Дипломная (вкр): Компьютерная реализация информационно-моделирующей системы для процессов химической очистки теплоэнергетического оборудования
![]() (2.4)
(2.4)
![]() (2.5)
(2.5)
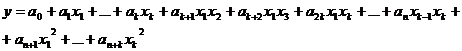 (2.6)
(2.6)
Исходные экспериментальные данные представлены в таблице 2.5.
Таблица 2.5 - Экспериментальные данные для множественной регрессии
|
Номер опыта |
x1 |
x2 |
… |
xk |
y |
|
1 |
x11 |
x21 |
… |
xk1 |
y1 |
|
2 |
x12 |
x22 |
… |
xk2 |
y2 |
|
… |
… |
… |
… |
… |
… |
|
n |
x1n |
x2n |
… |
xkn |
yn |
Для построения модели множественной регрессии, имеющей вид (2.4),
необходимо перейти от натурального масштаба к новому, проведя нормировку всех
значений случайных величин по формулам:
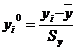 ,
,
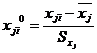 ,
,
где
![]() ,
, ![]() -
нормированные значения соответствующих факторов;
-
нормированные значения соответствующих факторов;
![]() ,
, ![]() - средние значения факторов;
- средние значения факторов;
![]() ,
, ![]() - среднеквадратичные отклонения факторов.
- среднеквадратичные отклонения факторов.
Среднеквадратичные
отклонения определяются по формулам:
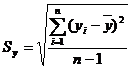
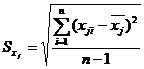
Исходные экспериментальные данные в нормированном виде представлены в
таблице 2.6.
Таблица 2.6 - Экспериментальные данные в нормированном виде
|
Номер опытаx10x20…xk0y0 |
|
|
|
|
|
|
1 |
x110 |
x210 |
… |
xk10 |
y10 |
|
2 |
x120 |
x220 |
… |
xk20 |
y20 |
|
… |
… |
… |
… |
… |
… |
|
n |
x1n0 |
x2n0 |
… |
xkn0 |
yn0 |
В новом масштабе xj0 = 0, y0 = 0.
Выборочные коэффициенты корреляции будут определяться по формулам:
![]()
![]() ,
, ![]()
Коэффициенты уравнения также как и в регрессии от одного параметра
находятся по методу наименьших квадратов из условия. В результате для их нахождения
необходимо решить систему уравнений, которая имеет вид:
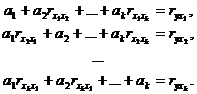 (2.7)
(2.7)
В
системе уравнений (2.7) ![]() . Решив систему, необходимо определить коэффициент
множественной корреляции, который определяется по формуле:
. Решив систему, необходимо определить коэффициент
множественной корреляции, который определяется по формуле:
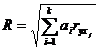
Коэффициент множественной корреляции определяет оценку силы связи для
множественной регрессии. Также лежит в интервале от 0 до 1. Для маленького
объема входных данных в величину R
нужно занести корректировку на систематическую ошибку. Чем менее количество
степеней свободы входных данных, тем более завышает сила связи, которая
определяется коэффициентом множественной корреляции, его скорректированное
значение определяется по формуле:
![]()
Адекватность модели определяется по критерию Фишера, аналогичным образом, как и для регрессии от одного параметра при отсутствии параллельных опытов, используя формулы (2.1), (2.2), (2.3).
Для расчета коэффициентов уравнений вида (2.5) и (2.6) используется метод градиентов. Задаются первоначальные значения параметров модели, рассчитывается дисперсия отклонений, после определяется направление изменения каждого коэффициента, сравнивая получившиеся после дисперсии отклонений. По нахождению направления изменения коэффициента, он изменяется до тех пор, пока дисперсия отклонений не станет минимальной. Коэффициент корреляции и проверка адекватности моделей для данных видов проводятся аналогичным образом, как и для линейной множественной регрессии без взаимодействий.
В результате изучения математического моделирования на основе
корреляционно-регрессионного анализа была разработана идентификация параметров
математических моделей, которая представлена на рисунке 2.2.
