Материал: Системный анализ методов принятия решений по выдаче кредита
Результатом поведенческого скоринга обычно является предложение банка воспользоваться иными банковскими услугами: кредитная карта, кредит наличными по сниженной процентной ставке, автокредитование и др. Одобрение последующих кредитов в банке для заемщика - это также результат успешного преодоления поведенческого скоринга
На рис. 2.1 хорошо показана взаимосвязь элементов скоринга на различных
этапах жизненного цикла заемщика:
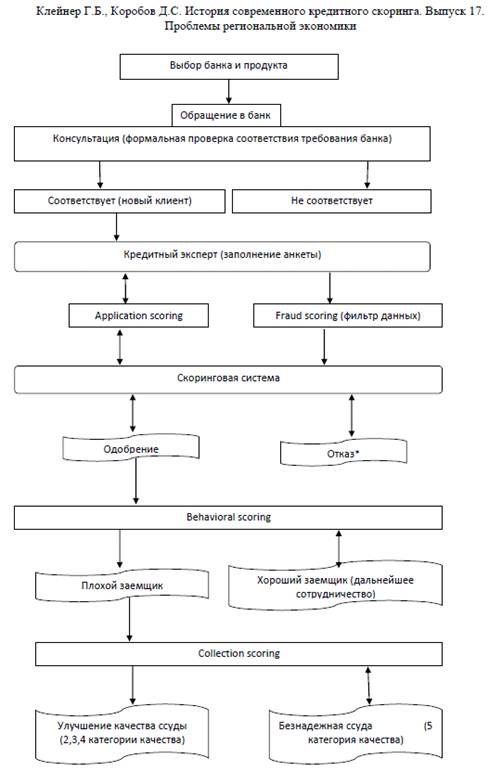
Рис. 2.1 Использование банком скоринговых моделей на различных этапах
оценки клиентов
Согласно аналитическому анализу портала kreditovich.ru на финальное
решение банка влияют следующие факторы
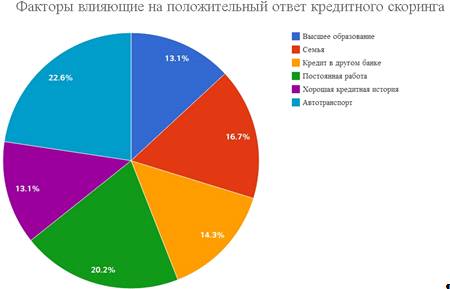
Схема 2.1. Факторы влияющие на положительный ответ кредитного скоринга
2.2 Проблема существующих методов
Существующие методы оценки кредитоспособности клиента не идеальны. В скоринговой модели оценки можно выделить следующие недостатки:
· Децентрализованность системы оценки;
· Сложность осуществления быстрых решений департамента риска кредитной организации - смена или корректировка методики оценки превращается в длительную процедуру для большого количества точек обслуживания;
· Невозможность построения сложной стратегии принятия решения;
· Скоринговые модели основаны на экспертных знаниях кредитных аналитиков банка, что ограничивает качество моделей и опосредованно сокращает клиентскую базу;
· Возможность обмануть методику оценки - любой человек, имеющий определенные навыки, может "взломать" методику оценки и в дальнейшем "подстроиться" под "хорошего" заемщика. Это касается не только рисков мошенничества, но и "помощи" заемщикам со стороны кредитных инспекторов (нельзя забывать, что эти по большей части низкооплачиваемые сотрудники стремятся к максимальному объему привлеченных кредитов, никак не отвечая за их возврат).
· Мониторинг - Скоринговые модели создаются на основе исторических данных, но со временем могут терять точность, из-за постоянно меняющихся внешних и внутренних условий (экономическая ситуация в мире, на уровне государства, отдельных отраслей, новые схемы мошенничества итд). Для того чтобы статистический скоринг стабильно выдавал достаточно точные и устойчивые прогнозы, необходим постоянный мониторинг и оценка качества работы моделей, а также их обновление при необходимости.
Систематизированное сравнение подходов к оценке клиента представлено в
Таблице.
Таблица 2.1. Сравнение экспертной и бальной оценки кредитоспособности
клиента
Критерии
Типовой подход к оценке заемщика
Система кредитного скоринга
Первичная обработка кредитной заявки
Основывается на экспертных знаниях кредитного специалиста
Основывается на объективной информации из различных
источников
Процесс оценки идентичных заявок
Рассмотрение каждой заявки зависит от конкретного
кредитного специалиста и субъективных факторов
Идентичные заявки проходят идентичную процедуру оценки
Легкость восприятия
"Уже используется", результаты ожидаемы
Необходимы культурные перемены, готовность сотрудников к
нововведениям
Процесс внедрения
Длительное обучение и тренировка каждого кредитного
специалиста. Наработка опыта и интуиции
Не требует длительного обучения сотрудников. При внедрении
необходим контроль со стороны кредитных специалистов высшего звена
Возможность ошибок, злоупотреблений и мошенничества
Ошибки возможны в силу человеческого фактора.
