Материал: искусственный интеллект
suai.ru/our-contacts |
quantum machine learning |
156 |
E. Di Buccio and M. Melucci |
|retrieval system = asystem |system + aretrieval |retrieval
is not orthogonal to, yet it is still independent of |information retrieval .
4.2 Themes
Consider a vector space over the real Þeld and the following:2
Definition 8 (Theme) Given m independent term vectors |t1 , . . . , |tm , where 1 ≤ m ≤ k, a theme is represented by the m-dimensional subspace of all vectors like
|τ = b1 |t1 + · · · + bm |tm bi R.
From the deÞnition, one can see that a feature is a term and a term is the simplest form of a theme. In particular, a term is a one-dimensional theme. Moreover, if |t is a term, then any c |t is the same term for all c R.
Moreover, themes can be combined to further deÞne more complex themes; to start with, a theme can be represented by a one-dimensional subspace (i.e., a ray) as follows: if |t represents a term, we have that |τ = b |t spans a one-dimensional subspace (i.e., a ray) and represents a theme. Also, a theme can be represented by a bi-dimensional subspace (i.e., a plane) in the k-dimensional space as follows: if |t1 and |t2 are term vectors, we have that b1 |t1 + b2 |t2 spans a bi-dimensional subspace (i.e., a plane) representing a theme.
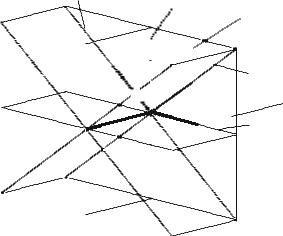
In general, a theme may be represented by multi-dimensional subspaces by using different methods; for example, Òinformation retrieval systemsÓ can be a term represented as a linear combination of three feature vectors (e.g., keywords) or it can be a theme represented by a linear combination of two or more term vectors such as Òinformation retrieval,Ó Òretrieval,Ó Òsystems,Ó Òretrieval systems,Ó or Òinformation.Ó Therefore, the correspondence between themes and subspaces is more complex than the correspondence between keywords and vectors of the VSM. The conceptual relationships between themes are depicted in Fig. 2.
4.3 Document Ranking
A document is represented by a vector
|φ = (c1, . . . , cm) |
ci R |
2Note that we are overloading the symbol |τ to mean both the theme subspace and a vector of that subspace.
suai.ru/our-contacts |
quantum machine learning |
Searching for Information with Meet and Join Operators |
|
|
|
157 |
|||||||||||||||||||
|
|
|
|
|
τ4 |
|
|
|
|
|
|
|
τ3 |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
τ1 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|t4 |
|
|t1 |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|t5 |
|
τ5 |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
τ6 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|t2 |
|
τ2 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|t3 |
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig. 2 A pictorial representation of features, terms, and themes. Three feature vectors |e1 , |e2 , |e3 span a tridimensional vector space, but they are not depicted for the sake of clarity; the reader may suppose that the feature vectors are any triple of independent vectors. Each term vector |t can be spanned by any subset of feature vectors; for example, |t1 = a1,1 |e1 + a1,2 |e2 for some a1,1, a1,2. A theme can be represented by a subspace spanned by term vectors; for example, |t1 and |t2 span a bi-dimensional subspace representing a theme and including all vectors |τ1 = b1,1 |t1 + b1,2 |t2
on the same basis as that which is used for themes and terms such that ci is the measure of the degree to which the document represented by the vector is about term i.
The ranking rule for measuring the degree to which a document is about a theme relies on the theory of abstract vector spaces. To measure this degree, a representation of a document in a vector space and a representation of a theme in the same space are necessary. Document and theme share the same representation, if they are expressed with respect to the same basis of m term vectors. When orthogonality holds, a ranking rule is then the squared projection of |φ on the subspace spanned by a set of m term vectors as explained in [17].
To describe the implementation of the ranking rule, projectors are necessary. To this end, an orthogonal basis of the same subspace can be obtained through linear transformation of the |t Õs. Let {|v1 , . . . , |vm } be such an orthogonal basis, which determines the projector of the subspace as follows:
τ = |v1 v1| + · · · + |vm vm|.
The measure of the degree to which a document is about a theme τ represented by the subspace spanned by the basis vectors |v is the size of the projection of the document vector on the theme subspace, that is,
suai.ru/our-contacts |
quantum machine learning |
158 |
E. Di Buccio and M. Melucci |
tr[τ |φ φ|] = φ| τ |φ , |
(12) |
where tr is the trace operator. After a few passages, the following measure is obtained by leveraging orthogonality [11]:
| v1|φ |2 + · · · + | vm|φ |2. |
(13) |
4.4 Meet and Join Operators
Themes can be created through operators applied to other themes deÞned on a vector space. In this chapter, we introduce two operators called meet and join. Thus, the subspaces that represent a theme can meet or join the subspace of another theme and the result of either operation is a subspace that represents yet another theme.
