Материал: ответы на экзамен МБХ 1-22
20. Выполнение статистических вычислений средствами табличного процессора ms Excel. Статистические функции. Пакет Анализ данных. Назначение, примеры.
Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области.
Для такого рода вычислений будем пользоваться встроенными функциями. Рассмотрим некоторые из них.
1) =СЧЕТ (значение1; значение2;…), которая подсчитывает количество чисел в списке аргументов. Функция СЧЁТ используется для получения количества числовых ячеек в интервалах или массивах ячеек.
2) =СЧЕТЕСЛИ (диапазон; критерий), где диапазон – диапазон, в котором нужно подсчитать ячейки. Критерий – критерий в форме числа, выражения или текста, который определяет, какие ячейки надо подсчитывать.
3) =СРЗНАЧ (число1; число2; ...), которая возвращает среднее (арифметическое) своих аргументов.
4) =МЕДИАНА (число1;число2;...). Медиана – это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана.
5) =МОДА (число1;число2;...). МОДА определяет значение, которое чаще других встречается во множестве чисел.
6) =МАКС (число1;число2; ...). Число1, число2,...– от 1 до 30 чисел, среди которых требуется найти наибольшее.
7) =МИН (число1;число2; ...). Число1, число2,...– от 1 до 30 чисел, среди которых требуется найти наименьшее.
8) если числовые значения образуют полную генеральную совокупность, то для вычисления дисперсии и стандартного отклонения (среднего квадратического отклонения) используются функции ДИСПР и СТАНДОТКЛОНП.
9) функции ДИСП и СТАНДОТКЛОН используются, если необходимо произвести вычисления дисперсии и стандартного отклонения по выборке.
Если встроенных статистических функций недостаточно, можно обратиться к Пакету анализа.
Пакет анализа в MS Excel является надстройкой и содержит коллекцию функций и инструментов, расширяющих его возможности. Пакет анализа можно использовать для:
– создания гистограмм;
– ранжирования данных;
– извлечения случайных или периодических выборок из набора данных;
– проведения регрессионного анализа (статистический метод, позволяющий найти уравнение, наилучшим образом описывающее совокупность данных);
– получение основных статистических характеристик выборки, генерации случайных чисел с различным распределением.
Доступ к определенному инструменту Пакету анализа может быть обеспечен следующим образом:
1. Выполнить команду Сервис – Анализ данных.
Если указанный выше пункт меню отсутствует, то необходимо установить соответствующий компонент, выполнив команду Сервис – Надстройки. В диалоговом окне выбрать Пакет анализа. Затем следует повторить пункт 1.
2. Выбрать нужный инструмент в списке.
Опишем назначение некоторых наиболее часто употребляющиеся инструментов Пакета анализа:
Описательная статистика – позволяет создавать таблицу основных статистических характеристик для одного или нескольких множеств входных значений. Выходной диапазон этого инструмента содержит таблицу со статистическими характеристиками для каждой переменной из входного диапазона (среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия выборки, коэффициент эксцесса, коэффициент ассиметрии, размах и др.)
Инструмент Гистограмма – позволяет построить диаграмму (обычно столбчатую), где для исходного множества значений определяется и отображается число значений, попадающих в интервалы разбиения. Инструмент Гистограмма имеет три аргумента: место расположения данных, место расположение границ интервалов разбиения и верхнюю левую ячейку выходного диапазона, в котором выводятся результаты. Инструмент Гистограмма может создавать отсортированные гистограммы (Парето), выводить накопленные проценты и генерировать диаграммы.
Инструмент Генерация случайных чисел позволяет построить ряд случайных величин, подчиняющихся заданному закону распределения (равномерному, нормальному, биноминальному, Пуассона, дискретному).
21. Понятие дисперсионного анализа. Однофакторный и двухфакторный дисперсионный анализ. Использование средств ms Excel для решения задач на дисперсионный анализ.
Дисперсионный анализ применяется для исследования влияния одной или нескольких качественных переменных (факторов) на одну зависимую количественную переменную (отклик).
В основе лежит предположение о том, что одни переменные могут рассматриваться как причины (факторы, независимые переменные), а другие как следствия (зависимые переменные). Основной целью ДА является исследование значимости различия между средними с помощью сравнения дисперсий.