Злоупотребления и мошенничество возможны и распространены
Злоупотребления возможны только на уровне высшего звена
кредитных специалистов. Ошибки могут быть связаны с некачественными
скоринговыми моделями. Мошенничество возможно, однако его вероятность заметно
снижается
Гибкость
При внедрении нового кредитного продукта необходима
разработка новых инструкций и обучение персонала. Процесс длительный и мало
поддающийся контролю
При внедрении нового кредитного продукта необходимо
создание новых скоринговых моделей и стратегий (или внесение изменений в уже
имеющиеся). Процесс полностью контролируемый. Качество вновь созданных
моделей (стратегий) может быть проверено без запуска в работу. Дополнительное
обучение персонала не требуется
Поставленная задача должна решить следующие проблемы:
· Повысить надежность существующей кредитной политики банка и
снизить кредитный риск.
· Сократить время на принятия решения банком
· Автоматизировать процесс принятия решения по клиенту
· Сравнить методы интеллектуального анализа данных
Анализ будет состоять из двух частей. Первая часть заключается в анализе
базы данных клиентов банка, у которых имеется кредит. Скоринговая модель будет
относится к типу поведенческого скоринга. Ключевым показателем является
показатель списания клиента за первый год владения кредитным продуктом.
Показатель в базе данных "Ever W/O @12 MOB" является показателем булевого типа. Результатом
первого этапа будет набор параметром, полученный на обучающей выборке клиентов,
которым банк выдал кредит в 2012 году. Второй этап это применение алгоритма к
тестовой выборке за 2013 год. Третий этап заключается в применении полученных
знаний и использования их для предложенного метода автоматизации принятия
решения.
Можно выделить следующие основные этапы анализа данных: Проведена нормализация данных: приведение параметров к булевому типу,
числовому и текстовому, характеризующих данную область данных о клиенте. После
выбора параметров, данные представляют собой прямоугольную таблицу, где каждая
запись представляет клиента с набором характеристик, свойств и показателей.
· Из массива данных удалены данные, которые являются
неинформативными, либо дублируют ключевой показатель.
Кроме того, сокращение количества полей позволяет сократить время
обработки данных. Это позволяет избавиться от избыточности данных. База данных
очищена от ошибок, дефектов и полей без значений.
· Применение методов поиска ассоциативных правил: алгоритм apriori, DHP, предикативный анализ.
· Верификация и проверка получившихся результатов.
· Использование полученной информации и применение ее в работе
банка.
Модель алгоритма априори, его математическая составляющая описана в
источниках [1-2]. Краткое обоснование используемых терминов и понятий дано
ниже.
Правило X->Y имеет поддержку s (support), если s клиентов из D,
содержат пересечение множеств X и Y. Достоверность правила показывает какова
вероятность того, что из X следует Y. Правило X->Y справедливо с
достоверностью c (confidence), если c транзакций из D, содержащих X, также
содержат Y, conf(X-> Y) = supp(X->Y)/supp(X ).
Рассмотрим принятую формальную постановку задачи поиска ассоциативных
связей, введем базовые термины и опишем формализмы, используемые в существующей
литературе по этой проблематике. Пусть (1)
Порогом уверенности (2)
где Кроме того, стоит отметить свойство антимонотонности.
Поддержка любого набора элементов не может превышать минимальной поддержки
любого из его подмножеств. Данное свойство служит для снижения размерности пространства поиска. Не имей мы в наличии такого свойства,
нахождение многоэлементных наборов было бы практически невыполнимой задачей в
связи с экспоненциальным ростом вычислений.