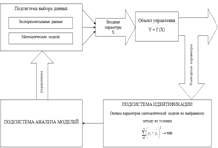
Рисунок 2.2 - Идентификация параметров математических моделей
Оценка параметров математических моделей производится из условия, что сумма квадратов отклонений от экспериментальных данных стремится к минимуму. Подсистема анализа моделей выбирает оптимальную модель, исходя из условия оценки параметров математических моделей, которая представлена в идентификации параметров.
2.4 Математическое моделирование на основе дисперсионного анализа
Математическое моделирование на основе дисперсионного анализа в информационно-моделирующей системе для процессов химической очистки теплоэнергетического оборудования исследует значимость факторов на изменение средних значений наблюдаемых качественных величин [18].
Для однофакторного дисперсионного анализа экспериментальные данные
представлены в таблице 2.7.
Таблица 2.7 - Экспериментальные данные для однофакторного анализа
|
Номер измерения |
Уровни фактора А |
|||
|
|
a1 |
a2 |
… |
ap |
|
1 |
y11 |
y12 |
… |
y1p |
|
2 |
y21 |
y22 |
… |
y2p |
|
… |
… |
… |
… |
… |
|
q |
yq1 |
yq2 |
… |
yqp |
Для каждого уровня фактора необходимо найти групповые средние значения,
определяющиеся по формуле:
![]() (2.8)
(2.8)
Общее среднее определяется по формуле:
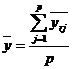 (2.9)
(2.9)
Остаточная сумма отражает влияние случайной величины, определяется по
формуле:
![]() (2.10)
(2.10)
Факторная сумма показывает воздействие фактора, находится по формуле:
![]() (2.11)
(2.11)
Общая сумма определяется по формулам:
![]() (2.12)
(2.12)
![]() (2.13)
(2.13)
Общая, остаточная и факторная дисперсии определяются по формулам:
![]() (2.14)
(2.14)
![]() (2.15)
(2.15)
![]() (2.16)
(2.16)
В знаменателях указаны степени свободы fобщ, fфакт и fост соответственно.
Значимость фактора определяется по критерию Фишера:
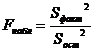 (2.17)
(2.17)
Если наблюдаемое значение критерия Фишера для уровня значимости α=0,05 и степеней свободы fфакт и fост меньше критического, то фактор значим.
Для двухфакторного дисперсионного анализа экспериментальные данные
представлены в таблице 2.8.
Таблица 2.8 - Экспериментальные данные для двухфакторного анализа
|
Уровни фактора B |
Уровни фактора А |
|||
|
|
a1 |
a2 |
… |
ap |
|
b1 |
y11 |
y12 |
… |
y1p |
|
b2 |
y21 |
y22 |
… |
y2p |
|
… |
… |
… |
… |
… |
|
bq |
yq1 |
yq2 |
… |
yqp |
Для фактора А используют те же формулы, что и для однофакторного дисперсионного анализа (2.8)-(2.17).
Для фактора В аналогично считаются групповые средние, факторная сумма, остаточная и факторная дисперсии.
Групповые средние для фактора В определяются по формуле:
![]()
Факторная сумма для фактора В находится по формуле:
![]()
Остаточная и факторная дисперсии для фактора В определяются по формулам:
![]()
![]()
Значимость фактора В также определяется по критерию Фишера по формуле (2.17).
Различие между средними значениями определяется при помощи множественного рангового критерия Дункана. Рассмотрим его на факторе А двухфакторного дисперсионного анализа, аналогичным образом он определяется и для фактора В.
У
нас рассчитаны все групповые средние ![]() .
Необходимо расположить их в порядке возрастания. Дальше следует определить
ошибку воспроизводимости с соответствующим числом степеней свободы. Нужно
определить ошибку для каждого среднего по формуле:
.
Необходимо расположить их в порядке возрастания. Дальше следует определить
ошибку воспроизводимости с соответствующим числом степеней свободы. Нужно
определить ошибку для каждого среднего по формуле:
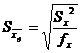
где
![]() - дисперсия воспроизводимости;
- дисперсия воспроизводимости;
![]() -
степень свободы.