Вариабельность – степень многообразия вариантов, в которой он встречается. Изменчивость признака может быть исследована как в целом для выборки, так и для какой-либо её части/группы. Если даны 2/3 и > выборки то применяется дисперсионный анализ. Это метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путем исследования значимости различий вариабельности признака в исследуемой совокупности.
Базируется на определении степени рассеивания (дисперсия), следовательно, позволяет измерить силу влияния отдельных факторов на значения показателей. Сущность в изучении статистического влияния одного исследуемых факторов на результирующий признак. Фактор – влияние, воздействие/состояние, которое отражается на размерах и различии результирующего признака, который представляет собой элементарное свойство объектов, изучаемое как результат влияния факторов.
Градации факторов – степень воздействия фактора, в том числе отсутствие воздействия (нулевое значение) в конкретной группе/состояние объектов изучения.
Дисперсионный комплекс – совокупность градаций, изучаемых данных с вычисленными значениями относительных/средних величин по каждой градации.
Статистическое влияние - отражение в разнообразии результирующего признака того разнообразия факторов, которое организованно в исследовании.
Факториальное влияние – простое комбинированное статистическое влияние изучаемых факторов. Случайное влияние – действие тех факторов, которые не учтены в дисперсионном комплексе и составляют общий фон, на который действуют учитываемые факторы.
Зависимые переменные (факторы) – что я наблюдаю? – не зависят от испытуемых, но зависят от эксперимента, который обязан их четко контролировать. Независимые переменные – что я измеряю? – зависят от факторов и независимых переменных.
Условия применения дисперсионного анализа:
-выборочные данные должны быть взяты из нормальных совокупностей
-исправленные выборочные дисперсии каждого уровня контрольного фактора должны быть равны
-результаты наблюдений должны быть независимыми
Алгоритм исполнения дисперсионного анализа:
1.фрмулировка (выделение) гипотез
2.нахождение наблюдаемого и критического значения критерия
3.сравнение найденных значений
4.вывод согласно пункту 3.
Однофакторный и двухфакторный дисперсионный анализ.
Исходным материалом для ДА служат данные исследования трех и более выборок x1, x2..., которые могут быть как равными, так и неравными по численности, как связными, так и несвязными. По количеству выявляемых регулируемых факторов ДА может быть однофакторным (изучается влияние одного фактора на результаты эксперимента), двухфакторным (при изучении влияния двух факторов) и многофакторным (позволяет оценить не только влияние каждого из факторов, но и их взаимодействие). Обычно в медико-биологических исследованиях используются только однофакторные, максимум двухфакторные ДА. Однофакторный и двухфакторный анализы реализуются средствами MS Excel с помощью пакета анализа.
Алгоритм: 1.создать и открыть файл MS Excel
2.на листе 1 создать таблицу значений, полученную в результате исследования, лист 1 переименовать в дисперсионный анализ
3.в ячейку F1 внести информацию о признаке, в F2 о факторе, в F3 – об уровнях фактора
4.формулировка и выдвижение гипотез. В соответствующую ячейку информацию о нулевой гипотезе и об альтернативной гипотезе (средние значения не равны между собой)
5.используя анализ данных – однофакторный дисперсионный анализ получить результирующую таблицу
6.нахождение табличного и критического значений критерия. Вывод о принятии Н0/Н1 гипотез можно сделать, используя р-критерий
7.сравнение найденных значений, вывод о принятии гипотезы
-используя Fнабл и Fкрит, если >, то при уровне значимости 0,05 фактор F оказывает существенное влияние на признак х, Н0 отвергается; если <,то F не оказывает существенного влияния на признак х, Н0 следует принять.
-используя р-значения, если р<0,05, то при уровне значимости 0,05 фактор F оказывает существенное влияние на признак х, Н0 отвергается; и наоборот
8.вывод согласно пункту 7
7.*найти суммы, средние значения, число значений по каждому уровню фактора и вместе, используя формулы или мастер функций.
Дисперсионный анализ используют, если зависимая переменная измеряется в шкале отношений, интервалов или порядка, а влияющие переменные имеют нечисловую природу.
22. Понятие корреляционного анализа. Использование средств ms Excel для решения задач на корреляционный анализ.
Корреляционный анализ – решает задачи обнаружения связей между варьирующими признаками и установления характера этих связей. Корреляционная связь не является точной зависимостью одного признака от другого – она может иметь различную степень: от полной независимости до очень сильной связи. Кроме того, характер связи между признаками может быть различен по форме и направлению.