В качестве исходных данных имеется массив (компакт Х8 - профайл в бюро кредитных историй
Х9 - диапазон дохода
Х10 - диапазон кредитной линии
Х11 - показатель, что клиент списался
Х12 - возраст
Х13 - опыт работы
Х14 - срок кредита
Х15 - ставка кредита
Х16 - долговое бремя
Х17 - показатель является ли клиент сотрудником
банка
Входные данные описывают "перформанс" - поведение
клиента в рамках выданного кредитного продукта. Значения в столбцах представляют
собой характеристические показатели клиента. Каждая строка представляет собой
всех клиентов, которым был выдан кредит за взятый промежуток времени.
orig_segment - Сегмент, Программа, по которой был привлечен клиент
Corporate
Корпоративный сегмент. Клиенты находятся на
зарплатном проекте банка
Salaried
Зарплатный сегмент. Клиенты подтверждают доход
Surrogates
Суррогатный сегмент. Клиент вменяется доход на
основе предоставленных документов
TopUp
Сегмент перекредитования. Клиенты, у которых
есть открытый кредит берут дополнительные средства
Xsell to CC6+
Сегмент Перекрестных продаж на кредитные карты.
_subsegment - Сегментация на уровень глубже.
Corporate
New to payroll
Клиенты, компания работодатель которых не находится на
зарплатом проекте в банке, но клиент находится на индивидуальном зарплатном
обслуживании
Payroll pre-qualified
Клиенты, компания работодатель которых находится на
зарплатом проекте в банке
Payroll walk-in
Клиенты, компания работодатель которых находится на
зарплатом проекте в банке, но клиент испольуют другой банк для зарплатного
обслуживания
Salaried
2-NDFL Non-Corp
Клиенты, подтверждающие доход справкой 2-ндфл
Xsell to inactive CC Salaried
Клиенты, принявшие условия программы перекрестных продаж на
кредитную карту
Surrogates
Auto Surrogate
Клиенты, предоставившие в качестве подтверждения дохода
документы о владении автомобилем
Foreign Travel
Клиенты, подтвердившие свой доход заграничным паспортом с
поездками за последние полгода
Xsell to Liabilities
Клиенты, принявшие условия программы перекрестных продаж на
балансовые счета
TopUp
1st Regular TopUp
Клиенты, взявшие дополнительные средства у бьнка
1st Top Up for Payroll
1st Top Up on Xsell
Клиенты, взявшие дополнительные средства у бьнка
TopUp to Former Borrowers
Клиенты, взявшие дополнительные средства у бьнка, но
закрывшие свой кредит
Xsell to CC6+
XSell CC6+ with Line Decrease
Клиенты, принявшие условия программы перекрестных продаж на
кредитную карту, с момента открытия которой прошло 6 месяцев
XSell to CC6+ on Demand
Клиенты, у которых открыта кредитная карта и пожелавшие
взять кредит
INCOME_PROOF - Способ подтверждения дохода клиентом.
Доход определяется на основании следующих документов /
следующими способами:
· Чистый месячный/годовой доход клиента,
указанный им в заявлении, сверяется со стандартной формой № 2-НДФЛ, выдаваемой
и подписываемой работодателем, а также скрепленной его печатью. В форме №
2-НДФЛ должен быть указан доход минимум за 3 последних месяца.
· Доход заявителей из компаний категории
"S", привлеченных через Отдел корпоративных продаж, проверяется по
разделу заявки, содержащему данные о ежемесячной зарплате, заверенные
уполномоченным представителем компании и печатью компании или на основании
списков работников от компании (категории "А", "S"), с
указанием стажа работы, типа трудового договора и размера месячного заработка,
также заверенные уполномоченным представителем компании и печатью компании.
· Доход клиента также может косвенно определяться
по наличию заграничной поездки в последние полгода или фактом владения
иностранной машиной, которая не старше 8ми лет.
2-NDFL
Справка 2-НДФЛ
Auto Surrogate
Документы о владении автомобилеем
Payroll Transactions
Зарплатные транзакции
Travel Surrogate
Заграничный паспорт со штампами вьезда и выезда из страны
W/O Documents
Без подтверждения дохода
_PROFILE - Имеет значение флага. Попадает ли клиент под образ мошенника.
