Дипломная (вкр): Компьютерная реализация информационно-моделирующей системы для процессов химической очистки теплоэнергетического оборудования
В форме удаления данных для корреляционно-регрессионного и дисперсионного
анализов, что представлено на рисунке 4.5, после выбора необходимого вида
анализа выводятся все сохраненные в базу данных наименования технологических
процессов, после удаления нужных в соответствующей форме следует сохранить
изменения, нажав на необходимую кнопку.
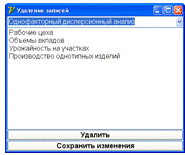
Рисунок 4.5 - Форма удаления данных
4.2.1 Подсистема «Корреляционно-регрессионный анализ»
На главной форме корреляционно-регрессионного анализа, выбрав пункт
«Модели» - «Регрессия от 1 параметра» - «Нет параллельных опытов», переходим на
форму ввода наименования процесса (следует указывать уникальное наименование,
который не сохранен в базу данных) и ввода количества измерений. Сохраненные в
базе данных наименования процессов повторно информационно-моделирующая система
использовать не даст, будет выведена соответствующая ошибка (такая же ошибка
выдаст при аналогичном повторном использовании наименования процесса в
остальных видах анализов корреляционно-регрессионного, дисперсионного, анализа
на основе теории конечных автоматов). После будет показана форма заполнения
экспериментальных данных, представленная на рисунке 4.6. Изначально вводятся
экспериментальные данные для первого опыта (входной параметр X и выходной параметр Y), после чего по нажатию кнопки
«Задать» переходим к вводу экспериментальных данных для второго опыта и так
далее. Форма будет показана до тех пор, пока все опыты не будут занесены в
информационно-моделирующую систему, после чего будет показана соответствующая
форма моделирования.
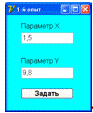
Рисунок 4.6 - Форма заполнения экспериментальных данных без параллельных
опытов
Выбрав вид анализа «с параллельными опытами», также после ввода
наименования технологического процесса и ввода количества измерений будет
показана форма заполнения экспериментальных данных, представленная на рисунке
4.7. На форме ввода экспериментальных данных с параллельными опытами следует
ввести соответствующее значение входного параметра Х и все выходные параметры Y (каждое значение с новой строки).
Аналогично вводятся экспериментальные данные для регрессии от одного параметра
с одинаковым количеством параллельных опытов, для множественной регрессии
(вводится соответствующее значение выходного параметра Y и все входные параметры Х), для однофакторного (вводятся все
значения, расположенных на разных уровнях фактора, для каждого опыта) и
двухфакторного дисперсионных анализов (вводятся все значения для каждого уровня
первого фактора).
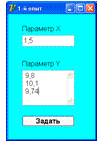
Рисунок 4.7 - Форма заполнения экспериментальных данных с параллельными
опытами
Форма вывода результатов для регрессии от одного параметра представлена
на рисунке 4.8. С помощью пункта «Данные» можно вывести результаты моделирования
либо изменить экспериментальные данные. С помощью пункта «График» можно
построить либо убрать графики с разными видами регрессий (линейная,
параболическая, гиперболическая, полулогарифмическая, показательная,
степенная), а также построить либо убрать точечный график с введенными
экспериментальными данными. С помощью пункта «Файл» можно сохранить график,
сохранить полученные данные о технологическом процессе в базу данных,
распечатать график, установить настройки принтера, выйти из формы.
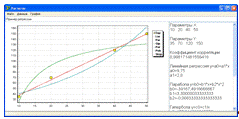
Рисунок 4.8 - Форма вывода результатов для регрессии от одного параметра
Форма ввода экспериментальных данных для множественной регрессии после
ввода названия процесса и количества опытов и факторов имеет следующий вид, который
представлен на рисунке 4.9.
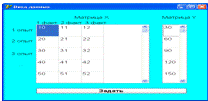
Рисунок 4.9 - Форма ввода данных для множественной регрессии
Форма результатов для множественной регрессии представлена на рисунке
4.10. С помощью пункта «Данные» можно вывести результаты моделирования либо
изменить экспериментальные данные.
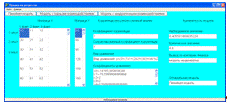
Рисунок 4.10 - Форма результатов для множественной регрессии
Формы показа сохраненной модели для корреляционно-регрессионного анализа имеют аналогичный вид, что и формы результатов моделирования.
Первый пример. В таблице 4.1 собраны экспериментальные данные для
регрессии от одного параметра. Необходимо составить модели регрессии и найти
оптимальную модель.
Таблица 4.1 - Экспериментальные данные для регрессии
|
Номер опыта |
x |
y1 |
y2 |
y3 |
|
1 |
4,5 |
9,6 |
9,9 |
9,7 |
|
2 |
6,3 |
14 |
15 |
- |
|
3 |
8,9 |
18 |
- |
- |
|
4 |
10 |
20 |
20 |
- |
Результаты моделирования представлены на рисунке 4.11.
Коэффициент корреляции получился равным 0,989, что говорит о сильной связи фактора.