The intuition behind using meet and join in IR is that in order to signiÞcantly improve retrieval effectiveness, users need a radically different approach to searching a document collection that goes beyond the classical mechanics of an IR system; for example, the distributive law of intersection and union does not remain valid for subspaces equipped with meet and join. Although it is a negative feature of a classical theory, the violation of a property can be a potential advantage of QTL since this violation allows a user who is interacting with a retrieval system to experiment with many more expressions of his information need. First, consider the following deÞnition of join.
Definition 9 (Join) Consider r themes τ1, . . . , τr . Each theme τi corresponds to one subspace spanned by a basis |ti,1 , . . . , |ti,ki , where ki is the dimension of the i-th subspace. The join of r themes can be deÞned by
τ1 · · · τr
and includes the vectors resulting from
b1,1 |t1,1 + · · · + b1,k1 |t1,k1 + · · · + bn,1 |tn,1 + · · · + br,kr |tr,kr .
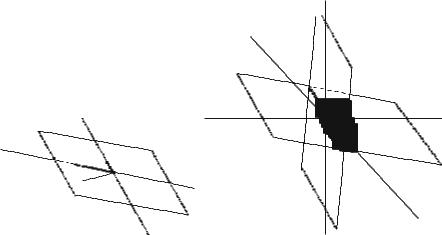
In the event of r = 2, k1 = 1, k2 = 1, two rays are joined, thus resulting in a plane; see Fig. 3a. Note that the join is the smallest subspace containing all the joined subspaces. Then, consider also the following deÞnition of meet.
Definition 10 (Meet) Consider t themes τ1, . . . , τt of dimension k1, . . . , kt . Each theme i corresponds to one subspace spanned by a basis |ti,1 , . . . , |ti,ti . The meet of t themes can be deÞned by
τ1 · · · τt
and includes the vectors resulting from
suai.ru/our-contacts |
quantum machine learning |
Searching for Information with Meet and Join Operators |
159 |



τ3 |
|
τ5 |
|
|τ 2 |
τ4 |
|τ 1 |
|
|
|
|τ |
|
(a) |
(b) |
Fig. 3 Pictorial description of join and meet. (a) Join. (b) Meet
a1 |v1 + · · · + amin k1,kt |vmin k1,kt ,
where the |v Õs are the basis vectors of the largest subspace contained by all subspaces.
In the event that t = 2, k1 = 2, and k2 = 2, the meet may result in one ray, i.e., the intersection between two planes; see Fig. 3b.
In general, the distributive law is violated by themes. For all τ1, τ2, τ3, τ4 we have that
(τ1 τ2) (τ1 τ3) = τ1 (τ2 τ3) ;
therefore,
(τ1 τ2) (τ1 τ3)
calculates one ranking, while
τ1 (τ2 τ3)
might yield another ranking, thus giving the chance that one ranking is more effective than another ranking, that is, the lack of the distributive property gives one further degree of freedom in building new information need representations. The violation of the distributive property is shown as follows: Fig. 2 shows three term vectors, i.e., |t1 , |t2 , and |t3 , spanning a tridimensional vector space; each
suai.ru/our-contacts |
quantum machine learning |
160 |
E. Di Buccio and M. Melucci |
of these term vectors spans a one-dimensional subspace, i.e., a ray. Note that the bi-dimensional subspace, i.e., a plane, spanned by |t1 and |t2 is also spanned by |t4 and |t5 . Following the explanation of [14] and [26, pp. 38Ð39], consider the subspace spanned by
t2 (t4 t5).
As the bi-dimensional subspace spanned by |t1 and |t2 is also spanned by |t4 and |t5 we have that
t2 (t4 t5) = t2 (t1 t2) = t2.
LetÕs distribute meet. We have that
(t2 t5) (t2 t4) =
because
t2 t5 = t2 t4 = .
Therefore ,
t2 = t2 (t4 t5) = (t2 t4) (t2 t5) =
thus meaning that the distributive law does not hold; hence, set operations cannot be applied to subspaces.
5 Implementation of a Query-by-Theme Language
Given m terms, k features, and n documents, a k × n matrix X can be computed such that X[i, j ] is the frequency of feature i in document j ; frequency is only one option, but X may contain other non-negative weights. As X is non-negative, Non-negative Matrix Factorization (NMF) [16] can be performed in such a way to obtain:
X = W H W Rk×m H Rm×n, |
(14) |
where H[h, j ] measures the contribution of theme h to document j . As the themes are unknown, they have to be calculated as follows. The m column vectors of W are regarded as terms, i.e., one-dimensional themes. The theme vectors corresponding to the columns of W are then rescaled as follows:
(|τ1 , . . . , |τm ) = W diag(H 1n),