В положительном случае ему назначается дополнительная проверка данных._CODE -
Код рекламной компании, по который был привлечен клиент в банк._LEVEL - Группа
риска клиента, которая присваивается на основе его поведенческого и оценочного
скоринга_OIGINATION - Канал привлечения клиента_CATEGORY - Категория компании
работодателя
JOB_DESC - профессия
THICK_THIN - Профайл в бюро кредитных историй
Income_Range - Диапазон дохода
Credit_Line_Range - Диапазон кредитной линии_FLAG - Флаг, что клиент
является сотрудником
score_range- Диапазон скора
EMP_TIME - Опыт работы (в месяцах)
AGE_NBR - Возраст
INTEREST_RATE - Ставка кредита
TENOR
- Срок кредита
Drop_flag_orig_a-
Флаг, что данный тип клиента больше не подходит под текущую политику банка
DBR_RANGE - Диапазон долгового бремени
Известные компании
Категория "A"
· Крупные стабильные Российские
юридические лица - годовой оборот более 500 млн. руб.; · Компании, входящие в
список FORBES-2000; · Компании - члены Американской
торгово-промышленной палаты и/или Ассоциации Европейского бизнеса; · Посольства иностранных
государств; · Компании, находящиеся на зарплатном
обслуживании в банке; · Первые75 банков согласно годовому рейтингу РБК
(Классификация по активам); · Первые 25 страховых компаний согласно годовому
рейтингу РБК (Классификация по поступлениям); · Дочерние (доля 50% + 1
акция) компании компаний А категорий; · Компании, находящиеся
на корпоративном обслуживании в банке; · Компании, находящиеся
на рассчетно-кассовом обслуживании при условии годового оборота более 100
млн. руб. · Компании, акции которых торгуются на биржах ММВБ/РТС
Категория "S"* (максимум 15000
компаний)
Отдельные компании для целевого поиска клиентов
· Средние/Мелкие
стабильные Российские юридические лица - годовой оборот от 250 до 500 млн.
руб.; · Государственные бюджетные учреждения; · Дочерние (доля 50% + 1
акция) компании компаний S категорий; · 30 крупнейших
стабильных компаний (показатель оборота не важен) - в каждом регионе
присутствия банка
Прочие
Категория "B"
Зарегистрированные компании
Остальные российские юридические лица,
регистрация которых в ЕГРЮЛ подтверждена.
Категория "О"
Незарегистрированные компании
Остальные российские юридические лица,
регистрация которых в ЕГРЮЛ не подтверждена.
Стаж работы
Суммарный стаж на двух последних местах работы
должен составлять не менее года и минимум 3 месяца на текущем месте работы. 3
месяца для клиентов, получающих зарплату на счет в банке, для существующих
клиентов по программам Перекрестных продажи и увеличение суммы кредита по
инициативе банка.
Рассмотрим набор клиентов, включающий заданные характеристики. Выразим
этот набор с помощью переменных. Обозначим множество характеристик за I - {A,
B, C, D..P}
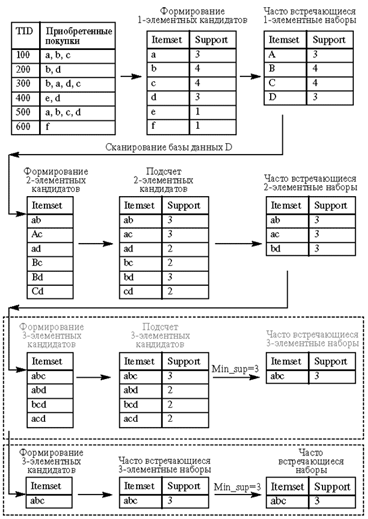
Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов.
На i-ом этапе определяются все часто
встречающиеся i-элементные наборы. Каждый этап состоит из
двух шагов:
1. формирование кандидатов
(candidate generation);
2. подсчет поддержки кандидатов (candidate counting).
Рассмотрим i-ый этап. На шаге формирования кандидатов алгоритм создает множество
кандидатов из i-элементных наборов, чья поддержка
пока не вычисляется. На шаге подсчета кандидатов алгоритм сканирует множество
клиентов, вычисляя поддержку наборов-кандидатов. После сканирования
отбрасываются кандидаты, поддержка которых меньше определенного пользователем
минимума, и сохраняются только часто встречающиеся i-элементные наборы. Во время первого этапа выбранное
множество наборов-кандидатов содержит все одно-элементные частые наборы.
Алгоритм вычисляет их поддержку во время шага подсчёта
поддержки кандидатов. Описанный алгоритм можно записать в виде следующего
псевдокода:
. L1 = {часто встречающиеся 1-элементные наборы}
. для (k=2; Lk-1 <> ; k++) {
. Ck = Apriorigen(Lk-1) // генерация кандидатов
. для всех клиентов t T {
. Ct = subset(Ck, t) // удаление избыточных правил
. для всех кандидатов c Ct
. c.count ++
. }
. Lk = { c . }
. Результат Обозначения, используемые в алгоритме:
Lk = {(F1,Supp1),(F2,Supp2),...,(Fq,Suppq)},
где Fj = {i1,i2,...,ik};
· Ck - множество кандидатов k-элементных наборов потенциально
частых. Каждый член множества имеет набор упорядоченных (ij < ip если j < p)
элементов F и значение поддержки набора Supp.