Оптимальной моделью оказалась гипербола, которая имеет вид:
![]()
Оба коэффициента уравнения по критерию Стьюдента значимы (критическое
значение 2,78, а наблюдаемые значения 18,05 и 8,26 соответственно).
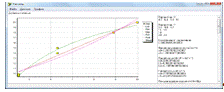
Рисунок 4.11 - Результаты моделирования регрессии
Второй пример. В таблице 4.2 представлены экспериментальные данные для
множественной регрессии. Необходимо составить модели множественной регрессии и
найти оптимальную модель.
Таблица 4.2 - Экспериментальные данные для множественной регрессии
|
Номер опытаx1x2x3y |
|
|
|
|
|
1 |
0,5 |
0,4 |
0,3 |
1,5 |
|
2 |
1,5 |
1,2 |
1,4 |
4,5 |
|
3 |
2,5 |
3,1 |
2,3 |
7,5 |
|
4 |
3,1 |
2,8 |
3,3 |
9,2 |
|
5 |
4,1 |
4,5 |
3,9 |
|
|
6 |
4,6 |
5,1 |
5,2 |
15,3 |
|
7 |
5,3 |
6,2 |
5,4 |
16,4 |
|
8 |
2,8 |
3,9 |
4,2 |
9,1 |
|
9 |
6,3 |
7,1 |
8,3 |
20,6 |
|
10 |
10,5 |
3,5 |
15,2 |
27,6 |
|
11 |
2,1 |
12,6 |
3,5 |
18,4 |
Результаты моделирования представлены на рисунке 4.12.
Коэффициент корреляции равен 0,99, что говорит о сильной связи факторов.
Уравнение множественной регрессии имеет вид:
![]()
По критерию Фишера наблюдаемое значение равно 1,36, критическое значение
равно 5,3. В результате построенная модель множественной регрессии адекватна.
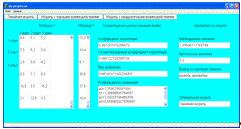
Рисунок 4.12 - Результаты моделирования множественной регрессии
4.2.2 Подсистема «Дисперсионный анализ»
Компьютерная реализация ввода данных и просмотра результатов для
дисперсионного анализа ниже приведена на гипер-греко-латинском квадрате в
качестве примера. Для остальных видов дисперсионного анализа ввод данных и
просмотр результатов выглядят аналогичным, схожим образом. Форма ввода
экспериментальных данных для дисперсионного анализа уже после ввода уникального
наименования процесса для данного вида моделирования и ввода количества уровней
факторов представлена на рисунке 4.13. Уровни первого фактора представляются в
виде столбцов, уровни второго фактора указаны в строках таблицы данных. Чтобы
узнать адреса ячеек третьего, четвертого и пятого уровней факторов необходимо
нажать на соответствующую кнопку. После нажатия кнопки «Задать» открывается
форма вывода параметров моделирования, что представлено на рисунке 4.14. По
нажатию на кнопку с названием определенного фактора выводятся таблица данных,
показатели критерия Фишера и Дункана.

Рисунок 4.13 - Форма ввода данных дисперсионного анализа
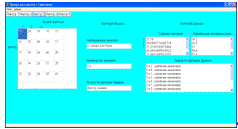
Рисунок 4.14 - Форма вывода результатов моделирования дисперсионного анализа
Третий пример. Имеются данные для однофакторного анализа, представленные
в таблице 4.3. Необходимо составить модель дисперсионного анализа.
Таблица 4.3 - Экспериментальные данные для дисперсионного анализа
|
Уровни |
Фактор |
|||
|
1 |
2,8 |
2,6 |
2,5 |
2,1 |
|
2 |
2,4 |
2,8 |
2,8 |
2,7 |
|
3 |
2,3 |
2,4 |
2,6 |
2 |
|
4 |
2,9 |
2,8 |
2,8 |
2,4 |
Результаты моделирования представлены на рисунке 4.15.
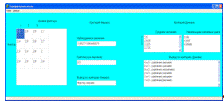
Рисунок 4.15 - Результаты моделирования дисперсионным анализом
По критерию Фишера наблюдаемое значение получилось равным 1,96, а критическое 3,5. В результате получаем, что фактор значим. По критерию Дункана только одно различие между средними значениями незначимо.
4.2.3 Подсистема «Моделирование на основе конечных автоматов»
Формы ввода данных для анализа на основе теории конечных автоматов
представлены на рисунках 4.16 и 4.17.
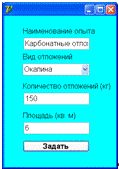
Рисунок 4.16 - Первая форма ввода данных для анализа конечных автоматов
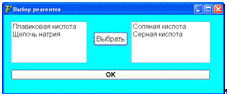
Рисунок 4.17 - Вторая форма ввода данных для анализа конечных автоматов
На второй форме ввода из списка возможных реагентов (слева) для очистки
определенного вида отложений, выбранного на первой форме, выбираются
необходимые, которые заносятся в правый список. Начальные данные на форме
результатов моделирования представлены на рисунке 4.18.
