях в вычислениях возникли ошибки, что не позволило оценить
ни одну из моделей. Последнее может свидетельствовать о неприменимости моделей
и алгоритмов из библиотеки mixsmsn к
нормированным данным. Это вызывает трудности при сравнении классификации,
полученной с помощью кластерного анализа в пространстве нормированных
коэффициентов, с классификациями, полученными с помощью указанных алгоритмов по
ненормированным данным [7], поэтому здесь данное сравнение не приводится. В
целом, оценивание такой выборки данных для данных алгоритмов оказалось довольно
трудной задачей (потребовалось довольно много времени для вычислений), поэтому
в дальнейших исследованиях предлагается разбить всю выборку данных по кварталам
и оценивать получаемые подвыборки отдельно.
Заключение
В данной работе получены следующие результаты:
) подготовлен обзор по методам и алгоритмам
параметрической классификации многомерных неоднородных наблюдений с помощью
алгоритмов типа EM,
предназначенных для анализа преимущественно асимметричных данных;
) подготовлен обзор основных программных
библиотек для среды статистического программирования R,
которые могут быть полезны для решения указанные методы и алгоритмы;
) проведены эксперименты на модельных и реальных
данных, иллюстрирующие особенности применения процедур, реализующих указанные
алгоритмы;
) выявлены недостатки указанного программного
обеспечения, как отсутствие вектора истинной классификации при моделировании
данных, а также их неприменимость к нормированным данным при анализе данных по
финансовому состоянию предприятий.
Приведенные обзор литературы свидетельствует о
широкой востребованности данной темы как в научных исследованиях, так и на
практике. Обилие программных реализаций соответствующих методов и алгоритмов, в
частности в R, дает большие возможности по анализу данных без необходимости
самостоятельно писать данные алгоритмы. Однако, ввиду специфичности конкретной
задачи, требуется доработка отдельных алгоритмов, что относительно быстро может
быть достигнуто при использования языка статистического программирования R.
Библиографический список
1. Айвазян,
С.А. Прикладная статистика. Классификация и снижение размерности / С.А. Айвазян
[и др.]. - М. : Финансы и статистика, 1989. - 607
с.
2. Mengersen,
K. Mixtures: Estimation and Applications / K. Mengersen, C.P. Robert, D.M. Titterington.
- Hoboken, N.J. : Wiley,
2011. - 311 p.
3. Fraley,
C. Model-based Clustering, Discriminant Analysis and Density Estimation / C.
Fraley, A.E. Raftery // J. of the American Statistical Association. - 2002.
-Vol. 97, № 458. - P. 611-631.
. Basso,
R.M. Robust Mixture Modeling Based on Scale Mixtures of Skew-normal
Distributions / R.M. Basso, V.H. Lachos, C.R.B. Cabral, P. Ghosh //
Computational Statistics & Data Analysis. - 2010. - Vol. 54. - P.
2926-2941.
5. Dempster,
A.P. Maximum likelihood from incomplete data via the EM algorithm / A.P.
Dempster, N.M. Laird, D.B. Rubin // Journal of the Royal Statistics Society.
Ser. B. - 1977. - Vol. 39, № 1. - P. 1-38.
6. The
R Project for Statistical Computing : [Electronic resource] / R Foundation. - Mode
of access : www.r-project.org. - Date of access : 26.10.2014.
7. Малюгин,
В.И. Система статистических кредитных рейтингов предприятий: методика
построения, верификации и применения / В.И. Малюгин [и др.] // Банковский
Вестник. Исследования банка. - №5. - 2013. - 73 с.
8. Bilmes,
J.A. A Gentle Tutorial of the EM Algorithm and its Application to Parameter
Estimation for Gaussian Mixture and Hidden Markov Models : Technical Report /
J.A. Bilmes ; Int. Computer Science Institute, Berkeley CA. - Berkeley,1998. -
13 p.
9. Comprehensive
R Archive Network : [Electronic resource] / R Foundation. - Mode of access :
http://cran.rstudio.com/index.html. - Date of access : 27.10.2014.