Различается по форме (прямо- и криволинейный) и направлению (прямой+ и обратной-). Степень корреляции устанавливается показателями: rxy, корреляционное отношение, тетрахорический, полихорический, частный и множественный коэффициент.
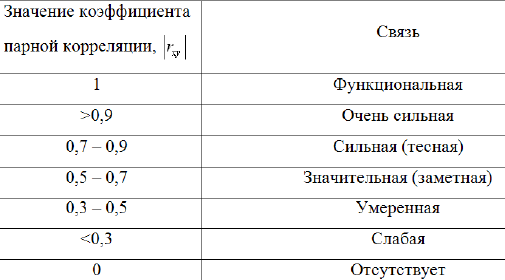
Коэффициент парной корреляции – измеряет степень и определяет направление только прямолинейных связей. При отрицательной корреляционной связи увеличение одной из переменных ведет к уменьшению другой. Соответствие между значениями rxy и характером связи может быть представлено следующей таблицей:
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ В MS EXCEL
Для реализации процедуры необходимо:
1.Выполнить команду Сервис>Анализ данных.
2.В появившемся списке Инструменты анализа выбрать строку Корреляция и нажать кнопку OK.
3.В появившемся диалоговом окне указать входной диапазон, т. е. ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши. Входной диапазон должен содержать не менее двух столбцов.
4. В разделе Группировка переключатель устанавливается в положение по столбцам.
5. Указать выходной диапазон, т. е. ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить флажок в левое поле Выходной диапазон (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши в правое поле ввода Выходной диапазон и щелкнуть левой кнопкой мыши, затем указатель мыши наводится на левую верхнюю ячейку выходного диапазона и делается щелчок левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.
6. Нажимается кнопка OK.
Результаты анализа. В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении соответствующих строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строки столбцов, содержат значение1, так как каждый столбец во входном диапазоне полностью коррелирует с самим собой.
Интерпретация результатов. Если коэффициент корреляции (r) по абсолютной величине (без учета знака) больше чем 0,95, то принято считать, что между параметрами существует практически линейная зависимость (прямая при положительном r и обратная при отрицательном r). Если коэффициент корреляции r лежит в диапазоне от 0,8 до 0,95, говорят о сильной степени линейной связи между параметрами. Если 0,6<r<0,8–говорит о наличии линейной связи между параметрами. При r<0,4 обычно считают, что линейную взаимосвязь между параметрами выявить не удалось.
rxy – безразмерная величина, значение которой принадлежит отрезку ( при – корреляционной связи увеличение одних переменных ведет к уменьшению других).
Функциональная связь – связь, при которой любому значению одного из признаков соответствует строго определенное значение другого.
Корреляционная связь – связь, при которой значению каждой средней величины 1 признака соответствует несколько значений другого взаимосвязанного с ними признака.
Задачи корреляционного анализа:
-измерение степени связанности
-отбор факторов, оказывающих наиболее существенное влияние на результативный признак, на основании измерения степени связности между явлениями
-обнаружение направления связи между признаками (прямая – при увеличении одного признака увеличивается другой и обратная - наоборот).
Связь значений коэффициента корреляции и степени взаимосвязи признаков
значение rxy 0 0-0,3 0,3-0,7 0,7> |
степень взаимосвязи отсутствует слабая средняя функциональная |
Методы, реализующие корреляционный анализ
1.параметрический анализ по Пирсону – используется при решении задач исследования – связи двух нормально распределенных параметров (значение коэф.коррел. - 0,88). =коррел
Матем.
Ф-ла: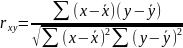
Проверка достоверности коэф.коррел: Н0 rxy=0, связь между признаками отсутствует; Н1 rxy отличен от 0, связь существует.
Если наблюдаемое значение > критического, то rxy и связь между признаками считают достоверной.
2.непараметрический анализ по Спирмену – применяется при обнаружении взаимосвязи 2ух параметров, если распределение хотябы одного из них отличается от нормального (значение коэф.коррел – 0,98).
Матем
ф-ла:
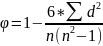
Проверка достоверности коэф.коррел.: Н0 rxy =0, связь отсутствует; Н1 rxy отличен от 0, связь существует.
Наблюдаемое > критического, то Н0 необходимо отвергнуть, т.е. связь существует и достигается при условии 0,05.