Опишем данный алгоритм по шагам. Шаг 1. Присвоить k = 1 и выполнить отбор всех
1-элементных наборов, у которых поддержка больше минимально заданной. Suppmin. Шаг 2. k = k + 1.
Шаг 3. Если не удается создавать k-элементные
наборы, то завершить алгоритм, иначе выполнить следующий шаг. Шаг 4. Создать
множество k-элементных наборов кандидатов из
частых наборов. Для этого необходимо объединить в k-элементные кандидаты (k-1)-элементные частые наборы. Каждый кандидат Шаг 5. Для каждого клиента T из множества D
выбрать кандидатов Ct из множества Ck, присутствующих в наборе характеристик клиента T. Для каждого набора из построенного
множества Ck удалить набор, если хотя бы одно из
его (k-1) подмножеств не является часто
встречающимся т.е. отсутствует во множестве Lk− 1. Это можно записать в виде
следующего псевдокода:
Для всех наборов Шаг 6. Для каждого кандидата из Ck увеличить значение поддержки на
единицу. Шаг 7. Выбрать только кандидатов Lk из множества Ck, у которых значение поддержки больше
заданной пользователем Suppmin. Вернуться к шагу 2. Результатом работы алгоритма является
объединение всех множеств Lk для всех k.
Таблица 4.1. Схематическое изображение работы алгоритма apriori
Схема 5.1
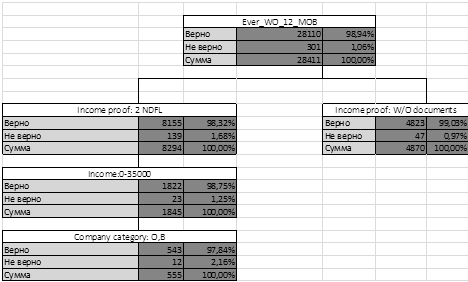
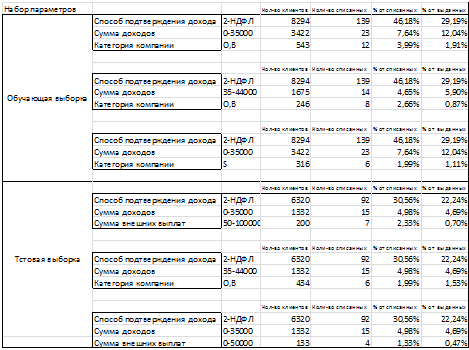
База данных состоит из 72848 записей. Ключевым заданным параметром стал
"EVER_WO_12MOB",
обозначающий списание клиента в течении 12 месяцев. Обучающая база данных
состояла из 28411 клиентов, 28110 которых имеют значение "0" в
ключевом поле, что составляет 98, 94% процента от всех клиентов в базе данных.
По алгоритму поиска ассоциативных правил было построено дерево возможных
решений, внутри которого в зависимости от глубины поиска с разными уровнями
поддержки были предложены наборы данных. Таким образом, по алгоритму поиска
ассоциативных правил был предложен следующий набор данных при уровне поддержки
99%(клиент полностью выплачивает кредит).
Первая ключевая характеристика при списывании клиента - это способ подтверждение
дохода. При оценке результатов работы алгоритма рассмотрено влияние
характеристики как со стороны уменьшение количества списанных клиентов, так и
стороны бизнеса: скольких денег не досчитается банк, если откажет в кредите
всем клиентам с данной характеристикой.
Клиенты, подтверждающие свой доход с помощью справки 2-ндфл составляют
22,4% от кредитного портфеля. Среди 6320 клиентов, находится 30,56 % от
списанных клиентов, что составляет 92 клиента.
Второй параметр - сумма доходов. При том же уровне поддержки в 99%,
"плохими клиентами" являются с низким уровенем дохода, а именно ниже
35000 рублей. Суммарно данная группа составляет 7,64 % клиентов среди
списавшихся и 12,04 % от портфеля, учитывая клиентов выплачивающих кредит.
Третьим по глубине фактором является категорий компании. Клиенты,
работающие в небольших компаниях или на ИП чаще списывались в просрочку. Около
4% от всех списавшихся клиентов. Однако среди всего портфеля эта цифра занимает
совсем маленькую долю- около 1,91%. Из этого следует, что дальнейшее погружение
в дерево, не будет давать нам необходимого уровня поддержки.
На последнем шаге уровень достоверности того, что клиент спишется если
приходит в банк со справкой 2-НДФЛ, его доход составляет менее 35 000 рублей, и
он работает в компании категории О или В, составляет 49 %.
Наиболее высокий уровень поддержки был выявлен для следующего набора
характеристик: если клиент подтверждает свой доход с помощью загранпаспорта,
либо владением автомобилем, то из этого следует, что в случае когда клиенту
будет присвоен уровень риска - высокий, то он спишется с уровнем поддержки 80%.
Однако, во всей используемой базе данных количество таких клиентов ровно 5, что
составляет 0,02 %.
Сформулируем окончательный набор данных, который говорит нам по результатам
выборки о ключевых параметрах, на которые стоит обратить внимание банку при
принятии решения:
Таблица 5.2 Предложенные алгоритмом наборы характеристик
{Способ подтверждения дохода, Уровень дохода, Возраст}
{2-НДФЛ, <35000, O,B}
Небольшое присутствие данной группы в кредитном портфеле, говорит о
грамотно проводимой политики банка по привлечению клиентов, верной
диверсификации рисков. .
Полностью отказаться банку от проблемных групп нельзя ввиду того, что
прибыль, которую приносят клиенты с теми же характеристиками, превышает расходы
от списаний проблемных клиентов.
Согласно исследованию, наиболее благоприятной группой являются клиенты,
подтвердившие свой доход, зарплатой которой перечисляется на счет в банк, выдавший
кредит. Для данной группы клиентов, которая является наименее рисковой с точки
зрения банка, создана процедура автоматизации принятия решения.
С полностью построенным деревом решений можно ознакомиться в приложении.
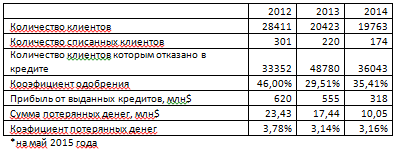
Сравним получившиеся результаты с показателями банка, которые
зафиксированы на сегодняшний день.
Таблица 6.1. Основные показатели работы банка
В результате апробации алгоритм на тестовой выборке дали схожие
результаты.
Таблица 6.2. Основные показатели работы банка после применения алгоритма
Результаты, полученные на модельной выборке данных, подтвердили
значимость выявленных ключевых показателей на тестовом множестве данных.
Для поставленной задачи повешения надежности существующих методов оценки
клиентов, необходимо проводить осторожную политику выдачи кредитов данному
сегменту клиентов, наложить дополнительные ограничения на текущие параметры,
соответствующие одобрению выдачи займа.
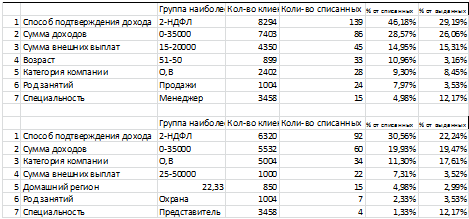
Помимо совокупного набора характеристик клиента, необходимо учитывать
совокупность ранжированного первого показателя по степени поддержки.
Таблица 6.3 Выборка первого параметра ранжирования
После проведения основного эксперимента, тестовая выборка данных была
использована как обучающая. Ключевые параметры, выделенные на данных клиентов
за 2013 год, имеют различия по сравнению с 2012.
Сложность представляет судить о клиенте по таким параметрам как профессия
и сфера деятельности. В российской федерации из-за ограниченного списка
профессий, которым полагается пенсионное обеспечение, компании-работодатели
указывают в трудовой книжке сотруднике общую специальность. Вследствие чего
поле профессия, значение которого банк получает из анкетных данных клиента,
содержит большое количество "Специалистов", "Менеджеров",
"Аналитиков". Это приводит к невозможности верного анализа данных.
Похожая ситуация с полем "NOB".
Данная проблема проявляется на группах характеристик, которые обладают
разнообразными вариантами параметров. К примеру, род занятий включает в себя 40
различных профессий, в то время как способ подтверждения дохода имеет лишь 6
вариаций. Фокус на параметре размывается, чем объясняется различие.
Проводя анализ применения полученных знаний в ходе работы алгоритма на
тестовой выборке, выявлено что прибыль, которую теряет банк, не выдав людям со
схожими характеристиками, но исправно выплачивающим кредитам меньше, чем
расходы и потери от списанных клиентов. Это подтверждает тот факт, что была
выявлена совокупность проблемных характеристик клиентов. Таким образом, на
тестовой выборке банк сократил расходы и получил большую прибыль по итогам 2014
года.
Результаты этого исследования внедрены в кредитную политику банка.
