Материал: Л-9 - Методы доступа к данным
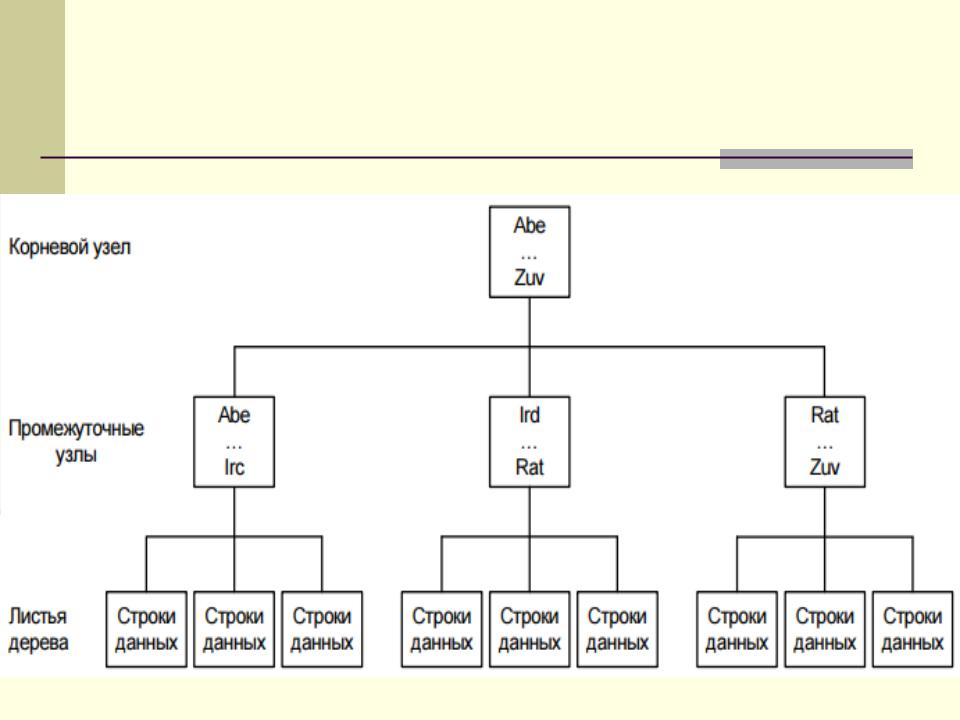
Физическая структура кластеризованных индексов

Особенности кластеризованного индекса
Кластеризованный индекс создается по умолчанию для каждой таблицы, в которой определен первичный ключ.
Каждый кластеризованный индекс однозначен по умолчанию. Если кластеризованный индекс создается для столбца с повторяющимися значениями, СУБД принудительно обеспечивает однозначность, добавляя 4-байтовый идентификатор к строкам, содержащим дубликаты.
Кластеризованные индексы обеспечивают очень быстрый доступ к данным, когда запрос осуществляет поиск в диапазоне значений.

Некластеризованные индексы
Структура некластеризованного индекса такая же, как и кластеризованного, но с двумя важными отличиями:
некластеризованный индекс не изменяет физическое упорядочивание строк таблицы;
страницы листьев некластеризованного индекса состоят из ключей индекса и закладок.
Если для таблицы определить один или более некластеризованных индексов, физический порядок строк таблицы не будет изменен.
Для каждого некластеризованного индекса СУБД создает индексную структуру в индексных страницах.
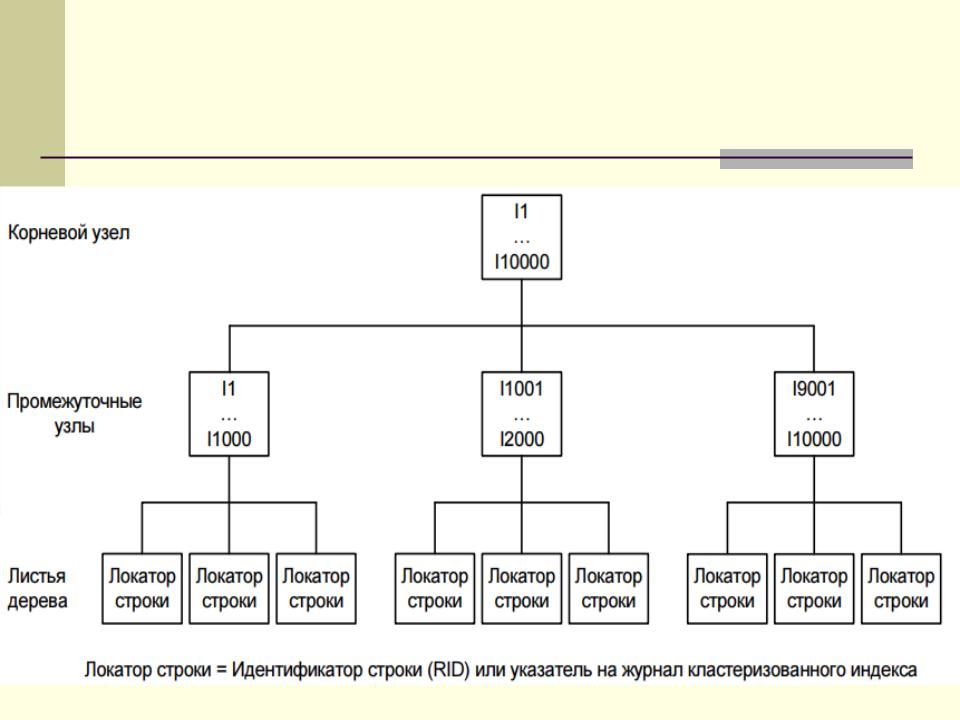
Физическая структура некластеризованных индексов

Использование индексов
Индекс создается командой:
CREATE INDEX <имя_индекса>
ON <имя_таблицы> (<поле1> [, <поле2>, ... ] ) [<параметры>];
Имя индекса должно быть уникальным среди объектов БД. Поля составного индекса перечисляются через запятую; <параметры> зависят от СУБД.
Составной индекс для таблицы СОТРУДНИКИ (ЕМР) по полям Фамилия (fam) и Имя (name):
CREATE INDEX ind_emp_name ON emp(fam, name);