-
степень свободы.
Дальше надо выписать из таблицы Дункана p-1 значений рангов с выбранным уровнем значимости, умножить эти значения на ошибку для каждого среднего и таким образом определить p-1 наименьших значимых рангов. После следует проверить значимость различия между средними, начиная с крайних в ранжировочном ряду; разность максимального и минимального значений среднего сравнить с наименьшим значимым рангом, затем найти разность максимального среднего и второго среднего в ранжировочном ряду и сравнить ее с наименьшим значимым рангом и так далее. Это сравнение продолжить для второго по величине среднего, которое сравнивается с наименьшим, и так далее, пока не будут исследованы на значимость различия между всеми парами.
В
латинском квадрате в одной таблице данных находятся три фактора, расчеты для
них осуществляются аналогично однофакторному и двухфакторному анализам,
расположение данных для каждого фактора представлено на примере в таблице 2.9.
Таблица 2.9 - Данные для латинского квадрата
|
Уровни фактора В |
Уровни фактора А |
||
|
|
a1 |
a2 |
a3 |
|
b1 |
c1 |
c2 |
c3 |
|
b2 |
c2 |
c3 |
c1 |
|
b3 |
c3 |
c1 |
c2 |
То есть первому уровню фактора А соответствуют клетки (1,1), (2,1), (3,1), где первое число - строка, второе число - столбец. Для первого уровня фактора В соответствуют клетки (1,1), (1,2), (1,3). Для фактора С первый уровень содержит данные клеток (1,1), (3,2), (2,3).
В греко-латинском квадрате в таблице данных находятся четыре фактора.
Расчеты каждого фактора также аналогичны, пример расположения четырех факторов
представлен в таблице 2.10.
Таблица 2.10 - Данные для греко-латинского квадрата
|
Уровни фактора В |
Уровни фактора А |
||
|
|
a1 |
a2 |
a3 |
|
b1 |
c1 d1 |
c2 d2 |
c3 d3 |
|
b2 |
c2 d3 |
c3 d1 |
c1 d2 |
|
b3 |
c3 d2 |
c1 d3 |
c2 d1 |
В гипер-греко-латинском квадрате в таблице данных находятся пять
факторов. Пример расположения пяти факторов представлен в таблице 2.11.
Таблица 2.11 - Данные для гипер-греко-латинского квадрата
|
Уровни фактора В |
Уровни фактора А |
||||
|
|
a1 |
a2 |
a3 |
a4 |
a5 |
|
b1 |
c1 d1 e1 |
c2 d2 e2 |
c3 d3 e3 |
c4 d4 e4 |
c5 d5 e5 |
|
b2 |
c2 d3 e4 |
c3 d4 e5 |
c4 d5 e1 |
c5 d1 e2 |
c1 d2 e3 |
|
b3 |
c3 d5 e2 |
c4 d1 e3 |
c5 d2 e4 |
c1 d3 e5 |
c2 d4 e1 |
|
b4 |
c4 d2 e5 |
c5 d3 e1 |
c1 d4 e2 |
c2 d5 e3 |
c3 d1 e4 |
|
b5 |
c5 d4 e3 |
c1 d5 e4 |
c2 d1 e5 |
c3 d2 e1 |
c4 d3 e2 |
2.5 Принципы построения информационно-моделирующей системы на основе теории конечных автоматов
Конечные автоматы в целом подразумевают наличие входного потока данных, с помощью которых обрабатывается ограниченное количество состояний алгоритма, по достижению одного конечного состояния алгоритм и вычисления завершаются.
В данной реализации для решения поставленной задачи используется
клеточно-автоматная модель, где каждая клетка имеет свое состояние, которое
определяется наличием или отсутствием отложений в ней. На основе входных данных
происходят переходы по состояниям с целью расчета количества необходимого
реагентов для очистки определенного вида отложений. Клеточно-автоматная модель
в графической реализации представляет собой поле, что будет являться неким
разрезом теплоэнергетического оборудования. Коэффициент занятых отложением
клеток данного поля определяется по формуле: