Материал: Прогнозування валютних цін на фінансовому ринку
Зміщення центру досліджень нечітких систем у бік практичних застосувань привело до постановки цілого ряду проблем, зокрема:
нова архітектура комп'ютерів для нечітких обчислень;
елементна база нечітких комп'ютерів і контролерів;
інструментальні засоби розробки;
інженерні методи розрахунку і
розробки нечітких систем управління, і т.п.
.3 Системи нечіткого виводу
Поняття нечіткого виводу займає центральне місце в нечіткій логіці і в теорії нечіткого управління. Говорячи про нечітку логіку в системах управління, можна дати наступне визначення системи нечіткого виводу.
Система нечіткого виводу - це процес отримання нечітких висновків про необхідне управління об'єктом на основі нечітких умов або передумов, що є інформацією про поточний стан об'єкту [6].
Цей процес сполучає в собі усі
основні концепції теорії нечітких множин: функції приналежності, лінгвістичні
змінні, методи нечіткої імплікації і тому подібне. Розробка і застосування
систем нечіткого виводу включає ряд етапів, реалізація яких виконується на
основі розглянутих раніше положень нечіткої логіки (рис. 1.1).
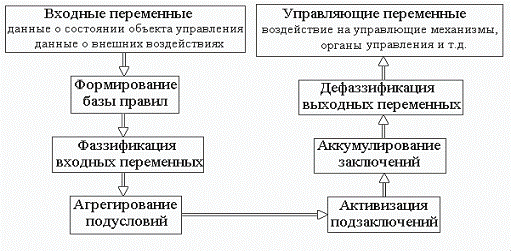
Рисунок 1.1 - Діаграма процесу
нечіткого виводу
База правил систем нечіткого виводу призначена для формального представлення емпіричних знань експертів в тій або іншій предметній області у формі нечітких продукційних правил. Таким чином, база нечітких продукційних правил системи нечіткого виводу - це система нечітких продукційних правил, що відбиває знання експертів про методи управління об'єктом в різних ситуаціях, характері його функціонування в різних умовах і тому подібне, тобто що містить формалізовані людські знання.
Нечітке продукційне правило - цей
вираз виду:
(i) : Q;P;A═>B;S, F, N,
де (i) - ім'я нечіткої продукції, - сфера застосування нечіткої продукції, P - умова застосовності ядра нечіткої продукції, ═>B - ядро нечіткої продукції, в якому A - умова ядра (чи антецедент), - укладення ядра (чи консеквент) ═> - знак логічної секвенції або дотримання, - метод або спосіб визначення кількісного значення міри істинності укладення ядра, - коефіцієнт визначеності або упевненості нечіткої продукції, - постумова продукції.
Сфера застосування нечіткої продукції Q описує явно або неявно предметну область знання, яку представляє окрема продукція.
Умова застосовності ядра продукції P є логічним виразом, як правило предикат. Якщо воно є присутнім в продукції, то активізація ядра продукції стає можливою тільки у разі істинності цієї умови. У багатьох випадках цей елемент продукції може бути опущений або введений в ядро продукції [7].
Ядро A═>B є центральним компонентом нечіткої продукції. Воно може бути представлене в одній з поширеніших форм : «ЯКЩО A ТО B », «IF A THEN B »; де A і B - деякі вирази нечіткої логіки, які найчастіше представляються у формі нечітких висловлювань. В якості виразів і можуть використовуватися складені логічні нечіткі висловлювання, тобто елементарні нечіткі висловлювання, сполучені нечіткими логічними зв'язками, такими як нечітке заперечення, нечітка кон'юнкція, нечітка диз'юнкція.- метод або спосіб визначення кількісного значення міри істинності укладення B на основі відомого значення міри істинності умови A. Цей спосіб визначає схему або алгоритм нечіткого виводу в продукційних нечітких системах і називається методом композиції або методом активації.
Коефіцієнт упевненості F виражає кількісну оцінку міри істинності або відносну вагу нечіткої продукції. Коефіцієнт упевненості набуває свого значення з інтервалу [0;1] і часто називається ваговим коефіцієнтом нечіткого правила продукції.
Постумова нечіткої продукції N описує дії і процедури, які необхідно виконати у разі реалізації ядра продукції, тобто отримання інформації про істинність B. Характер цих дій може бути найрізноманітнішим і відбивати обчислювальний або інший аспект продукційної системи.
Погоджена множина нечітких продукційних правил утворює нечітку продукційну систему. Таким чином, нечітка продукційна система - це список нечітких продукційних правил «IF A THEN B », що відноситься до певної предметної області.