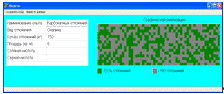
Рисунок 4.18 - Начальные данные результатов моделирования
После нажатия на кнопку «Вывести данные» происходят расчеты, конечные
результаты моделирования представлены на рисунке 4.19.
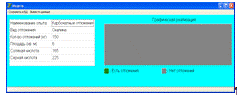
Рисунок 4.19 - Конечные результаты моделирования
Вывод сохраненных данных моделирования на основе теории конечных автоматов виден на рисунке 4.4.
Четвертый пример. Имеются данные количества отложений, представленных на
рисунке 4.20. Необходимо рассчитать количество реагентов для очистки.
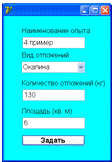
Рисунок 4.20 - Данные отложений
Результаты представлены на рисунках 4.21 и 4.22.

Рисунок 4.21 - Результаты моделирования

Рисунок 4.22 - Результаты моделирования
4.3 Тестирование и оценка надежности системы
Тестирование - метод работы с программным средством, информационной системой с целью выявить в ходе работы ошибки. Одним из видов тестирования является структурное, иначе говорится тестирование «белого ящика», оно определяет оценку сложности системы в комплексе и может использовать эту оценку для нахождения необходимого минимума тестовых вариантов (ТВ). Данные тестовые варианты (ТВ) приведены для поверки основного, базового множества путей путем гарантий, что будет выполняться каждый оператор в тестировании только один раз. Для проведения структурного тестирования необходимо знать внутреннюю структуру системы, поэтому изучаются элементы системы и взаимосвязи между ними. В качестве объекта тестирования будет выступать внутреннее поведение программы и ее реакция. Система будет считаться проверено полно, если проведено исчерпывающее тестирование маршрутов или путей ее графа управления. При проверке используются тестовые варианты, в которых:
1) используется проверка всех независимых путей программы;
2) выполнение всех циклов в пределах их границ и диапазонов;
) проход ветви имеет значение истины или ложи для всех видов логических путей решений;
) проводится анализ правильности структуры данных внутри системы.
В данной системе будем проводить тестирование с помощью тестирования базового пути. Этот способ дает возможность определить оценку сложности системы в комплексе, использующая для оценки нужного количества тестовых вариантов (ТВ). Для показа системы используется потоковый граф.
Ниже представлена процедура программы для расчета коэффициента корреляции для регрессии от одного параметра:
1. xsred:=0;
. ysred:=0;
. for j:=1 to z do
. begin
. xsred:=xsred+x0[j];
. ysred:=ysred+y0[j];
. end;
. xsred:=xsred/z;
. ysred:=ysred/z;
. ch:=0;
. for j:=1 to z do
. begin
. ch:=ch+(x0[j]-xsred)*(y0[j]-ysred);
. end;
. sx0:=0;
. sy0:=0;
. for j:=1 to z do
. begin
. sx0:=sx0+sqr(x0[j]-xsred);
. sy0:=sy0+sqr(y0[j]-ysred);
. end;
. sx0:=sqrt(sx0/(z-1));
. sy0:=sqrt(sy0/(z-1));
. R:=ch/((z-1)*sx0*sy0);
. s:=#13+'Коэффициент корреляции:'+#13+floattostr(R)+#13;
26. RichEdit.Lines.Add(s);
Потоковый граф представлен на рисунке 4.23.
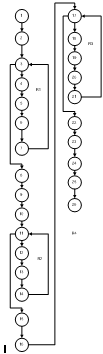
Рисунок 4.23 - Потоковый граф
Для количественной оценки сложности информационно-моделирующей системы будем применять метрику цикломатической сложности. В способе тестирования базового пути эту сложность оценивает количество независимых друг от друга путей в базовом множестве системы, а еще верхнюю оценку количества тестовых вариантов, гарантирующее работу всех операторов только один раз.
Цикломатическая сложность вычисляется тремя способами:
) цикломатическая сложность равна количеству регионов потокового графа
(G)=4,
) цикломатическая сложность вычисляется по формуле:
(G)=E-N+2,
где E - количество дуг графа;- количество узлов графа.
(G)=28-26+2=4,
) цикломатическая сложность вычисляется по формуле:
(G)=р+1,
где р - количество предикатных узлов потокового графа (3, 11, 17).
(G)=3+1=4.
Перечислим независимые пути для потокового графа:
Путь 1: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 15 - 16 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 22 - 23 - 24 - 25 - 26.
Путь 2: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 15 - 16 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 22 - 23 - 24 - 25 - 26.
Путь 3: 1 - 2 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 4 - 5 - 6 - 7 - 3 - 8 - 9 - 10 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 12 - 13 - 14 - 11 - 15 - 16 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 18 - 19 - 20 - 21 - 17 - 22 - 23 - 24 - 25 - 26.
Тестовые варианты представлены ниже.
Первый тестовый вариант:
Исходные данные: массив X=(1, 4, 6), массив Y=(6, 14, 16)
Ожидаемый результат: 0,95.
Второй тестовый вариант:
Исходные данные: массив X=(1, 4, 6, 8), массив Y=(6, 14, 16, 22)