Для автоматизации процесса принятия решения были сделаны следующие шаги:
. Выбран сегмент кредитного портфеля для которого у банка имеются
все данные. Основной проблемой банка является узнать верный доход клиента,
чтобы правильно рассчитать кредитное предложение. Группа клиентов, доход
которых банк знает наверняка, является группа корпоративных клиентов,
находящихся на зарплатном обслуживании. На основе транзакций, производимых
компанией работодателем, у банка всегда имеется актуальная заработная плата
клиента. Помимо этого существует процедура автоматического списания долга с
основного счета клиента, в случае если клиент уйдет в просрочку.
. На основе кредитного скоринга проводимого банкам, результатах
исследования формируется база данных клиентов на ближайший месяц для которых
будет сформировано кредитное предложение в рамках кредитной политики. Таким
образом для каждого кредитного срока будет рассчитана процентная ставка,
ежемесячная выплата и максимальная сумма кредита
1. Проведен сравнительный анализ методов принятия решений
. На основе построенных алгоритмов анализа данных выявлены ключевые
характеристики клиентов
3. Разработан метод принятия решений, позволяющий сократить время
принятия решения в условиях определённости
кредитование заемщик риск выплата
По результатам работы была выполнена цель, а именно повышена надежность
метода оценки клиентов, снижен риск при выдаче кредита и определены ключевые
параметры влияющие на кредитоспособность и добросовестность выплат. Более того,
выполнена и подцель поставленная в ходе работе.
В ходе выполнения выпускной квалификационной работы успешно
решены поставленные задачи: проведен анализ факторов и существующих методов для
принятия решений в предметной области. Определены функциональные зависимости,
возможные избыточность и достаточные условия применимости используемых
параметров.
Построена модель, отличающаяся от существующих аналогов.
Сокращено время на принятие решения в условиях определенности.
1. Мэйз Э. Руководство по
кредитному скорингу, 2008 г. - 464с. ISBN: 978-985-6569-34-3, 1-888998-01-8
2. Пищулин А. Система
кредитного скоринга: необходимости и преимущества, Москва, Финансовый Директор,
2008 г.
3. Клейнер Г.Б., Коробов
Д.С. История современного кредитного скоринга. Выпуск 17// Проблемы
региональной экономики, 2012 №17 с. 6-12
4. Н.В. Бабина "Скоринг
как метод оценки кредитного риска потребительского кредитования"// Финансы
и кредит, 2007 №3, 30-36
5. Churchill G.
A., Nevin J. R., Watson R. R.// The role of credit scoring in the loan
decision. Credit
World. March/1977
6. Agrawal, R. Srikant.
"Fast Discovery of Association Rules", In Proc. of the 20th
International Conference on VLDB, Santiago, Chile, September 1994.
7. Булычев А.В. - Системный
подход к анализу скрытых закономерностей в больших массивах
слабоструктурированных данных, Москва 2010
8. www.cbr.ru - Центральный
банк Российской Федерации
9. www.basegroup.ru/ -
Технологии анализа данных
10. www.kreditovich.com/ -
Современные модели кредитного скоринга
11. www.angoss.com/ -
Программные решения для предикативного анализа
12. #"887440.files/image045.jpg">
3. Методика
решения задачи
.1 Общая
структура модели
3.2 Основные
этапы анализа данных
4.
Формулировка задачи
.1
Математическая формулировка
![]() -база данных клиентов банка,
-база данных клиентов банка, ![]()
![]()
![]() - произвольный клиент,
- произвольный клиент, ![]() -множество всех свойств и
характеристик клиентов, которые используются для обозначения объектов в базе
данных клиентов множества
-множество всех свойств и
характеристик клиентов, которые используются для обозначения объектов в базе
данных клиентов множества ![]() ,
, ![]() -подмножество свойств и признаков из множества X, и
-подмножество свойств и признаков из множества X, и ![]() - подмножество множества данных
клиентов из множества
- подмножество множества данных
клиентов из множества ![]() , каждая из которых содержит множество признаков
, каждая из которых содержит множество признаков![]() в качестве подмножества. Для
характеристики статистических свойств подмножества A в базе данных
в качестве подмножества. Для
характеристики статистических свойств подмножества A в базе данных ![]() обычно используют отношение мощности
обычно используют отношение мощности
![]() множества
множества ![]() к мощности
к мощности ![]() всего множества клиентов
всего множества клиентов ![]() . Эту величину принято называть
поддержкой (support) подмножества
. Эту величину принято называть
поддержкой (support) подмножества ![]() во множестве клиентов
во множестве клиентов ![]() :
:
![]() .
.