Простий варіант нечіткого продукційного правила:
ПРАВИЛО <#> : ЯКЩО в 1 « Є Ь 1 » ТО « в 2 Є Ь 2 »<#> : IF « в 1 IS Ь 1 » THEN « в 2 IS Ь 2 ».
Антецедент і консеквент ядра нечіткої продукції може бути складним, таким, що складається із зв'язок «И», «АБО», «НЕ», наприклад:
ПРАВИЛО <#>: ЯКЩО « в 1 Є Ь » І « в 2 Є НЕ Ь » ТО « в 1 Є НЕ в 2 »<#>: IF « в 1 IS Ь » AND « в 2 IS NOT Ь » THEN « в 1 IS NOT в 2».
Найчастіше база нечітких продукційних правил представляється у формі погодженого відносно використовуваних лінгвістичних змінних структурованого тексту :
ПРАВИЛО_1: ЯКЩО «Умова_1» ТО «Укладення_1» (F 1)
ПРАВИЛО_n: ЯКЩО «Умова_n» ТО «Укладення_n» (F n)
де F i ![]() [0;1] є
коефіцієнтом визначеності або ваговим коефіцієнтом відповідного правила.
Узгодженість списку означає, що в якості умов і висновків правил можуть використовуватися
тільки прості і складені нечіткі висловлювання, сполучені бінарними операціями
«И», «АБО», при цьому в кожному з нечітких висловлювань мають бути визначені
функції приналежності значень терм множини для кожної лінгвістичної змінної. Як
правило, функції приналежності окремих термів представляють трикутними або
трапецеїдальними функціями [8].
[0;1] є
коефіцієнтом визначеності або ваговим коефіцієнтом відповідного правила.
Узгодженість списку означає, що в якості умов і висновків правил можуть використовуватися
тільки прості і складені нечіткі висловлювання, сполучені бінарними операціями
«И», «АБО», при цьому в кожному з нечітких висловлювань мають бути визначені
функції приналежності значень терм множини для кожної лінгвістичної змінної. Як
правило, функції приналежності окремих термів представляють трикутними або
трапецеїдальними функціями [8].
Фаззифікація (введення нечіткості) - це установка відповідності між чисельним значенням вхідної змінної системи нечіткого виводу і значенням функції приналежності терма лінгвістичної змінної, що відповідає їй. На етапі фаззифікації значенням усіх вхідним змінним системи нечіткого виводу, отриманим зовнішнім по відношенню до системи нечіткого виводу способом, наприклад, за допомогою датчиків, ставляться у відповідність конкретні значення функцій приналежності відповідних лінгвістичних термів, які використовуються в умовах (антецедентах) ядер нечітких продукційних правил, що становлять базу нечітких продукційних правил системи нечіткого виводу. Фаззифікація вважається виконаною, якщо знайдені міри істинності м A (x) усіх елементарних логічних висловлювань виду « в Є Ь », що входять в антецеденти нечітких продукційних правил, де Ь - деякий терм з відомою функцією приналежності м A (x), a - чітке чисельне значення, що належить універсуму лінгвістичної змінної в.
Агрегація - це процедура визначення міри істинності умов по кожному з правил системи нечіткого виводу. При цьому використовується отримане на етапі фаззифікації значення функцій приладдя термів лінгвістичних змінних, що становлять вищезгадані умови (антецеденти) ядер нечітких продукційних правил.
Якщо умова нечіткого продукційного правила є простим нечітким висловлюванням, то міра його істинності відповідає значенню функції приналежності відповідного терма лінгвістичної змінної.
Якщо умова представляє складене висловлювання, то міра істинності складного висловлювання визначається на основі відомих значень істинності складових його елементарних висловлювань за допомогою введених раніше нечітких логічних операцій в одному з обумовлених заздалегідь базисів.
Активізація в системах нечіткого виводу - це процедура або процес знаходження міри істинності кожного з елементарних логічних висловлювань (підвисновків), що становлять консеквенти ядер усіх нечітких продукційних правил. Оскільки висновки робляться відносно вихідних лінгвістичних змінних, то мірам істинності елементарних підвисновків при активізації ставляться у відповідність елементарні функції приналежності.
Якщо укладення (консеквент) нечіткого продукційного правила є простим нечітким висловлюванням, то міра його істинності дорівнює твору алгебри вагового коефіцієнта і міри істинності антецедента цього нечіткого продукційного правила.
Якщо укладення представляє складене висловлювання, то міра істинності кожного з елементарних висловлювань дорівнює твору алгебри вагового коефіцієнта і міри істинності антецедента цього нечіткого продукційного правила.
Якщо вагові коефіцієнти продукційних правил не вказані явно на етапі формування бази правил, то їх значення за умовчанням дорівнюють одиниці.
Функції приналежності м (y) кожного з елементарних підвисновків консеквентов усіх продукційних правил знаходяться за допомогою одного з методів нечіткої композиції [5]:
min -активизация - м (y)=min{c; м (x)};
prod -активизация - м (y)=c м (x);;
average -активизация - м (y)=0,5(c + м (x));
де м (x) і c - відповідно до функції приналежності термів лінгвістичних змінних і міри істинності нечітких висловлювань, що утворюють відповідні наслідки (консеквенти) ядер нечітких продукційних правил.
Акумуляція в системах
нечіткого виводу - це процес знаходження функції приналежності для кожного з
вихідних лінгвістичних змінних. Мета акумуляції полягає в об'єднанні усіх мір
істинності підвисновків для отримання функції приналежності кожної з вихідних
змінних. Результат акумуляції для кожної вихідної лінгвістичної змінної
визначається як об'єднання нечіткої безлічі усіх підвисновків нечіткої бази
правил відносно відповідної лінгвістичної змінної. Об'єднання функцій
приналежності усіх підвисновків проводиться як правило класично x ![]() X м A B x =
max{м A x; м B x} (max - об’єднання)також можуть використовуватися операції
об'єднання x
алгебри x
X м A B x =
max{м A x; м B x} (max - об’єднання)також можуть використовуватися операції
об'єднання x
алгебри x ![]() X м A+B x =
м A x + м B x - м A x
X м A+B x =
м A x + м B x - м A x ![]() м B x,
граничного об'єднання x
м B x,
граничного об'єднання x ![]() X м A B x =
min{м A x
X м A B x =
min{м A x ![]() м B x;1},
драстичного об'єднання x
м B x;1},
драстичного об'єднання x ![]() X м A B x =
м B x, якщо м A x =0 м A x, якщо м B x =0 1, в інших випадках, а також л - суми
x
X м A B x =
м B x, якщо м A x =0 м A x, якщо м B x =0 1, в інших випадках, а також л - суми
x ![]() X м (A+B) x
= л м A x +(1 -л) м B xл
X м (A+B) x
= л м A x +(1 -л) м B xл![]() [0;1].
[0;1].
Дефаззифікація в системах нечіткого виводу - це процес переходу від функції приналежності вихідної лінгвістичної змінної до її чіткого (числовому) значення. Мета дефаззифікації полягає в тому, щоб, використовуючи результати акумуляції усіх вихідних лінгвістичних змінних, отримати кількісні значення для кожної вихідної змінної, яке використовується зовнішніми по відношенню до системи нечіткого виводу пристроями (виконавчими механізмами інтелектуальної САУ) [7].
Перехід від отриманої в результаті акумуляції функції приналежності м(x) вихідної лінгвістичної змінної до чисельного значення y вихідний змінної робиться одним з наступних методів :
метод центру тяжіння (Centre of Gravity) полягає в розрахунку центроїда площі y= ∫ x max x min x м (x) dx ∫ x max x min x м (x) dx, де [ x max; x min ] - носій нечіткої безлічі вихідної лінгвістичної змінної;
метод центру площі (Centre of Area) полягає в розрахунку абсциси y, що ділить площу, обмежену кривій функції приналежності м (x), так званої бісектриси площі ∫ x min y x м (x) dx= ∫ y x max x м (x) dx;
метод лівого модального значення y= x min;
метод правого модального значення y= x max.
Розглянуті етапи нечіткого виводу можуть бути реалізовані неоднозначним чином: агрегація може проводитися не лише у базисі нечіткої логіки Заде, активізація може проводитися різними методами нечіткої композиції, на етапі акумуляції об'єднання можна провести відмінним від max -об’єднання способом, дефаззифікація також може проводитися різними методами. Таким чином, вибір конкретних чинів реалізації окремих етапів нечіткого виводу визначає той або інший алгоритм нечіткого виводу. Нині залишається відкритим питання критеріїв і методів вибору алгоритму нечіткого виводу залежно від конкретного технічного завдання. На даний момент в системах нечіткого виводу найчастіше застосовуються наступні алгоритми [6].
1.3.1 Алгоритми нечіткого виводу
Алгоритми нечіткого виводу:
1) Алгоритм Мамдані
(рис. 1.2) знайшов застосування в перших нечітких системах автоматичного
управління. Був запропонований в 1975 році англійським математиком Е.Мамдані
для управління паровим двигуном [8 ].