![]() =
=![]() и порогом поддержки
и порогом поддержки ![]() =
=![]() (
(![]() ,
,![]() - ассоциативное правило)
существуют, если справедливы следующие неравенства
- ассоциативное правило)
существуют, если справедливы следующие неравенства
![]() ,
, ![]() ,
,
![]() - количество клиентов во множестве
- количество клиентов во множестве ![]() , которые содержат
объединение множества символов подмножеств
, которые содержат
объединение множества символов подмножеств ![]() и
и ![]() . Модель ассоциативного
правила вида (2), принято называть моделью типа поддержка-уверенность.
Подмножество элементов
. Модель ассоциативного
правила вида (2), принято называть моделью типа поддержка-уверенность.
Подмножество элементов ![]() принято называть посылкой правила
принято называть посылкой правила ![]()
![]()
![]() , а подмножество
, а подмножество ![]() - его следствием. Иногда
эти подмножества называют паттернами (patterns). В задачах ассоциативной классификации
заключение правила может содержать только однолитерный паттерн, например, метку
одного из классов. Однолитерным может быть также и паттерн
- его следствием. Иногда
эти подмножества называют паттернами (patterns). В задачах ассоциативной классификации
заключение правила может содержать только однолитерный паттерн, например, метку
одного из классов. Однолитерным может быть также и паттерн ![]() . Те
же обозначения и термины используются и при поиске ассоциативно или причинно
связанных атрибутов. Задача поиска ассоциативных правил является здесь
центральной задачей.
. Те
же обозначения и термины используются и при поиске ассоциативно или причинно
связанных атрибутов. Задача поиска ассоциативных правил является здесь
центральной задачей.
4.2 Исходные
данные
![]() в метрическом
пространстве) значений случайных величин - параметров системы
в метрическом
пространстве) значений случайных величин - параметров системы ![]() , представленных в
приложении в таблице 1. В таблице 17 столбцов (полей, соответствующих указанным
показателям
, представленных в
приложении в таблице 1. В таблице 17 столбцов (полей, соответствующих указанным
показателям ![]() ,…,
,…,![]() ) и примерно 37000
записей. В терминах предметной области эти величины обозначают характеристики
клиента:
) и примерно 37000
записей. В терминах предметной области эти величины обозначают характеристики
клиента:
![]() - сегмент, программа по которой был привлечен клиент
- сегмент, программа по которой был привлечен клиент
![]() - более глубокая сегментация
- более глубокая сегментация
![]() - способ подтверждения дохода клиентом
- способ подтверждения дохода клиентом
![]() - код рекламной компании, по который был привлечен клиент в
банк
- код рекламной компании, по который был привлечен клиент в
банк
![]() - группа риска клиента, которая присваивается на основе его
поведенческого и оценочного скоринга
- группа риска клиента, которая присваивается на основе его
поведенческого и оценочного скоринга
![]() - канал привлечения клиента
- канал привлечения клиента
![]() - категория компании работодателя
- категория компании работодателя
4.2 Алгоритм
расчета
Алгоритм apriori
![]() Ck | c.count >= minsupport} // отбор кандидатов
Ck | c.count >= minsupport} // отбор кандидатов
![]()
![]() будет формироваться путём добавления
к (k-1)-элементному частому набору - p элемента из другого (k-1)-элементного частого набора - q. Причем добавляется последний
элемент набора q, который по
порядку выше, чем последний элемент набора p (p.itemk − 1 < q.itemk − 1). При этом все k-2 элемента обоих наборов одинаковы (p.item1 = q.item1,p.item2 =q.item2,...,p.itemk − 2 = q.itemk − 2).
будет формироваться путём добавления
к (k-1)-элементному частому набору - p элемента из другого (k-1)-элементного частого набора - q. Причем добавляется последний
элемент набора q, который по
порядку выше, чем последний элемент набора p (p.itemk − 1 < q.itemk − 1). При этом все k-2 элемента обоих наборов одинаковы (p.item1 = q.item1,p.item2 =q.item2,...,p.itemk − 2 = q.itemk − 2).
![]() выполнить для всех (k-1)-поднаборов s
из c выполнить если (
выполнить для всех (k-1)-поднаборов s
из c выполнить если (![]() ), то удалить его из Ck
), то удалить его из Ck
Программные
средства
Анализ данных
производился с помощью программных средств Angos "KnowledgeSeeker". Ангос использует алгоритмы поиска знаний в больших
массивах информации с помощью разных методов анализа данных, таких как
предикативный анализ, поиск ассоциативных правил по алгоритму априори и
кластеризация данных. Более подробно с описанием данного программного
обеспечения можно ознакомиться по ссылке [11].
5. Результаты
6. Анализ
результатов
.1 Интерпретация
полученных результатов

6.2 Основные
результаты
Заключение
Список
использованной литературы