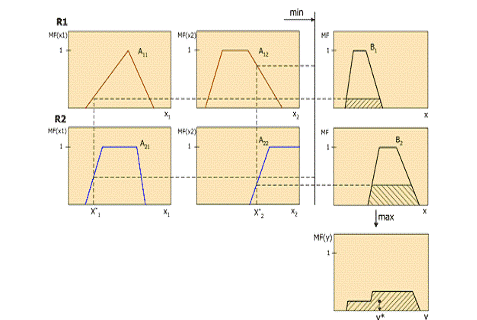
Рисунок 1.2 - Алгоритм Мамадані
Алгоритм Мамдані виглядає таким чином:
Формування бази правил системи нечіткого виводу здійснюється у вигляді впорядкованого погодженого списку нечітких продукційних правил у вигляді «IF A THEN B », де антициденти ядер правил нечіткої продукції побудовані за допомогою логічних зв'язок «И», а консеквенти ядер правил нечіткої продукції прості.
Фаззифікація вхідних змінних здійснюється описаним вище способом, так само, як і в загальному випадку побудови системи нечіткого виводу.
Агрегація підумов правил нечіткої продукції здійснюється за допомогою класичної нечіткої логічної операції «И» двох елементарних висловлювань A, B: T(A ∩ B) = min{ T(A);T(B)}.
Активізація підвисновків правил нечіткої продукції здійснюється методом min-активизации м (y) = min{c; м (x)}, де м (x) і c - відповідно до функції приналежності термів лінгвістичних змінних і міри істинності нечітких висловлювань, що утворюють відповідні наслідки (консиквенти) ядер нечітких продукційних правил.
- Акумуляція підвисновків
правил нечіткої продукції проводиться за допомогою класичного для нечіткої
логіки max - объединения функцій приналежності ![]() x
x ![]() X м A B x = max{м A x; м B x}.
X м A B x = max{м A x; м B x}.
Дефаззифікація проводиться методом центру тяжіння або центру площі.
) Алгоритм Цукамото (Tsukamoto) формально виглядає таким чином:
Формування бази правил системи нечіткого виводу здійснюється аналогічно алгоритму Мамдані.
Фаззифікація вхідних змінних здійснюється аналогічно алгоритму Мамдані.
Агрегація підумов правил нечіткої продукції здійснюється аналогічно алгоритму Мамдані за допомогою класичної нечіткої логічної операції «И» двох елементарних висловлювань A, B: T(A ∩ B) = min{ T(A);T(B)}.
Активізація підвисновків правил нечіткої продукції проводиться в два етапи. На першому етапі, міри істинності висновків (консиквентів) нечітких продукційних правил знаходяться аналогічно алгоритму Мамдані, як твір алгебри вагового коефіцієнта і міри істинності антецедента цього нечіткого продукційного правила. На другому етапі, на відміну від алгоритму Мамдані, для кожного з продукційних правил замість побудови функцій приналежності підвисновків вирішується рівняння м (x)=c і визначається чітке значення щ вихідної лінгвістичної змінної, де м (x) і c - відповідно до функції приналежності термів лінгвістичних змінних і міри істинності нечітких висловлювань, що утворюють відповідні наслідки (консиквенти) ядер нечітких продукційних правил.
Акумуляція висновків правил нечіткої продукції не проводиться, оскільки на етапі активізації вже отримана дискретна безліч чітких значень для кожного з вихідних лінгвістичних змінних.
На етапі дефаззифікації для кожної лінгвістичної змінної здійснюється перехід від дискретної безлічі чітких значень { w 1... w n } до єдиного чіткого значення згідно з дискретним аналогом методу центру тяжіння y= ∑ i = 1 n c i щ i ∑ i = 1 n c i, де n - кількість правил нечіткої продукції, в підвисновках якої фігурує ця лінгвістична змінна, c i - міра істинності підукладення продукційного правила, w i - чітке значення цієї лінгвістичної змінної, отримане на стадії активізації шляхом рішення рівняння м (x)= c i, тобто м(wi)= c i, а м (x) представляє функцію приналежності відповідного терма лінгвістичний змінної.
) Алгоритм Ларсена формально виглядає таким чином:
Формування бази правил системи нечіткого виводу здійснюється аналогічно алгоритму Мамдані.
Фаззификация вхідних змінних здійснюється аналогічно алгоритму Мамдані.
Агрегація підумов правил нечіткої продукції здійснюється аналогічно алгоритму Мамдані за допомогою класичної нечіткої логічної операції «И» двох елементарних висловлювань A, B: T(A ∩ B) = min{ T(A);T(B)}.
Активізація підвисновків правил нечіткої продукції здійснюється методом prod-активизации, м (y)=c м (x), де м (x) і c - відповідно до функції приналежності термів лінгвістичних змінних і міри істинності нечітких висловлювань, що утворюють відповідні наслідки (консиквенти) ядер нечітких продукційних правил.